.png)
12月25日-26日,首届全国医疗健康信息互联互通与智慧医院建设大会即将拉开帷幕!本次会议以“互联互通——通向智慧医院的桥梁”为主题,将采用线上形式召开。
会议分为两大部分(点击“阅读原文”查看全部日程及报名方式)
12月25日-26日,首届全国医疗健康信息互联互通与智慧医院建设大会即将拉开帷幕!本次会议以“互联互通——通向智慧医院的桥梁”为主题,将采用线上形式召开。
会议分为两大部分(点击“阅读原文”查看全部日程及报名方式)
返回指定列值的平均值的聚合函数。
AVG([ALL | DISTINCT [BY(col-list)]] expression [%FOREACH(col-list)] [%AFTERHAVING])
ALL - 可选-指定AVG返回表达式所有值的平均值。
如果没有指定关键字,则为默认值。DISTINCT - 可选 - DISTINCT子句,指定AVG只计算一个值的唯一实例的平均值。
DISTINCT可以指定BY(col-list)子句,其中col-list可以是单个字段,也可以是逗号分隔的字段列表。expression - 任何有效的表达式。
通常是包含要取平均值的数据值的列的名称。%FOREACH(col-list) - 可选—列名或以逗号分隔的列名列表。%AFTERHAVING - 可选 - 应用在HAVING子句中找到的条件。AVG返回NUMERIC或DOUBLE数据类型。
如果expression是DOUBLE类型,AVG返回DOUBLE;
否则,它返回NUMERIC。
AVG聚合函数返回表达式值的平均值。
通常,表达式是查询返回的多行中字段的名称(或包含一个或多个字段名称的表达式)。
AVG可以用于引用表或视图的SELECT查询或子查询。
AVG可以出现在SELECT列表或HAVING子句中,与普通字段值一起出现。
IRIS 2019.4 预览版中发布了/api/monitor服务,以Prometheus格式展示IRIS指标,但没有正式公布。对于任何想要使用IRIS指标作为其监控和警报解决方案的一部分的人来说,这是一个大新闻。该API是新的IRIS 系统警报和监控(SAM)解决方案的一个组成部分,将在IRIS的一个即将到来的版本中发布。
然而,你不必等待SAM开始规划和试用这个API来监控你的IRIS实例。在未来的文章中,我将深入挖掘可用的指标和它们的含义,并提供交互式仪表盘的例子。但首先,让我从一些背景和一些问题和答案开始。
IRIS(和Caché)总是在收集关于它自己和它所运行的平台的几十个指标。一直以来都有多种收集这些指标的方法来监控Caché和IRIS。我发现,很少有安装使用IRIS和Caché内置的解决方案。例如,History Monitor仪表盘作为性能和系统使用指标的历史数据库已经存在很长时间了。然而,没有明显的方法来展现这些指标,并实时监测系统。
IRIS平台的解决方案正在从运行在几个企业内部的实例上的单体应用程序,转向分布式解决方案部署在 "任何地方"。对于许多用例,现有的IRIS监控选项并不适合这些新的模式。InterSystems没有使用陈旧的方法,而是寻找当前流行的、经过验证的开源解决方案进行监控和警报。
技术概要(First Look)是为用户提供InterSystems IRIS的关键技术和选项的实践经验的简短文档,其中涉及到的许多技术都可以在免费的评估实例上体验。所有这些技术都可以在已授权的InterSystems IRIS实例上完成。
技术概要:InterSystems 云管理器(First Look: InterSystems Cloud Manager)
介绍InterSystems 云管理器,为您展示如何利用它在公有云上部署InterSystems产品。
技术概要: 容器中的InterSystems 产品(First Look: InterSystems Products in Containers)
介绍Docker容器和在容器中运行InterSystems产品。
InterSystems IRIS 基础:安装(InterSystems IRIS Basics: Installation
指导用户完成InterSystems IRIS的单实例安装,以便与其它技术概要(First Looks)一起使用。
技术概要:使用InterSystems分布式缓存扩展系统的用户容量
介绍了使用由ECP支持的分布式缓存来扩展用户容量。
计算列的所有值并返回单个聚合值的函数。
聚合函数执行与单个列中的一个或多个值相关的任务,并返回单个值。 支持的功能有:
SUM - 返回指定列的值的和。AVG - 返回指定列值的平均值。COUNT - 返回表中的行数,或指定列中非空值的个数。MAX - 返回指定列中使用的最大值。MIN - 返回指定列中使用的最小值。VARIANCE,VAR_SAMP, VAR_POP - 返回指定列的值的统计方差。STDDEV, STDDEV_SAMP, STDDEV_POP - 返回指定列值的统计标准偏差。LIST - 以逗号分隔的列表形式返回指定列中使用的所有值。%DLIST - 返回指定列中使用的所有值,作为 IRIS列表结构中的元素。XMLAGG - 将指定列中使用的所有值作为连接字符串返回。JSON_ARRAYAGG - 返回指定列中使用的所有值作为JSON格式数组。可以使用CREATE aggregate命令定义其他用户定义的聚合函数。
聚合函数忽略为NULL的字段。
例如,LIST和%DLIST不包含指定字段为NULL的行的元素。
COUNT只计算指定字段的非空值。
聚合函数(COUNT除外)不能应用于流字段。
这样做会产生一个SQLCODE -37错误。
可以使用COUNT来计数流字段值,但有一些限制。
注意:聚合函数类似于窗口函数。
在大多数情况下,%STARTSWITH将前导空格视为与任何其他字符相同的字符。
例如,%STARTSWITH ' B'可用于选择只有一个前导空白后跟字母B的字段值。然而,只包含空白的子字符串不能选择前导空白;
它选择非空值。
尾随空格的%STARTSWITH行为取决于数据类型和排序规则类型。
%STARTSWITH忽略定义为SQLUPPER的字符串子串的尾随空格。
%STARTSWITH不会忽略数字、日期或列表子字符串中的尾随空格。
在下面的示例中,%STARTSWITH将结果集限制为以“M”开头的名称。
因为Name是一个SQLUPPER字符串数据类型,子字符串的末尾空格将被忽略:
SELECT Name FROM Sample.Person
WHERE Name %STARTSWITH 'M '
在下面的示例中,%STARTSWITH从结果集中删除所有行,因为对于数值,子字符串的末尾空格不会被忽略:
SELECT Name,Age FROM Sample.Person
WHERE Age %STARTSWITH '6 '
在下面的示例中,%STARTSWITH从结果集中删除所有行,因为对于列表值,子字符串中的末尾空不会被忽略:
SELECT Name,FavoriteColors FROM Sample.我经常发现自己与现存客户和潜在客户就他们在访问数据方面的挫败感进行对话。他们最常见的话题是围绕对“速度的需求”展开的——可以理解,这是非常正确的。
用指定初始字符的子字符串匹配值。
scalar-expression %STARTSWITH substring
scalar-expression - 将其值与子字符串进行比较的标量表达式(最常见的是数据列)。substring - 解析为包含与标量表达式中的值匹配的第一个或多个字符的字符串或数字的表达式。%STARTSWITH谓词允许选择以子字符串中指定的字符开头的数据值。
如果substring不匹配任何标量表达式值,%STARTSWITH返回空字符串。
无论显示模式如何,这个匹配总是在逻辑(内部存储)数据值上执行。
下面的示例选择所有以“M”开头的名称:
SELECT Name FROM Sample.MyTest WHERE Name %STARTSWITH 'M'
可以用NOT来颠倒谓词的意思。
下面的示例选择除了以“M”开头的名称以外的所有名称:
SELECT Name FROM Sample.MyTest WHERE NOT Name %STARTSWITH 'M'
%STARTSWITH使用与它匹配的字段相同的排序规则类型。
默认情况下,字符串数据类型字段是用SQLUPPER排序规则定义的,它不区分大小写。
应用集成技术是市场上被广泛使用的,也是充斥着术语和概念的一个技术领域。集成平台、消息引擎、消息中间件、集成引擎、集成中间件、企业服务总线(ESB)、API网关、API管理… 很多概念与名词。到底它们是什么意思?有什么区别?哪种技术适合解决哪种集成问题?
业务集成的需求和技术的演进是紧随业务系统的软件架构发展而发展的。通过小结软件架构的发展,我们更容易梳理业务集成技术的演进、更容易看清楚各种集成架构的优势和未来发展方向。
将值与子查询中的至少一个匹配值匹配。
scalar-expression comparison-operator SOME (subquery)
scalar-expression - 将其值与子查询生成的结果集进行比较的标量表达式(最常见的是数据列)。comparison-operator - 以下比较操作符之一:=(等于),<>或!=(不等于),<`(小于),`<=`(小于或等于),`>(大于),>=(大于或等于),[(包含),或](跟随)。subquery - 一个用括号括起来的子查询,它返回一个用于与标量表达式比较的结果集。SOME关键字与比较操作符一起创建谓词(量化比较条件),如果标量表达式的值与子查询检索到的一个或多个对应值匹配,则该谓词为真。
SOME谓词将单个标量表达式项与单个子查询SELECT项进行比较。
具有多个选择项的子查询将生成SQLCODE -10错误。
注意:SOME和ANY关键字是同义词。
下面的例子选择了居住在密西西比河以西任何一个州的工资超过75,000美元的员工:
SELECT Name,Salary,Home_State FROM Sample.用包含字面值、通配符和字符类型代码的模式字符串匹配值。
scalar-expression %PATTERN pattern
scalar-expression - 一个标量表达式(最常见的是数据列),它的值正在与模式进行比较。pattern - 一个带引号的字符串,表示要与标量表达式中的每个值匹配的字符模式。
模式字符串可以包含双引号括起来的文字字符、指定字符类型的字母代码以及数字和作为通配符的句点(.)字符。%PATTERN谓词允许将字符类型代码和字面值的模式匹配到由标量表达式提供的数据值。
如果模式匹配完整的标量表达式值,则返回该值。
如果pattern没有完全匹配任何标量表达式值,%pattern将返回空字符串。
%PATTERN使用与ObjectScript模式匹配操作符相同的模式代码(?
操作符)。
模式由一对或多对重复计数和一个值组成。
重复计数可以是整数,句点(.)表示“任意数量的字符”,或者使用句点和整数的组合指定的范围。
值可以是字符类型代码字母或字符串字面值(在引号中指定)。
请注意,一个模式通常由多个重复/值对组成,因为该模式必须与整个数据值完全匹配。因此,许多模式都以“.E”对结尾,这意味着数据值的其余部分可以由任意数量的任意类型的字符组成。
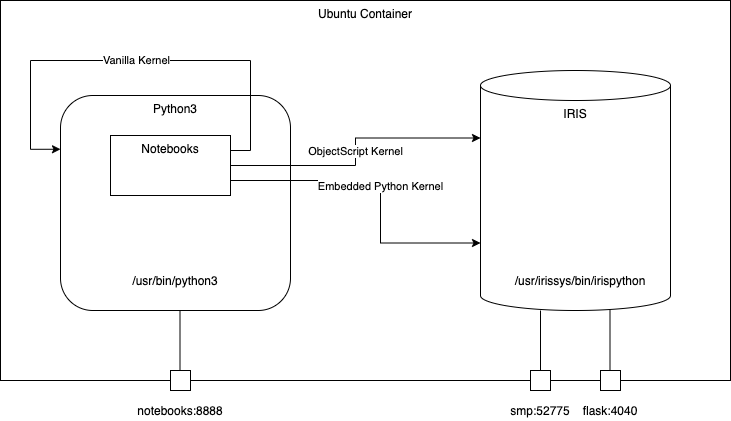
包含各种Python代码的项目模版,可用于InterSystems IRIS 社区容器版Community Edition with container。
特性 :
InterSystems IRIS、IRIS for Health 以及 HealthShare Health Connect 的 2021.2 版本的预览版现已发布。
由于这是一个预览版,我们希望在下个通用版本发布之前了解您对这个新版本的体验。请通过开发者社区分享您的反馈,以便我们能够共同打造一个更好的产品。
用包含字面值、通配符和范围的模式字符串匹配值。
scalar-expression %MATCHES pattern [ESCAPE char]
scalar-expression - 一个标量表达式(最常见的是数据列),它的值正在与模式进行比较。pattern - 一个带引号的字符串,表示要与标量表达式中的每个值匹配的字符模式。
模式字符串可以包含文字字符,问号(?)和星号(*)通配符,方括号用于指定允许的值,反斜杠(\)用于指定紧跟其后的字符被视为文字。
模式也可以是空字符串或NULL,尽管它不匹配或返回NULL项。ESCAPE char - 可选-包含单个字符的字符串。
这个字符字符可以在模式中用于指定紧跟在它后面的字符将被视为文字。
如果未指定,默认转义字符是反斜杠(\)。%MATCHES谓词是 IRIS扩展,用于将值匹配到模式字符串。
%MATCHES返回True或False用于匹配操作。
模式字符串可以由字面量字符、通配符字符和匹配字面量的列表或范围组成。
模式匹配区分大小写。
模式匹配基于标量表达式的EXACT值,而不是它的排序规则值。
因此,%MATCHES操作始终是大小写敏感的,即使标量表达式的排序规则类型不区分大小写。
%MATCHES支持以下模式通配符:
? - 匹配任意类型的任意单个字符。亲爱的开发者们,
如果您需要更改您的主邮箱地址(登录邮箱),同时不希望丢失任何开发者生态系统资源里的activity——在社区、Global Master、Open Exchange中的各种交流与历史活动痕迹——该如何去做呢?
很简单,我们来帮您!
1️⃣ 我们会帮您把所有资料信息从您的旧账户中转移到新账户
包括您的所有发帖、评论、艾特(@)和点赞记录,都会被保存在新账户中!
2️⃣ 如果您是 Global Masters的成员,您的级别、徽章、分数等等,也会被转移到新账户中。
3️⃣ 我们还会帮您转移您发布在 Open Exchange中的应用。
4️⃣ 除此之外,如果您只是需要停用您的旧账号(而无需转移任何活动记录),我们都可以帮您一键操作。
您所需要做的,就是通过社区email私信联系 @Irina.Podmazko,提供 :
怎么样?
有我们的帮助,您可以平滑过渡到新账户!
有疑问请随时与我们沟通:)
P.s.
用包含字面值和通配符的模式字符串匹配值。
scalar-expression LIKE pattern [ESCAPE char]
scalar-expression - 一个标量表达式(最常见的是数据列),它的值正在与模式进行比较。pattern - 一个带引号的字符串,表示要与标量表达式中的每个值匹配的字符模式。
模式字符串可以包含字面字符、下划线(_)和百分比(%)通配符。ESCAPE char 可选-包含单个字符的字符串。
这个字符字符可以在模式中用于指定紧跟在它后面的字符将被视为文字。LIKE谓词允许选择那些匹配模式中指定的字符的数据值。
模式可以包含通配符。
如果pattern不匹配任何标量表达式值,LIKE返回空字符串。
LIKE可以在任何可以指定谓词条件的地方使用,如本手册的谓词概述页面所述。
LIKE谓词支持以下通配符:
_ - 任何单个字符% - 由0个或多个字符组成的序列。
(根据SQL标准,NULL不被认为是一个0字符的序列,因此不被这个通配符选中。)在动态SQL或嵌入式SQL中,模式可以将通配符和输入参数或输入主机变量表示为连接的字符串,如示例部分所示。
注意:当在运行时提供谓词值时(使用?
我在 InterSystems 工作了 35 年,期间见证了许多客户与我们共同成长。我们热忱地帮助客户取得成功——无论他们衡量成功的标准是什么——而成功的基石就是我们提供的技术。我们的名字现在通常与我们的 InterSystems IRIS 数据平台联系在一起,因为它实际上是我们经过验证的下一代数据管理软件。
确定一个数据值是否为NULL。
scalar-expression IS [NOT] NULL
IS NULL谓词检测未定义的值。
可以检测到所有空值,或所有非空值:
SELECT Name, FavoriteColors FROM Sample.Person
WHERE FavoriteColors IS NULL
SELECT Name, FavoriteColors FROM Sample.Person
WHERE FavoriteColors IS NOT NULL
IS NULL / IS NOT NULL谓词是少数几个可以在WHERE子句中用于流字段的谓词之一。
如下面的例子所示:
SELECT Title,%OBJECT(Picture) AS PhotoOref FROM Sample.Employee
WHERE Picture IS NOT NULL
不应将IS NULL谓词与SQL ISNULL函数混淆。
您可能已经听说,我们目前正在为所有正在使用 Caché 和 Ensemble 的客户提供限时免费迁移到我们的下一代数据平台 InterSystems IRIS 的机会。
虽然我们依旧如往常一样全力支持那些正在使用 Caché 数据库和 Ensemble 集成引擎的客户,但我们还是认为 InterSystems IRIS 是未来的关键。它结合了 Caché 和 Ensemble 的所有功能,并添加了大量令人兴奋的强大功能,从机器学习到原生 Python。
这也正是我们为现有客户提供迁移到 InterSystems IRIS 并使用这些新功能的原因。 我们也通过就地迁移支持轻松迁移,这意味着无需数据库转换、分步迁移指南、教程等。
听起来挺有趣对吗? 以下是我针对当前 Caché 和 Ensemble 应迁移到 InterSystems IRIS 的五个主要原因。
确定数据值是否为JSON格式。
注意:IRIS版本可用。其他不行。
scalar-expression IS [NOT] JSON [keyword]
scalar-expression - 正在检查JSON格式的标量表达式。keyword - 可选—可选值、标量、数组或对象。
默认为VALUE。IS JSON谓词确定数据值是否为JSON格式。
下面的示例确定谓词是否是格式化正确的JSON字符串,是JSON对象还是JSON数组:
ClassMethod IsJson()
{
s q1 = "SELECT TOP 5 Name FROM Sample.Person "
s q2 = "WHERE '{""name"":""Fred"",""spouse"":""Wilma""}' IS JSON"
s myquery = q1_q2
s tStatement = ##class(%SQL.Statement).%New()
s qStatus = tStatement.%Prepare(myquery)
if qStatus'=1 {
w "%Prepare failed:"
d $System.Status.DisplayError(qStatus)
q
}
s rset = tStatement.将一个值匹配到一组生成的值。
scalar-expression %INSET valueset [SIZE ((nn))]
scalar-expression - 一个标量表达式(最常见的是表的RowId字段),它的值正在与值集进行比较。valueset - 对实现ContainsItem()方法的用户定义对象的对象引用(oref)。
该方法接受一组数据值,并在与标量表达式中的值匹配时返回一个布尔值。SIZE ((nn)) - 可选-用于查询优化的数量级整数(10、100、1000等)。%INSET谓词允许通过选择与值集中指定的值相匹配的数据值来筛选结果集。
当标量表达式的值与valueset中的值匹配时,此匹配将成功。
如果值集值不匹配任何标量表达式值,%INSET返回空字符串。
无论显示模式如何,这个匹配总是在逻辑(内部存储)数据值上执行。
对于NULL值,%INSET永远不为真。
因此,它不会将标量表达式中的NULL与值集中的NULL相匹配。
与其他比较条件一样,%INSET用于SELECT语句的WHERE子句或HAVING子句中。
%INSET启用使用抽象的、编程指定的匹配值集过滤字段值。
具体地说,它使用抽象的、编程指定的临时文件或位图索引来过滤RowId字段值,其中的值集行为类似于位图索引或常规索引的最低下标层。
将一个值匹配到%List结构化列表中的元素。
scalar-expression %INLIST list [SIZE ((nn))]
scalar-expression - 将其值与列表元素进行比较的标量表达式(最常见的是数据列)。list - 包含一个或多个元素的%List结构。SIZE ((nn)) - 可选-指定列表中元素数量估计值的整数。
必须指定为具有下列值之一的字面值:10、100、1000、10000,等等。%INLIST谓词是 IRIS扩展,用于将字段的值与列表结构的元素匹配。
%INLIST和IN都允对多个指定值执行这样的相等比较。
%INLIST将这些多个值指定为单个列表参数的元素。
因此,%INLIST允许改变要匹配的值的数量,而无需创建单独的缓存查询。
可选的%INLIST SIZE子句提供整数nn,它指定list中列表元素数量的数量级估计数。
IRIS使用这个数量级估计来确定最佳查询计划。
因为不管列表中元素的数量是多少,都会使用相同的缓存查询,所以指定SIZE允许创建缓存查询,针对列表中预期的元素的大致数量进行优化。
更改SIZE字面值将创建一个单独的缓存查询。
指定nn为以下文字之一:10、100、1000、10000,等等。
将值匹配到以逗号分隔的非结构化列表中的项。
scalar-expression IN (item1,item2[,...])
scalar-expression IN (subquery)
scalar-expression - 标量表达式(最常见的是数据列),将其值与以逗号分隔的值列表或子查询生成的结果集进行比较。item - 一个或多个文本值、输入主机变量或解析为文本值的表达式。
以任何顺序列出,以逗号分隔。subquery - 一个用括号括起来的子查询,它从单个列返回一个结果集,用于与标量表达式进行比较。IN谓词用于将值匹配到非结构化的项系列。
通常,它将列数据值与以逗号分隔的值列表进行比较。
IN可以执行相等比较和子查询比较。
与大多数谓词一样,可以使用NOT逻辑操作符反转IN。
IN和NOT IN都不能用于返回空字段。
返回NULL字段使用IS NULL。
可以在任何可以指定谓词条件的地方使用IN,如本手册的谓词概述页面所述。
IN谓词可以用作多个相等比较的简写,这些比较用OR操作符连接在一起。
例如:
将列表元素值或列表元素的数量与谓词匹配。
FOR SOME %ELEMENT(field) [[AS] e-alias] (predicate)
field - 将其元素与谓词进行比较的标量表达式(最常见的是数据列)。AS e-alias - 可选-用于限定谓词中的%KEY或%VALUE的元素别名。通常,当谓词包含嵌套的FOR某些%ELEMENT条件时,会使用此别名。别名必须是有效的标识符。(predicate) - 用括号括起来的谓词条件。
在这个条件中,使用%VALUE和/或%KEY来确定条件匹配的是什么。
%VALUE匹配元素值(%VALUE= ' Red ')。
%KEY匹配元素的最小数目(%KEY=2)。
在此条件下,如果您指定了e-alias, %VALUE和%KEY可能是可选限定的。
这个谓词可以由多个带有AND和OR逻辑运算符的条件表达式组成。FOR SOME %ELEMENT谓词将字段中的列表元素与指定的谓词匹配。
SOME关键字指定字段中至少有一个元素必须满足指定的谓词子句。
谓词子句必须包含%VALUE或%KEY关键字,后跟谓词条件。
这些关键字不区分大小写。
下面的例子解释了%VALUE和%KEY的用法:
(%VALUE=’Red’) 匹配所有包含值Red作为其列表元素之一的字段值。我试图使用
我想与您分享一些在 Caché 中同样存在但几乎不为人知且大多未使用的存储功能。 它们当然可以在 IRIS 中使用,并且在大型分布式存储架构中变得越来越重要。
确定是否根据字段值的条件测试返回记录。
FOR SOME (table [AS t-alias]) (fieldcondition)
table - Table可以是单个表,也可以是用逗号分隔的表列表。
括号是必须的。
AS t-alias - 可选-前一个表名的别名。
别名必须是有效的标识符;
它可以是一个分隔符。
fieldcondition - fieldcondition 指定一个或多个引用一个或多个字段的条件表达式。
字段条件用括号括起来。
可以使用AND(&)和OR(!)逻辑操作符在字段条件中指定多个条件表达式。
FOR SOME谓词允许根据表中一个或多个字段值的布尔条件测试来决定是否返回记录。
如果fieldcondition计算结果为true,则返回记录。
如果fieldcondition计算结果为false,则不返回记录。
对于表(及其可选的t-alias)参数,必须使用括号分隔。
分隔括号对于字段条件参数也是强制性的。
允许(但不是必需的)在这两组括号之间使用空格。
通常,FOR SOME用于确定是否根据另一个表中一条记录的内容从一个表返回一条记录。
FOR SOME还可用于确定是否根据同一表中记录的内容从表中返回记录。
在后一种情况下,要么返回所有记录,要么不返回任何记录。
使用位图块迭代将一个值匹配到一组生成的值。
scalar-expression %FIND valueset [SIZE ((nn))]
scalar-expression - 一个标量表达式(最常见的是表的RowId字段),它的值正在与值集进行比较。valueset - 对用户定义对象的对象引用(oref),该对象实现位图块迭代方法和ContainsItem()方法。
该方法接受一组数据值,并在与标量表达式中的值匹配时返回一个布尔值。SIZE ((nn)) - 可选-用于查询优化的数量级整数(10、100、1000等)。通过选择与值集中指定的值相匹配的数据值,通过迭代位图块序列中的值,%FIND谓词允许筛选结果集。
当标量表达式的值与valueset中的值匹配时,此匹配将成功。
如果值集值不匹配任何标量表达式值,%FIND返回空字符串。
无论显示模式如何,这个匹配总是在逻辑(内部存储)数据值上执行。
%FIND和其他比较条件一样,用于SELECT语句的WHERE子句或HAVING子句中。
%FIND使用抽象的、通过编程指定的匹配值集来过滤字段值。
具体来说,它使用抽象的、编程指定的位图来过滤RowId字段值,其中的值集行为类似于位图索引的下标层。
用户定义类派生自抽象类%SQL.AbstractFind
检查表中是否至少存在一个对应行。
EXISTS select-statement
select-statement - 一种简单的查询,通常包含一个条件表达式。EXISTS谓词测试指定的表,通常至少测试一行是否存在。
因为EXISTS后面的SELECT语句正在被检查是否包含某些内容,所以子句通常是这样的形式:
EXISTS (SELECT... FROM... WHERE...)
SELECT name
FROM Table_A
WHERE EXISTS
(SELECT *
FROM Table_B
WHERE Table_B.Number = Table_A.Number)
在本例中,谓词测试子查询指定的一行或多行是否存在。
注意,测试必须发生在SELECT语句上(而不是在UNION上)。
NOT EXISTS子句测试表中是否有一行不存在,如下例所示:
SELECT EmployeeName,Age
FROM Employees
WHERE NOT EXISTS (SELECT * FROM BonusTable
WHERE NOT (BonusTable.
