JDBC 兼容性状态 **这是一篇 [InterSystems 常见问题解答网站](https://faq.intersystems.co.jp/)文章。
版本 2009.1 及更高版本与 JDBC 4.0 API 兼容。 有关详细信息,请查阅以下文档。 [关于 JDBC 支持](First Look: JDBC and InterSystems Databases - InterSystems IRIS Data Platform 2020.3
)
.png)
InterSystems IRIS for Health™ 是全球第一个也是唯一一个专门为医疗应用程序的快速开发而设计的数据平台,用于管理全世界最重要的数据。它包括强大的开箱即用的功能:事务处理和分析、可扩展的医疗保健数据模型、基于 FHIR 的解决方案开发、对医疗保健互操作性标准的支持等等。所有这些将使开发者能够快速实现价值并构建具有突破性的应用程序。了解更多信息。
JDBC 兼容性状态 **这是一篇 [InterSystems 常见问题解答网站](https://faq.intersystems.co.jp/)文章。
版本 2009.1 及更高版本与 JDBC 4.0 API 兼容。 有关详细信息,请查阅以下文档。 [关于 JDBC 支持](First Look: JDBC and InterSystems Databases - InterSystems IRIS Data Platform 2020.3
)
InterSystems SQL提供了排序规则功能,可用于更改字段的排序规则或显示。
排序规则指定值的排序和比较方式,并且是InterSystems SQL和InterSystemsIRIS®数据平台对象的一部分。有两种基本排序规则:数字和字符串。
null,然后是负数,从最大到最小,零,然后是正数,从最小到最大。这将创建如下序列:–210,–185,–54,–34,-.02、0、1、2、10、17、100、120。null,A,AA,AA,AAA,AAB,AB,B。对于数字,这将创建以下顺序:–.02,–185,–210,–34,–54 ,0、1、10、100、120、17、2。默认的字符串排序规则是SQLUPPER;为每个名称空间设置此默认值。 SQLUPPER排序规则将所有字母都转换为大写(出于排序的目的),并在字符串的开头附加一个空格字符。此转换仅用于整理目的;在InterSystems中,无论所应用的排序规则如何,SQL字符串通常以大写和小写字母显示,并且字符串的长度不包括附加的空格字符。
时间戳记是一个字符串,因此遵循当前的字符串排序规则。但是,由于时间戳是ODBC格式,因此如果指定了前导零,则字符串排序规则与时间顺序相同。
InterSystems SQL允许您在SQL查询中调用类方法。这为扩展SQL语法提供了强大的机制。
若要创建用户定义的函数,请在持久性InterSystems IRIS类中定义一个类方法。该方法必须具有文字(非对象)返回值。这必须是一个类方法,因为在SQL查询中将没有对象实例可以在其上调用实例方法。还必须将其定义为SQL存储过程。
例如,我们可以在MyApp.Person类中定义一个Cube()方法:
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
/// Find the Cube of a number
ClassMethod Cube(val As %Integer) As %Integer [SqlProc]
{
RETURN val * val * val
}
}
可以使用CREATE FUNCTION,CREATE METHOD或CREATE PROCEDURE语句创建SQL函数。
要调用SQL函数,请指定SQL过程的名称。可以在可能指定标量表达式的任何地方以SQL代码调用SQL函数。函数名称可以使用其架构名称进行限定,也可以不限定。不合格的函数名称采用用户提供的模式搜索路径或系统范围内的默认模式名称。函数名称可以是定界标识符。
查询是执行数据检索并生成结果集的语句。查询可以包含以下任意项:
SELECT语句,用于访问指定表或视图中的数据。JOIN语法的SELECT语句,用于访问多个表或视图中的数据。SELECT语句的结果的UNION语句。SELECT语句为封闭的SELECT查询提供单个数据项的子查询。FETCH语句访问多行数据的SELECT语句。SELECT语句从一个或多个表或视图中选择一行或多行数据。下面的示例显示了一个简单的SELECT:
SELECT Name,DOB FROM Sample.Person WHERE Name %STARTSWITH 'A' ORDER BY DOB
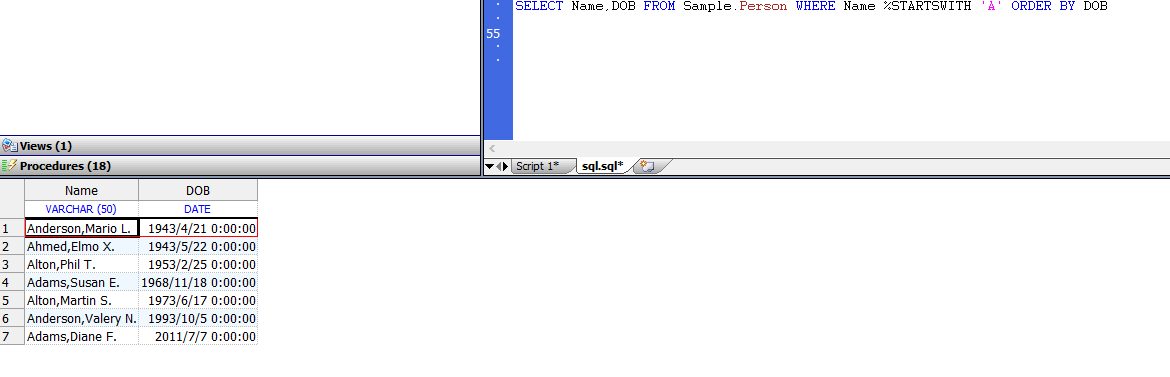
在此的示例Name和DOB是Sample.Person表中的列(数据字段)。
在SELECT语句中必须指定子句的顺序是:SELECT DISTINCT TOP ...选择项INTO ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY。这是命令语法顺序。所有这些子句都是可选的,但SELECT选择项除外。
可以通过注意SELECT语句的语义处理顺序(与SELECT语法顺序不同)来理解
可以对现有的表使用SQL语句,也可以对相应的持久化类使用ObjectScript操作来修改InterSystems IRIS®数据平台数据库的内容。 不能修改定义为只读的持久类(表)。
使用SQL命令为维护数据的完整性提供了自动支持。 SQL命令是一个原子操作(全部或没有)。 如果表上定义了索引,SQL将自动更新它们以反映更改。 如果定义了任何数据或引用完整性约束,SQL将自动执行它们。 如果有任何已定义的触发器,执行这些操作将拉动相应的触发器。
可以使用SQL语句或设置和保存持久化类属性将数据插入表中。
INSERT语句将一条新记录插入SQL表中。
可以插入一条记录或多条记录。
下面的示例插入一条记录。 它是插入单个记录的几种可用语法形式之一:
INSERT INTO MyApp.Person
(Name,HairColor)
VALUES ('Fred Rogers','Black')
以下示例通过查询现有表中的数据插入多条记录:
INSERT INTO MyApp.Person
(Name,HairColor)
SELECT Name,Haircolor FROM Sample.Person WHERE Haircolor IS NOT NULL
还可以发出INSERT或UPDATE语句。
要在表之间强制执行引用完整性,可以定义外键。修改包含外键约束的表时,将检查外键约束。
有几种方法可以在InterSystems SQL中定义外键:
CREATE TABLE或ALTER TABLE命令添加外键。可以使用ALTER TABLE命令删除外键。用作外键引用的RowID字段必须是公共的。引用隐藏的RowID?有关如何使用公用(或专用)RowID字段定义表的信息。
一个表(类)的外键最大数目为400。
外键约束可以指定更新或删除时的引用操作。
在CREATE TABLE reference action子句中描述了使用DDL定义这个引用操作。
在类定义引用的OnDelete和OnUpdate外键关键字中定义了一个持久化类来定义这个引用操作,该类投射到一个表。
在创建分片表时,这些引用操作必须设置为无操作。
默认情况下,InterSystemsIRIS®数据平台对INSERT,UPDATE和DELETE操作执行外键引用完整性检查。如果该操作将违反参照完整性,则不会执行;该操作将发出SQLCODE -121,-122,-123或-124错误。
视图是一种虚拟表,由执行时通过SELECT语句或几个SELECT语句的UNION从一个或多个物理表中检索到的数据组成。 SELECT可以通过指定表或其他视图的任意组合来访问数据。因此,存储了视图的视图提供了物理表的所有灵活性和安全性特权。
InterSystemsIRIS®数据平台上的InterSystems SQL支持在视图上定义和执行查询的功能。
注意:不能对以只读方式安装的数据库中存储的数据创建视图。
无法在通过ODBC或JDBC网关连接链接的Informix表中存储的数据上创建视图。这是因为InterSystems IRIS查询转换对这种类型的查询使用FROM子句中的子查询。 Informix不支持FROM子句子查询。
可以通过几种方式定义视图:
CREATE VIEW命令(在DDL脚本中或通过JDBC或ODBC)。视图名称:不合格的视图名称是一个简单的标识符:MyView。合格的视图名称由两个简单的标识符组成,即模式名称和视图名称,以句点分隔:MySchema.MyView。视图名称和表名称遵循相同的命名约定,并对不合格的名称执行相同的架构名称解析。同一模式中的视图和表不能具有相同的名称。
可以使用$SYSTEM.SQL.ViewExists()方法确定视图名称是否已存在。
支持HL7 转FHIR,CDA 转FHIR,FHIR转HL7的云服务
可以使用标准DDL命令在InterSystems SQL中定义表:
InterSystems SQL中可用的DDL命令
ALTER命令 ALTER TABLE,ALTER VIEWCREATE 命令 CREATE TABLE,CREATE VIEW,CREATE INDEX,CREATE TRIGGERDROP 命令 DROP TABLE,DROP VIEW,DROP INDEX,DROP TRIGGER可以通过多种方式执行DDL命令,包括:
在ObjectScript方法或例程中,可以使用嵌入式SQL来调用DDL命令。
例如,以下方法创建一个Sample.Employee表:
/// d ##class(PHA.TEST.SQL).CreateTable()
ClassMethod CreateTable() As %String
{
&sql(CREATE TABLE Sample.InterSystems IRIS提供了两种方法来唯一标识表中的行:RowID和主键。
可选的主键是一个有意义的值,应用程序可以使用该值唯一地标识表中的行(例如,联接中的行)。主键可以是用户指定的数据字段,也可以是多个数据字段的组合。主键值必须是唯一的,但不必是整数值。 RowID是一个内部用于标识表中行的整数值。通常,主键是由应用程序生成的值,而RowID是由InterSystems IRIS生成的唯一整数值。
系统会自动创建一个主map,以使用RowID字段访问数据行。如果定义主键字段,系统将自动创建并维护主键索引。
显然,具有两个不同的字段和索引来标识行的双重性不一定是一件好事。可以通过以下两种方式之一解析为单个行标识符和索引:
IDKEY。
可以通过使用关键字PrimaryKey和IdKey在类定义中标识主键索引来实现这一点(如果为此目的设置了PKey is IdKey标志,也可以在DDL中实现这一点)。
这使得主键索引成为表的主映射。
因此,主键将被用作行的主要内部地址。
如果主键包含多个字段,或者主键值不是整数,那么这种方法的效率会较低。RowID整数作为应用程序使用的主键(例如,在joins中)。可以通过定义表(使用CREATE TABLE)或通过定义投影到表的持久类来创建表:
由于以下原因,这两个名字之间的对应关系可能不相同:
SqlTableName类关键字来提供不同的SQL表名。SQLUser;
初始默认包名为“User”。表、视图或存储过程名称可以是限定的(schema.name),也可以是限定的(name)。
InterSystems SQL支持以下算术运算符:
+ 加法操作符。
例如,17+7 = 24。
– 减法运算符。
例如,17-7等于10。
注意,这些字符中的一对是InterSystems SQL注释指示器。
因此,要指定两个或多个减法操作符或负号,必须使用空格或圆括号。
例如,17- -7或17-(-7)等于24。
| 运算符 | 描述 |
|---|---|
+ |
加法操作符。 |
– |
减法运算符。例如,17-7等于10。注意,这些字符中的一对是InterSystems SQL注释指示器。因此,要指定两个或多个减法操作符或负号,必须使用空格或圆括号。 |
* |
乘法运算符。例如,17*7等于119。 |
/ |
除法操作符。例如:17/7 = 2.428571428571428571。 |
\ |
整数除法运算符。例如,17\7等于2。 |
# |
模运算符。例如,17 #7等于3。注意,因为#字符也是一个有效的标识符字符,要将它用作模运算符,应该指定它与操作数之间用前后空格分隔 |
E |
求幂(科学记数法)运算符。可以是大写或小写。例如:7E3 = 7000。指数过大会导致SQLCODE -7“指数超出范围”错误。例如1E309、7E308。 |
() |
分组操作符。用于嵌套算术运算。 |
InterSystems SQL提供对InterSystems IRIS®Data Platform数据库中存储的数据的无懈可击的标准关系访问。
InterSystems SQL提供以下优势:
提供例程信息。
^$|nspace|ROUTINE(routine_name)
^$|nspace|R(routine_name)
|nspace|或[nspace] 可选-扩展SSVN引用,可以是显式名称空间名称,也可以是隐含名称空间。必须计算为带引号的字符串,该字符串括在方括号([“nspace”])或竖线(|“nspace”|)中。命名空间名称不区分大小写;它们以大写字母存储和显示。可以将^$ROUTINE结构化系统变量用作$DATA、$ORDER和$QUERY函数的参数,以从当前命名空间(默认)或指定命名空间返回例程信息。^$ROUTINE返回有关例程的OBJ代码版本的例程信息。
在InterSystems ObjectScript中,一个例程有三个代码版本:MAC(用户编写的代码,可能包括宏预处理器语句)、INT(编译的MAC代码,用于执行宏预处理)和OBJ(可执行目标代码)。可以使用^$ROUTINE global返回关于int代码版本的信息。可以使用^$ROUTINE返回有关OBJ代码版本的信息。
此可选参数允许使用扩展SSVN引用在另一个命名空间中指定全局。
标识符是SQL实体的名称,例如表、视图、列(字段)、模式、表别名、列别名、索引、存储过程、触发器或其他SQL实体。 标识符名称在其上下文中必须是唯一的; 例如,同一模式中的两个表或同一表中的两个字段不能具有相同的名称。 但是,不同模式中的两个表或不同表中的两个字段可以具有相同的名称。 在大多数情况下,相同的标识符名称可以用于不同类型的SQL实体; 例如,一个模式、该模式中的表以及该表中的字段都可以具有相同的名称,而不会产生冲突。 但是,同一个模式中的表和视图不能具有相同的名称。
InterSystems IRIS®数据平台SQL标识符遵循一组命名约定,根据标识符的使用,这可能会受到进一步的限制。 标识符不区分大小写。
标识符可以是简单标识符,也可以是分隔符。 InterSystems SQL默认支持简单标识符和分隔标识符。
简单标识符有以下语法:
simple-identifier ::= identifier-start { identifier-part }
identifier-start ::= letter | % | _
identifier-part ::= letter | number | _ | @ | # | $
标识符start是SQL标识符的第一个字符。
它必须是下列之一:
本章概述了InterSystems SQL的特性,特别是那些SQL标准未涵盖的特性,或者与InterSystems IRIS®数据平台统一数据架构相关的特性。 本教程假定读者具备SQL知识,并不是为介绍SQL概念或语法而设计的。
本章讨论以下主题:
在InterSystems SQL中,数据显示在表中。每个表都包含许多列。一个表可以包含零个或多个数据值行。以下术语大体上等效:
| 数据术语 | 关系数据库术语 | InterSystems IRIS术语 |
|---|---|---|
| 数据库 | 架构 | 包 |
| 数据库 | 表 | persistent class(持久类) |
| 字段 | 列 | 属性 |
| 记录 | 行 |
表有两种基本类型:基表(包含数据,通常简称为表)和视图(基于一个或多个表提供逻辑视图)。
SQL模式提供了一种将相关表,视图,存储过程和缓存查询的集合进行分组的方法。模式的使用有助于防止表级别的命名冲突,因为表,视图或存储过程的名称在其模式内必须唯一。应用程序可以在多个架构中指定表。
SQL模式与持久性类包相对应。通常,模式与其相应的程序包具有相同的名称,但是由于不同的模式命名约定或故意指定了不同的名称,因此这些名称可能有所不同。模式到程序包的映射在SQL到类名的转换中有进一步描述。
InterSystems SQL命令(也称为SQL语句)以关键字开头,后跟一个或多个参数。其中一些参数可能是子句或函数,由它们自己的关键字标识。
;)终止。否则,InterSystems SQL命令不需要或接受分号命令终止符。在InterSystems SQL中指定分号命令终止符会导致SQLCODE -25错误。 TSQL的InterSystemsIRIS®数据平台实现(Transact-SQL)接受但不需要分号命令终止符。在将SQL代码导入Inter Systems SQL时,会去除分号命令终止符。InterSystems SQL关键字包括命令名称,函数名称,谓词条件名称,数据类型名称,字段约束,优化选项和特殊变量。
提供锁名信息。
^$|nspace|LOCK(lock_name,info_type,pid)
^$|nspace|L(lock_name,info_type,pid)
|nspace|或[nspace] [nspace]可选-扩展SSVN引用,显式名称空间名称或隐含名称空间。必须计算为带引号的字符串,该字符串括在方括号([“nspace”])或竖线(|“nspace”|)中。命名空间名称不区分大小写;它们以大写字母存储和显示。lock_name的哪种类型的信息。可用选项有“所有者”、“标志”、“模式”和“计数”。作为独立函数调用^$LOCK时需要。pid对其他info_type关键字没有影响。^$LOCK结构化系统变量返回有关当前命名空间或本地系统上指定命名空间中的锁的信息。
大家好!
InterSystems IRIS 有一个名为 Interoperability(互操作性)的菜单。
它提供了轻松创建系统集成(适配器、记录映射、BPM、数据转换等)的机制,因此可以轻松连接不同的系统。
数据中继过程中可以包括各种操作,例如:为了连接没有正常连接的系统,可以根据目标系统的规范来接收(或发送)数据。 此外,在发送数据之前,可以从其他系统获取和添加信息。 还可以从数据库(IRIS 等)获取和更新信息。
在本系列文章中,我们将讨论以下主题,同时查看 示例代码 以帮助您了解工作原理以及在系统中集成互操作性时需要进行哪种开发。
首先,我介绍一下我们将在本系列文章中使用的案例研究。
某公司运营着一个购物网站,他们正在更改产品信息的显示顺序以配合季节变化。
但是,有些商品无论季节如何都能卖得很好,而有些商品在意料之外的时间卖出,这不符合当前的显示顺序更改规则,
因此,我们研究了按照当天的温度而不是季节来更改显示顺序的可能性。 调查购买产品时的温度变得非常必要。
由于可以使用外部 Web API 来查询天气信息,因此我们计划收集购买时的天气信息,并将其记录在后面的审核数据库中。
案例非常简单,但您需要使用“外部 Web API”来收集信息,并且需要将获得的信息和购买信息结合起来记录在数据库中。
InterSystems IRIS 元素周期表

PDF 版本:
GIT 源:
InterSystems IRIS 是一个具有许多功能的数据平台。 这些功能和相关的 IRIS 主题都体现在元素周期表中。
最近完成了针对IRIS医疗版2020.1版本的性能及可扩展性基准测试,重点关注HL7v2的互操作性。本文介绍了在各种工作负载下观察到的吞吐量,并提供了IRIS医疗版用作HL7v2消息传输互操作性引擎时的系统常规配置和调整准则。
基准测试模拟了与实际环境接近的工作负载(详细信息请参见“工作负载说明和方法”部分)。本次测试的工作负载包括HL7v2患者管理(ADT)和生命体征结果(ORU)数据,并包含数据内容转换和路由。
IRIS医疗版2020.1版本可以表明,采用第二代Intel®Xeon®可扩展处理器和Intel®Optane™SSD DC P4800X系列SSD存储的商用服务器,每天的持续消息吞吐量超过23亿条(入站和出站总量),与此前的Ensemble 2017.1 HL7v2吞吐量基准测试相比,扩展性提高了一倍多。
.jpeg)
不少客户问我关于从Cache迁移到IRIS的问题。为什么要迁移到IRIS?Cache是优秀的,稳定的,有很好的性能,为什么要迁移到IRIS呢?这些客户是对的,但在过去几年,数字化转型提出了不少新问题、新需求和新挑战,客户需要更灵活、更完整、更前瞻的解决方案,InterSystems公司很有远见地洞察到了这一点,推出了IRIS。
一句话,IRIS是一套数据平台解决方案,它帮助客户和合作伙伴为迎接数字化转型的挑战提供了充足的弹药。
提供系统间IRIS进程(JOB)信息。
^$JOB(job_number)
^$J(job_number)
job_number 输入ObjectScript命令时创建的系统特定OBJ编号。每个活动的InterSystems IRIS进程都有一个唯一的作业号。登录到系统会启动一个作业。在UNIX®系统上,作业号是调用InterSystems IRIS时启动的子进程的PID。JOB_NUMBER必须指定为整数;不支持十六进制值。可以将^$JOB结构化系统变量用作$DATA、$ORDER和$QUERY函数的参数,以获取有关本地InterSystems IRIS系统上是否存在InterSystems IRIS作业的信息。
以下示例显示如何将^$JOB用作$DATA、$ORDER和$QUERY函数的参数。
$DATA(^$JOB(job_number))
^$JOB作为$DATA的参数返回一个整数值,该值指示指定的作业是否作为节点存在于^$JOB中。下表显示了$DATA可以返回的整数值。
| Value | Meaning |
|---|---|
| 0 | JOB不存在 |
| 1 | JOB存在 |
以下示例测试系统间IRIS进程是否存在。
DHC-APP>SET x=$JOB
DHC-APP>WRITE !提供有关全局变量和进程私有全局变量的信息。
^$|nspace|GLOBAL(global_name)
^$|nspace|G(global_name)
^$||GLOBAL(global_name)
^$||G(global_name)
|nspace| 或 [nspace] - 可选-扩展SSVN引用,可以是显式名称空间名称,也可以是隐含名称空间。必须计算为带引号的字符串,该字符串括在方括号([“nspace”])或竖线(|“nspace”|)中。命名空间名称不区分大小写;它们以大写字母存储和显示。^$||global()语法时,与进程专用全局名称相对应的无下标全局名称:^a表示^||a。可以将^$GLOBAL用作$DATA、$ORDER和$QUERY函数的参数,以返回有关当前名称空间(默认名称空间)或指定名称空间中是否存在全局变量的信息。还可以使用^$global返回有关存在进程私有全局变量的信息。
可以使用^$global获取有关所有命名空间中是否存在进程私有全局变量的信息。可以将进程专用全局的查找指定为^$||global或^$|“^”|global。
包含一个字符串,描述do命令后面的InterSystems IRIS.line的当前版本。
$ZVERSION
$ZV
$ZVERSION包含一个字符串,该字符串显示当前运行的InterSystems IRIS®Data Platform实例的版本。
以下示例返回$ZVERSION字符串:
DHC-APP>WRITE $ZVERSION
Cache for Windows (x86-64) 2016.2 (Build 736U) Fri Sep 30 2016 11:46:02 EDT
此字符串包括InterSystems IRIS安装的类型(产品和平台,包括CPU类型)、版本号(2018.1)、该版本中的内部版本号(内部版本号中的“U”表示UNICODE以及创建此版本的InterSystems IRIS的日期和时间。“EST”是东部标准时间(美国东部的时区),“EDT”是东部夏令时
通过调用GetVersion()类方法可以返回相同的信息,如下所示:
DHC-APP>WRITE $SYSTEM.Version.GetVersion()
Cache for Windows (x86-64) 2016.2 (Build 736U) Fri Sep 30 2016 11:46:02 EDT
以通过调用其他%SYSTEM.
包含当前错误陷阱处理程序的名称。
$ZTRAP
$ZT
$ZTRAP包含当前错误陷阱处理程序的行标签名和/或例程名。有三种方法可以设置$ZTRAP:
SET $ZTRAP=“location”SET $ZTRAP=“*location”SET $ZTRAP=“^%ET” or “^%ETN”在这里,位置可以指定为标签(当前例程中的行标签)、^routine(指定外部例程的开始)或label^routine(指定外部例程中的指定标签)。
然而,$ZTRAP=label^routine不能用于程序块。过程块中的$ZTRAP不能用于转到过程体之外的位置;过程块中的$ZTRAP只能引用该过程块中的一个位置。
使用设置命令,可以将位置指定为带引号的字符串。
^routine(指定外部例程的开始)或label^routine(指定外部例程中的指定标签)。不要在引用过程或过程中的标签的例程中指定位置。这是一个无效位置;当InterSystems IRIS试图执行$ZTRAP时,会导致运行时错误。$ZTRAP不能用于转到过程体之外的位置;过程块中的$ZTRAP只能引用该过程块中的一个位置。包含格林威治子午线的时区偏移量。
$ZTIMEZONE
$ZTZ
$ZTIMEZONE可以通过两种方式使用:
$ZTIMEZONE包含从格林威治子午线偏移的时区(以分钟为单位)。 (格林威治子午线包括整个英国和爱尔兰。)此偏移量表示为-1440到1440范围内的有符号整数。格林威治以西的时区指定为正数;格林威治东部的时区指定为负数。 (时区必须以分钟为单位,因为并非所有时区都以小时为单位。)默认情况下,$ZTIMEZONE初始化为计算机操作系统设置的时区。
注意:$ZTIMEZONE将本地时间调整为固定的偏移量。它不适应夏令时或其他当地时间的变化。 InterSystems IRIS从基础操作系统获取本地时间,该操作系统将本地时间变体应用于为该计算机配置的位置。因此,使用$ZTIMEZONE调整的本地时间将从配置的语言环境中获取其本地时间变化,而不是在$ZTIMEZONE中指定的时区。
使用格林威治子午线($ZTIMEZONE = 0)的时区计数来计算UTC时间。它与当地格林威治时间不同。格林威治标准时间(GMT)一词可能令人困惑;格林威治的当地时间与冬季的UTC相同。在夏季,它与UTC的差异为一小时。这是因为应用了称为英国夏令时的本地时间变体。
包含协调世界时间格式的当前日期和时间。
$ZTIMESTAMP
$ZTS
$ZTIMESTAMP包含协调的通用时间值形式的当前日期和时间。这是世界范围内的时间和日期标准;此值很可能与当地的时间(和日期)值不同。
$ZTIMESTAMP将日期和时间表示为以下格式的字符串:
ddddd,sssss.fff
其中ddddd是一个整数,指定自1840年12月31日起的天数;sssss是一个整数,指定自当天午夜以来的秒数,fff是一个可变的数字,指定小数秒。这种格式类似于$HOROLOG,只是$HOROLOG不包含分数秒。
假设当前日期和时间(世界协调时)如下:
2018-02-22 15:17:27.984
当时,$ZTIMESTAMP的值为:
64701,55047.984
$ZTIMESTAMP报告协调世界时(UTC),它独立于时区。因此,$ZTIMESTAMP提供了一个跨时区的统一时间戳。这可能不同于本地时间值和本地日期值。
$ZTIMESTAMP时间值是一个十进制数值,以秒及其分数为单位计算时间。分数秒的位数可能从零到九不等,具体取决于计算机时钟的精度。在视窗系统上,小数精度是三位小数;在UNIX系统上,它是六位十进制数字。$ZTIMESTAMP在此小数部分中抑制尾随零或尾随小数点。请注意,在午夜后的第一秒内,秒表示为0.
包含进程的最大可用内存。
$ZSTORAGE
$ZS
$ZSTORAGE包含JOB的进程私有内存的最大内存量(以KB为单位)。此内存可用于局部变量、堆栈和其他表。此内存限制不包括例程目标代码的空间。此内存根据需要分配给进程,例如在分配数组时。
一旦将此内存分配给进程,通常在该进程退出之前不会释放它。但是,当大量内存被使用(例如,大于32MB)然后被释放时,系统间IRIS会尝试在可能的情况下将释放的内存释放回操作系统。
还可以使用$ZSTORAGE设置最大内存大小。例如,以下语句将作业的最大进程专用内存设置为524288 KB:
SET $ZSTORAGE=524288
更改$ZSTORAGE会更改$STORAGE特殊变量的初始值,该变量包含进程的当前可用内存(以字节为单位)。
$ZSTORAGE的最大值为2147483647。$ZSTORAGE默认值为262144。$ZSTORAGE的最小值为128。$ZSTORAGE值大于最大值或小于最小值会自动默认为最大值或最小值。$ZSTORAGE设置为整数值;InterSystems IRIS截断任何小数部分(如果指定)。
可以通过更改最大每进程内存(KB)系统配置设置来更改$ZSTORAGE默认值。