基于时间的一次性密码(TOTP)的两阶段认证是广泛使用的提高安全性手段。
本文以访问IRIS系统管理门户(System Management Portal)为例,介绍如何在IRIS里配置TOTP提高访问IRIS的安全性。
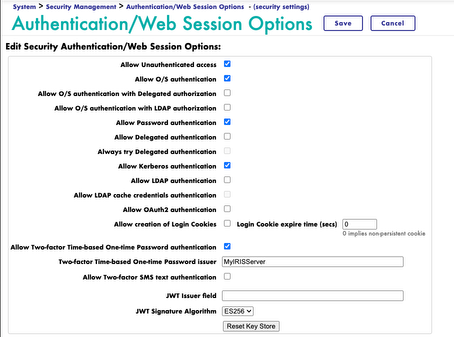
1. 允许TOTP的两阶段认证(2FA)
打开IRIS系统管理门户(SMP),进入系统 > 安全管理 > 身份验证/Web 会话选项 - (安全设置),选中Allow Two-factor Time-based One-time Password authentication,然后在出现的Two-factor Time-based One-time Password issuer 中修改issuer名字,例如MyIRISServer
2. 允许Application使用TOTP的两阶段认证(2FA)
这里以管理门户(SMP)为例,它是一个Web application (/csp/sys)。打开IRIS系统管理门户(SMP),进入系统 > 安全管理 > Web 应用程序 > 编辑 Web 应用程序 - (安全设置) ,点击/csp/sys。然后在安全设置>允许的身份验证方法下选中“基于时间的一次性双重验证密码 ”
3. 配置用户使用TOTP的两阶段认证(2FA)
确定哪些用户使用基于TOTP的2FA,并修改该用户的配置。这里以用户SuperUser为例。
.png)
.png)


.png)
.png)
.png)
.png)
.png)