📘新书发布|《IRIS(数据平台)编程技术指南》正式发售!
大家好,我是姚鑫。
最近一段时间,我把自己过去几年在 InterSystems IRIS 项目中的开发经验,系统整理成了一本书—— 📕 《IRIS(数据平台)编程技术指南》 现已由 北京航空航天大学出版社 正式出版发行。
说实话,写书的过程比我想象中要难很多。 如果说写博客是“随手记录”,那么写书就是一次真正的“工程项目”:要保证结构完整、逻辑严谨、内容能从入门一路带到实战。
🚀这本书写了什么?
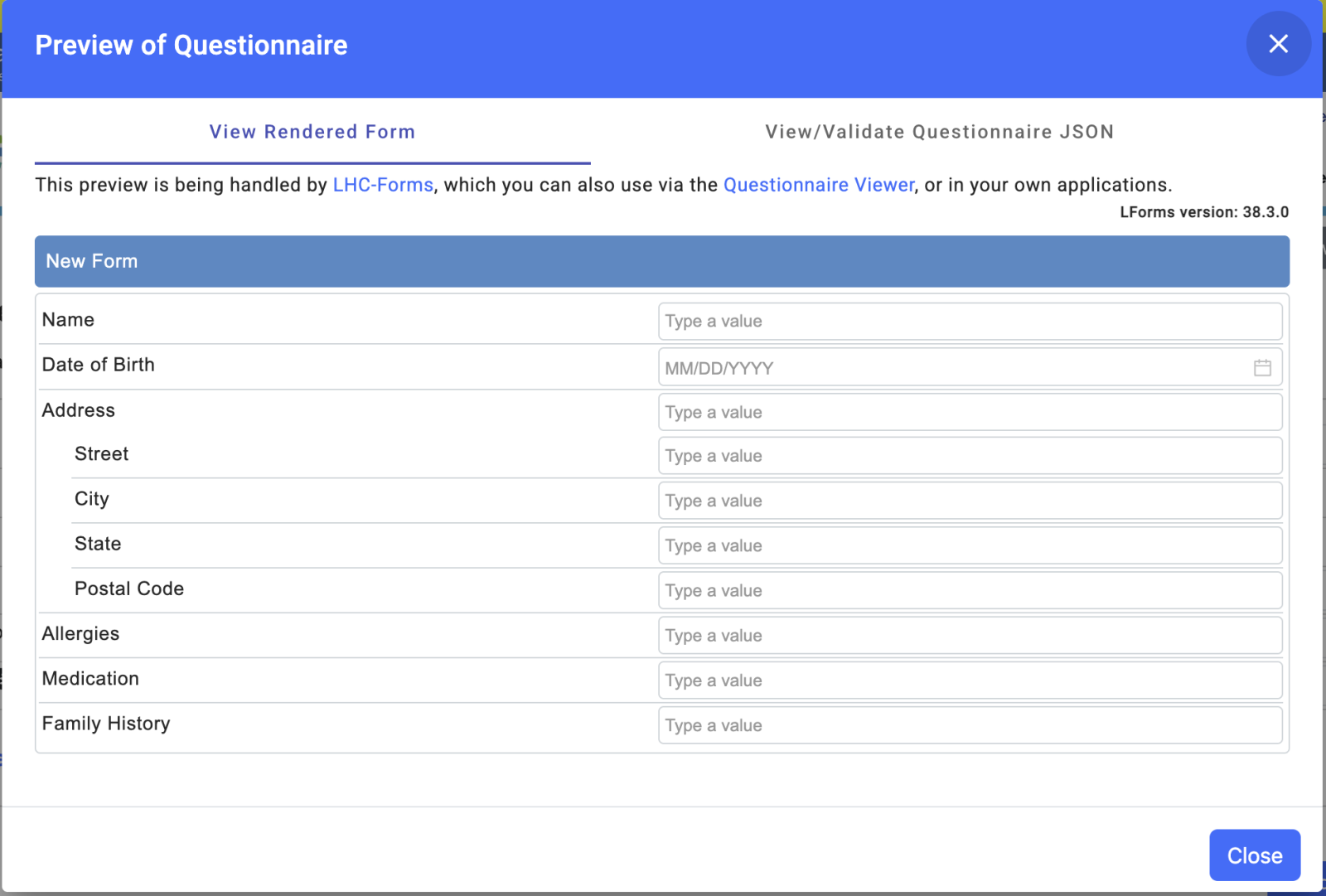
本书围绕 InterSystems IRIS 的核心开发语言 ObjectScript 展开,内容不仅讲语法,更注重“工程实践”。
主要包括:
✅ IRIS 平台介绍与开发环境搭建 ✅ ObjectScript 语法规则、变量体系、全局变量机制 ✅ 常用数据类型、表达式、系统命令、系统函数 ✅ 函数与方法、面向对象编程基础 ✅ %Persistent 持久类(ORM 与 SQL 映射) ✅ Storage 存储策略、懒加载机制、并发分析 ✅ 嵌入式数据结构、常见性能问题与技术难点解析
整体内容更偏向“项目实战型”,不是纯概念堆砌。
.png)

.png)