你好,
smp里面如何添加数据库 只能用command添加吗?没有在portal里看到添加数据库这个功能。
还想请问要把Excel的数据import到IRIS应该用什么方式去操作?
你好,
smp里面如何添加数据库 只能用command添加吗?没有在portal里看到添加数据库这个功能。
还想请问要把Excel的数据import到IRIS应该用什么方式去操作?
可以使用以下任一方法验证索引
$SYSTEM.OBJ.ValidateIndices()验证表的索引,还验证该表的集合子表中的任何索引。%Library.Storage.%ValidateIndices()验证表的索引。集合子表索引必须使用单独的%ValidateIndices()调用进行验证。这两种方法都会检查指定表的一个或多个索引的数据完整性,并可以选择更正发现的任何索引完整性问题。他们分两步执行索引验证:
如果这两种方法中的任何一种发现不一致,它都可以有选择地更正索引结构和/或内容。它可以验证标准索引、位图索引、位图范围索引和位片索引,并可选择对其进行校正。默认情况下,这两种方法都会验证索引,但不会更正索引。
如果满足以下条件,%ValidateIndices()只能用于更正(生成)读写活动系统上的索引:如上所述,使用了SetMapSelecability();参数必须包括和。由于速度明显较慢,因此是在活动系统上构建索引的首选方法。
通常从终端运行。它显示当前设备的输出。此方法可以应用于指定的索引名称,也可以应用于为指定表(类)定义的所有索引。
当数字数据字段用于某些数值运算时,位片索引用于该字段。位片索引将每个数值数据值表示为二进制位串。位片索引不是使用布尔标志来索引数值数据值(如在位图索引中那样),而是以二进制值表示每个值,并为二进制值中的每个数字创建一个位图,以记录哪些行的该二进制数字具有1。这是一种高度专门化的索引类型,可以显著提高以下操作的性能:
SUM、COUNT或AVG Aggregate计算。(位片索引不用于计算。)。位片索引不用于其他聚合函数。WHERE field BETWEEN lownum AND highnum、SQL优化器确定是否应该使用定义的位片索引。通常,优化器仅在处理大量(数千)行时才使用位片索引。
可以为字符串数据字段创建位片索引,但位片索引将这些数据值表示为规范数字。换句话说,任何非数字字符串(如)都将被索引为0。这种类型的位片索引可用于快速计数具有字符串字段值的记录,而不计算那些为空的记录。
在下面的例子中,Salary是位片索引的候选项:
位片索引可用于使用WHERE子句的查询中的聚合计算。如果WHERE子句包含大量记录,则这是最有效的。在下面的示例中,SQL优化器可能会使用Salary上的位片索引(如果已定义);如果定义了位片索引,它还会使用
位图索引是一种特殊类型的索引,它使用一系列位串来表示与给定索引数据值相对应的一组ID值。
位图索引具有以下重要功能:
counting、AND和OR)经过优化以获得高性能。位图索引的创建取决于表的唯一标识字段的性质:
ID,或使用定义自定义值,其中基于类型为且>的单个属性,或类型型且且。受下列限制,位图索引的操作方式与标准索引相同。 索引值将被整理,可以在多个字段的组合上建立索引。
位图索引的工作方式如下。
假设Person表,其中包含一些列:
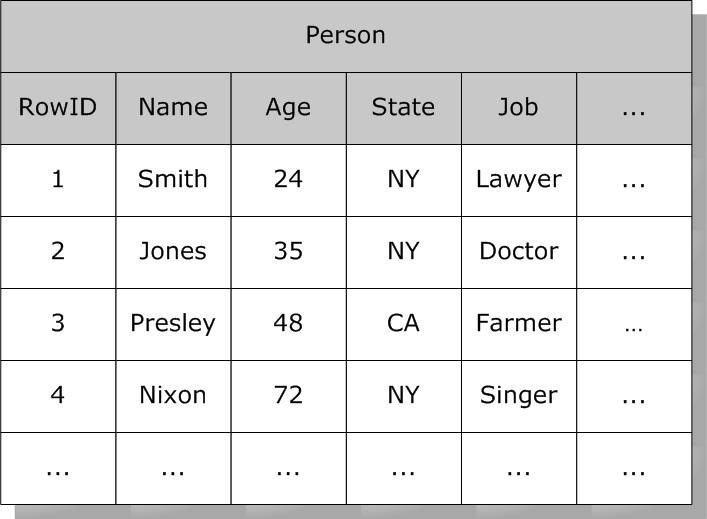
此表中的每一行都有一个系统分配的RowID号(一组递增的整数值)。位图索引使用一组位字符串(包含1和0值的字符串)。在位串中,位的序号位置对应于索引表的RowID。对于给定值,假设State
开发者们现在可以下载一套InterSystems ObjectScript扩展插件,并开始使用微软的Visual Studio Code IDE编写应用程序。我们培训部门的新VS Code资源指南提供了大量开发人员入门需要的内容,包括:
连接到InterSystems实例:安装和使用VS Code的ObjectScript扩展
VS Code开发应用程序文档:
使用开源社区。
播客集: 在VS代码中编写ObjectScript (20m)
开发者社区文章。如何报告问题
Github Repository。InterSystems语言服务器
Github Repository。InterSystems服务器管理器
Github Repository。VS代码的InterSystems ObjectScript扩展
了解IDE。
微软文档。Visual Studio代码 - 入门
微软视频。Visual Studio代码入门 (5m)
更多详情欢迎访问:https://learning.intersystems.com/course/view.php?id=1678&ssoPass=1
圆满结束!
所有的专题会议都已经播出了。当然,我们全部102部预录制的专题会议现在可以点播了,您可以随意观看,即使您错过了现场问答的机会。
说到现场问答,我们已经举办了6次现场会议,您也可以观看。我之前写过一篇单独的博客文章,题目是如何让您的问题会帮助我们做得更好。
智能工厂启动包
今天备受关注的亮点之一是Intersystems IRIS智能工厂启动包在OpenExchange上发布。为此,我们的合作伙伴ITVisors和他们的客户Vlisco与我们的Joe Lichtenberg一起举办了一场精彩的会议“MFG001:介绍适用于制造业的InterSystems IRIS智能工厂启动包”。
容器和Kubernetes平台
今天我们宣布了一个高度安全的新版IRIS容器,名为“iris-lockeddown”,这个容器非常适合在Kubernetes中使用加固型pod安全策略的团队。说到Kubernetes,Steve Lubars演示了我们新的InterSystems Kubernetes Operator,它让您可以很轻松地在Kubernetes 中部署IRIS集群。而Luca Ravazzolo则演示了如何用CPF合并文件配置您的IRIS实例,特别是如何自动化进行镜像配置。还有其他一些有趣的问题。
我们刚刚结束了第二天的专题会议,会议内容精彩纷呈!虽然大家无法同时观看多个平行会议,但是线上会议有一个优势,那就是您可以根据自己的需要回看错过的内容!
在昨天的博客文章(第一天会议亮点)中,我介绍了大部分值得关注的公告,如 InterSystems IRIS Adaptive Analytics 和FHIR加速器服务等。所以,今天我想更宽泛地讨论一些战略主题。
运营和系统管理
现在,越来越多的客户业务已经运行在云端,也有越来越多的人开始在本地部署现代部署策略。Mark Bolinsky今天主持了两场背靠背会议:CL003 云存储策略和CL004 云备份策略,为使用云端生产工作的用户带来了很多技术细节。我们新推出的系统警报和监控(SAM)模块也得到了不错的反馈。相关内容请查看DEV007 系统警报和监控和CL005 分布式部署。另一个另广大开发者兴奋的消息是,集群监控现在可以轻松实现。在此感谢所有参与并提出问题的与会者!
安全性
在安全性方面,InterSystems一直受到客户和分析师的高度好评,不过大多数人会认为这样做是为了保持自身产品的安全。这当然是我们的一个目标,但是我们还添加了许多新的安全特性。今天的SEC000 OCSP装订就是一个典型的例子。虽然OCSP(在线证书状态协议)可提供更强的安全性,但也会影响浏览器性能。使用OCSP装订功能后,服务器会检查X.
IRIS 中支持的四种方式:
SQL、Objects、REST 和 GraphQL
卡济米尔·马列维奇,《运动员》(1932)
>
> “你当然无法理解! 习惯了坐马车旅行的人怎么可能理解乘坐火车或者飞机旅行的人的感受和印象?”
>
> >
> 卡济米尔·马列维奇 (1916)
>
## 引言
我们已经讨论过为什么在主题领域建模使用对象类型优于使用 SQL。 当时得出的结论和总结的事实如今依然适用。 那么,我们为什么要退后到对象和类型之前的时代,讨论将对象的操作拖回到使用global的技术? 我们又为什么要鼓励面条式代码?难道是为了用它难以跟踪的错误考验开发者的技能熟练度?
目前有几种观点支持通过基于 SQL/REST/GraphQL 的 API 传输数据,而不是将其表示为类型/对象:
在讨论实现 API 之前,我们先来看一下底层的抽象层。 下图显示了数据在永久存储位置与处理并向应用程序用户呈现的位置之间的移动方式。
InterSystems IRIS 下使用 DataOps .png)
Gartner 对 DataOps 的定义是:“DataOps 是一种协作式的数据管理方法,侧重于改善整个组织中数据管理者和数据消费者之间数据流的沟通、整合与自动化。 DataOps 的目标是创建可预测的数据、数据模型和相关项目的交付和变更管理,从而更快地交付价值。 DataOps 采取特殊技术手段和相应治理水平自动化数据交付的设计、部署和管理,以元数据提高动态环境中数据的易用性和价值。”
2014 年 6 月 19 日,InformationWeek 特约编辑 Lenny Liebmann 发表于 IBM Big Data & Analytics Hub 的题为“3 reasons why DataOps is essential for big data success”的文章中首次提出 DataOps 这一概念。 DataOps 一词后被 Andy Palmer 推广到 Tamr。 DataOps 是“数据运营”的专属名称。 2017 年对 DataOps 来说是意义重大的一年,生态系统取得巨大发展,分析师覆盖范围进一步扩张,关键字搜索量以及调查、出版物和开源项目数均有所提升。 Gartner 在 2018 年的 Hype Cycle for Data Management 中添加了 DataOps 。
在创建ODBC的SQL网关连接时,需要选择一个系统中已有的DSN才能够正常的连接到数据库去,那如果想要手动的在代码中获取到系统的DSN应该如何进行操作呢,获取到如下图中所示的DSN列表,期待各位的答复,谢谢
.png)
我正在参加 Joel Solon 讲授的“使用 InterSystems Objects 和 SQL 进行开发”课程。 课程非常好,我将在这里分享一些从培训中总结的提示。
第 3 天的提示:
1. 您可以使用 %Dictionary 类查看类目录,并在 INFORMATION_SCHEMA 表中查看 sql 对象。
2. 可以在 ObjectScript 方法中以动态 SQL 或嵌入式 SQL 使用 SQL。
3. 您可以使用 ?(例如:where country = ?)将参数传递到动态 SQL 字符串, 使用冒号(例如:where country = :variable)将参数传递到嵌入式 SQL。
4. 动态 SQL 示例(来自 Intersystems 文档):
SET tStatement = ##class(%SQL.Statement).%New(,"Sample")
SET myquery = 3
SET myquery(1) = "SELECT TOP ? Name,DOB,Home_State"
SET myquery(2) = "FROM Person"
SET myquery(3) = "WHERE Age > 60 AND Age < 65"
SET qStatus = tStatement.%Prepare(.myquery)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
DO tStatement.%Display()
WRITE !,"End of %Prepare display"我正在参加 Joel Solon 讲授的“使用 InterSystems Objects 和 SQL 进行开发”课程。 课程非常好,我将在这里分享一些从培训中总结的提示。
第 4 天的提示:
1. 所有数据都存储在global中,global名称以 ^ 开头。 global示例:^animal。 global可以有多个数据位置(“子数据”)。 示例:^animal("大象","吃草")。
2. 可从任意系统范围(命名空间)访问 ^%* global。
3. global使 IRIS 能够支持多模型数据(对象、关系、文档、多维等)。
4. 要查看global,请转到 Management Portal > Explorer > Globals > Select Global > View,或者在终端中输入 do ^%G 或 zwrite ^global。
5. 在持久类和 SQL 表之间有自动对应关系:
6. 一个表可以对应多个类,但序列类serial是持久类表的一部分(没有特定的表)。
7. 一个类可以对应多个表。
8.
原文在这里
我正在参加 Joel Solon 讲授的“使用 InterSystems Objects 和 SQL 进行开发”课程。 课程非常好,我将在这里分享一些从培训中总结的提示。
第 2 天的提示:
1. 您可以创建持久类(在数据库中具有对应表的类,用于保持类属性)。
2. 持久类示例:
Class dc.Person extends (%Persistent)
{
Property Name As %String;
Property BirthDate As %Date;
}3. 扩展 %Persistent 时,您将获得 %New() 以在内存中创建新实例,获得 %Save() 以保存到数据库,获得 %Id() 以获取该实例在数据库中的唯一 ID,以及获得 %OpenId() 以使用数据库值加载实例。
4. 持久类允许您调用 %Deleteid() 以从数据库中删除一个实例,调用 %DeleteExtent() 以删除所有保存的对象(没有 where 时删除!),调用 %ValidateObject() 以验证保存前传递的数据(验证是否必需、大小等)。
5. 持久类具有 %IsModified() 和 %Reload(),前者用于检查内存中的数据变化(参见评论中 joel 的提示),后者用于获取这些变化。
6.
与典型的SQL一样,InterSystems IRIS支持惟一键和主键的概念。
InterSystems IRIS还能够定义IdKey,它是类实例(表中的行)的唯一记录ID。
这些特性是通过Unique、PrimaryKey和关键字实现的:
Unique -在索引的属性列表中列出的属性上定义一个唯一的约束。
也就是说,只有这个属性(字段)的唯一数据值可以被索引。
唯一性是根据属性的排序来确定的。
例如,如果属性排序是精确的,则字母大小写不同的值是唯一的;
如果属性排序是SQLUPPER,则字母大小写不同的值不是唯一的。
但是,请注意,对于未定义的属性,不会检查索引的惟一性。
根据SQL标准,未定义的属性总是被视为唯一的。PrimaryKey -在索引的属性列表中列出的属性上定义一个主键约束。这些关键字的语法出现在下面的例子中:
Class MyApp.SampleTable Extends %Persistent [DdlAllowed]
{
Property Prop1 As %String;
Property Prop2 As %String;
Property Prop3 As %String;
Index Prop1IDX on Prop1 [ Unique ];
Index Prop2IDX on Prop2 [ PrimaryKey ];
Index Prop3IDX on Prop3 [ IdKey ];
}
什么是分布式人工智能 (DAI)?
试图找到一个“无懈可击”的定义是徒劳的:这个术语似乎有些“超前”。 但是,我们仍然可以从语义上分析该术语本身,推导出分布式人工智能也是人工智能(请参见我们为提出一个“实用”定义所做的努力),只是它分布在多台没有聚合在一起(既不在数据方面,也不通过应用程序聚合,原则上不提供对特定计算机的访问)的计算机上。 即,在理想情况下,分布式人工智能的安排方式是:参与该“分布”的任何计算机都不能直接访问其他计算机的数据和应用程序,唯一的替代方案是通过“透明的”消息传递来传输数据样本和可执行脚本。 与该理想情况的任何偏差都会导致出现“部分分布式人工智能”- 一个示例是通过中央应用程序服务器分发数据, 或者其反向操作。 不管怎样,我们都会得到一组“联合”模型(即,在各自数据源上训练的模型,或者按自己的算法训练的模型,或者同时以这两种方式训练的模型)。
Hi 社区开发者们,告诉大家一个好消息!InterSystems IRIS®数据平台已入驻AWS Quick Start,今后可在AWS上快速部署高可用的生产环境。
索引是由持久类维护的结构,InterSystems IRIS®数据平台可以使用它来优化查询和其他操作。
可以在表中的字段值或类中的相应属性上定义索引。(还可以在多个字段/属性的组合值上定义索引。)。无论是使用SQL字段和表语法还是类属性语法定义相同的索引,都会创建相同的索引。当定义了某些类型的字段(属性)时,InterSystems IRIS会自动定义索引。可以在存储数据或可以可靠派生数据的任何字段上定义附加索引。InterSystems IRIS提供了几种类型的索引。可以为同一字段(属性)定义多个索引,为不同的目的提供不同类型的索引。
无论是使用SQL字段和表语法,还是使用类属性语法,只要对数据库执行数据插入、更新或删除操作,InterSystems IRIS就会填充和维护索引(默认情况下)。可以覆盖此默认值(通过使用%NOINDEX关键字)来快速更改数据,然后作为单独的操作生成或重新生成相应的索引。可以在用数据填充表之前定义索引。还可以为已经填充了数据的表定义索引,然后作为单独的操作填充(构建)索引。
InterSystems IRIS在准备和执行SQL查询时使用可用的索引。默认情况下,它选择使用哪些索引来优化查询性能。 可以根据需要覆盖此默认值,以防止对特定查询或所有查询使用一个或多个索引。
每个索引都有一个唯一的名称。
InterSystems SQL支持几个特性来优化InterSystems IRIS®数据平台的SQL性能。
SQL性能从根本上取决于良好的数据架构。 将数据划分为多个表并在这些表之间建立关系对于高效的SQL是必不可少的。
描述了以下优化表定义的操作。 这些操作要求定义表,但不要求用数据填充表:
%Storage.Persistent、%Storage.SQL或自定义存储来存储数据。USEEXTENTSET参数为数据和索引查找操作指定更短、更高效的散列全局名称。根据对表中典型数据的分析,可以执行以下操作来优化表访问:
BlockCount元数据。查询优化器使用此信息来确定最有效的查询执行计划。IRIS RAD Studio 是一个低代码解决方案,使开发更简单。任何人都可以基于一个简单的类定义乃至一个CSV文件来创建CRUD..
https://openexchange.intersystems.com/package/iris-rad-studio
要从查询结果集中返回特定的值,必须一次一行遍历结果集。
要遍历结果集,请使用%Next()实例方法。
(对于单一值,结果对象中没有行,因此%Next()返回0,而不是错误。)
然后,可以使用%Print()方法显示整个当前行的结果,或者检索当前行的指定列的值。
方法获取查询结果中下一行的数据,并将该数据放入结果集对象的data属性中。
返回1,表示它位于查询结果中的某一行上。
%Next()返回0,表示它位于最后一行(结果集的末尾)之后。
每次调用返回1个增量;
如果游标定位在最后一行之后(返回0),表示结果集中的行数。
如果查询只返回聚合函数,每个设置%ROWCOUNT=1。
第一个返回1并设置和,即使表中没有数据;
任何随后的返回0,并设置和。
从结果集中获取一行后,可以使用以下任何一种方式显示该行的数据:
rset.%Print()返回查询结果集中当前行的所有数据值。rset.%GetRow()和rset.getrows()以编码列表结构的元素形式从查询结果集中返回一行的数据值。实例方法从结果集中检索当前记录。
在InterSystems IRIS®Data Platform Management Portal中,有用于导入和导出数据的工具:
这些工具使用动态SQL,这意味着查询是在运行时准备和执行的。可以导入或导出的行的最大大小为3,641,144个字符。
还可以使用%SQL.Import.Mgr类导入数据,使用%SQL.Export.Mgr类导出数据。
可以将数据从文本文件导入到合适的InterSystems IRIS类中。执行此操作时,系统将在表中为该类创建并保存新行。该类必须已经存在并且必须编译。要将数据导入到此类中,请执行以下操作:
从管理门户中选择系统资源管理器,然后选择SQL。使用页面顶部的切换选项选择一个命名空间;这将显示可用命名空间的列表。
在页面顶部,单击向导下拉列表,然后选择数据导入。
在向导的第一页上,从指定外部文件的位置开始。对于导入文件所在的位置,请单击要使用的服务器的名称。
然后输入文件的完整路径和文件名。
对于选择架构名称,单击要向其中导入数据的InterSystems IRIS包。
对于选择表名,单击将包含新创建的对象的类。
然后单击下一步。
在向导的第二页上,单击将包含导入数据的列。
然后单击下一步。
如果看了前一篇InterSystems IRIS医疗行业版创建FHIR服务器,应该您已经搭建好了FHIR服务器和FHIR资源仓库。除了使用FHIR REST API来操作这个FHIR服务器,您还可以更直观地看看它的价值 - 使用SMART on FHIR应用。这次,基于上次建好的FHIR服务器,我们用10分钟把一个SMART on FHIR运行起来。
SMART是Substitutable Medical Applications and Reusable Technology的缩写,它的目标是创建可以被替换、可以复用的医疗应用,简单说就是希望医疗应用可以像我们的手机应用一样:不喜欢当前的天气应用,那么就换一个。SMART,这个起于2011年的哈佛和波士顿儿童医院的合作项目,在2013年注意到并快速采用了FHIR,成就了今天的SMART on FHIR。
不再需要处理数据持久化、数据模型标准化等问题,SMART on FHIR应用相当的轻量级,因此也容易快速开发。它主要借助FHIR API和OAuth认证,连接到FHIR服务器上操作数据。
InterSystems IRIS,IRIS for Health和IRIS Studio的2020.4版本现已正式发布。
InterSystems IRIS Data Platform 2020.4使开发、部署和管理增强型应用和业务流程变得更加容易,从而弥合了数据和应用孤岛。它具有许多新功能,包括
增强了应用程序和接口开发人员的能力,包括:
增强了数据库和系统管理员的能力,包括:
InterSystems IRIS for Health 2020.4包含了InterSystems IRIS 2020.4的所有增强功能。此外,这个版本还包
关于这些功能的更多细节可以在产品文档中找到:
.png)
2021年4月18日,Caché 系统运维培训线上实操课,此次培训的主题包括, Intersystems Caché 架构,Intersystems Caché 备份与恢复,Intersystems Caché 高可用与数据库镜像,Intersystems Caché 安全,Intersystems Caché 监控和性能采集。 欢迎大家报名参加!

亲爱的开发者们!
现在你可以在InterSystems开发者社区找工作啦!在开发者社区发帖,你可以为自己找一份心仪的工作,也可以为你的公司寻找合适的人才!

那么,具体怎么操作呢?


