大家好!
约翰·霍普金斯大学每天都会发布有关 COVID-19 疫情的新数据。
我在部署于 GCP Kubernetes 上的 docker 中使用 InterSystems IRIS Community Edition 构建了一个简单的 InterSystems IRIS Analytics 仪表板,可显示疾病爆发的关键指标。
大家好!
约翰·霍普金斯大学每天都会发布有关 COVID-19 疫情的新数据。
我在部署于 GCP Kubernetes 上的 docker 中使用 InterSystems IRIS Community Edition 构建了一个简单的 InterSystems IRIS Analytics 仪表板,可显示疾病爆发的关键指标。
关键字:Python,JDBC,SQL,IRIS,Jupyter Notebook,Pandas,Numpy ,机器学习
这是一个用于演示的 5 分钟快速笔记,通过 Jupyter Notebook 中的 Python 3 调用 IRIS JDBC 驱动程序,以经由 SQL 语法从 IRIS 数据库实例读取数据和向 IRIS 数据库实例写入数据。
去年,我发表了关于将 Python 绑定到 Cache 数据库的简要笔记(第 4.7 节)。 如何使用 Python 挂入 IRIS 数据库以将其数据读入 Pandas 数据框和 NumPy 数组进行常规分析,然后再将一些经过预处理或标准化的数据写回 IRIS 中,准备进一步用于 ML/DL 管道,现在可能是时候回顾一些选项和讨论了。
一些立即浮现的快速选项:
这里有漏掉其他选项吗? 我有兴趣尝试任何选项。
若要将全局变量(全部或部分)的内容复制到另一个全局变量(或局部数组)中,请使用ObjectScript Merge命令。
下面的示例演示如何使用Merge命令将OldData全局变量的全部内容复制到NewData全局变量中:
Merge ^NewData = ^OldData
如果合并命令的source参数有下标,则复制该节点及其后代中的所有数据。如果Destination参数有下标,则使用目标地址作为顶级节点复制数据。例如,以下代码:
Merge ^NewData(1,2) = ^OldData(5,6,7)
将^OldData(5,6,7)及其下的所有数据复制到^NewData(1,2)。
大规模事务处理应用程序的一个主要并发瓶颈可能是创建唯一标识符值。例如,考虑一个订单处理应用程序,在该应用程序中,必须为每一张新发票指定一个唯一的标识号。传统的方法是维护某种计数器表。每个创建新发票的进程都会等待获取此计数器上的锁,递增其值,然后将其解锁。这可能会导致对此单个记录的激烈资源争用。
为了解决此问题,InterSystems IRIS提供了ObjectScript $INCREMENT函数。$INCREMENT自动递增全局节点的值(如果该节点没有值,则设置为1)。
Hi Developers!
看看2021年4月的开发者社区新版本有些什么改善, 主要的新特性包括:
This is a release of how did we improve the Developer Community in April 2021. The key features:
以下是详细介绍。
有许多方法可以遍历(迭代)存储在全局变量中的数据。
ObjectScript $Order函数允许顺序访问全局中的每个节点。
$ORDER函数返回给定级别(下标编号)的下一个下标的值。例如,假设定义了以下全局设置:
Set ^Data(1) = ""
Set ^Data(1,1) = ""
Set ^Data(1,2) = ""
Set ^Data(2) = ""
Set ^Data(2,1) = ""
Set ^Data(2,2) = ""
Set ^Data(5,1,2) = ""
要查找第一个第一级下标,我们可以使用:
SET key = $ORDER(^Data(""))
这将返回空字符串(“”)之后的第一个第一级下标。(空字符串用于表示第一个条目之前的下标值;作为返回值,它用于指示没有后续的下标值。)。在本例中,key现在将包含值1。
我们可以通过在$ORDER表达式中使用1或键来查找下一个第一级下标:
SET key = $ORDER(^Data(key))
如果key的初始值为1,则此语句将其设置为2(因为^Data(2)是下一个第一级下标)。再次执行此语句会将key设置为5,因为这是下一个第一级下标。请注意,即使没有直接存储在^Data(5)中的数据,也会返回5。
本章描述了使用多维存储(全局变量)可以执行的各种操作。
在全局节点中存储数据很简单:像对待任何其他变量一样对待全局变量。 区别在于对全局变量的操作是自动写入数据库的。
创建新的全局变量不需要设置工作;只需将数据设置为全局变量即可隐式创建新的全局结构。可以创建全局变量(或全局变量下标)并通过单个操作将数据放入其中,也可以创建全局变量(或下标)并通过将其设置为空字符串将其保留为空。在ObjectScript中,这些操作是使用SET命令完成的。
下面的例子定义了一个名为Color(如果还不存在)的全局变量,并将值“Red”与之关联。
如果已经存在一个名为Color的全局变量,那么这些示例将其修改为包含新信息。
在ObjectScript中:
SET ^Color = "Red"
注意:在应用程序中使用直接全局访变量问时,应制定并遵守命名约定,以防止应用程序的不同部分相互“遍历”;这类似于为类、方法和其他变量开发命名约定。
要在全局下标节点中存储值,只需像设置任何其他变量数组一样设置全局节点的值。如果指定的节点以前不存在,则会创建该节点。如果它确实存在,则其内容将替换为新值。
可以通过表达式(称为全局引用)指定全局内的节点。全局引用由脱字符(^)、全局名称和(如果需要)一个或多个下标值组成。
全局变量使用高度优化的结构存储在物理文件中。管理此数据结构的代码也针对运行InterSystems IRIS的每个平台进行了高度优化。这些优化确保全局操作具有高吞吐量(每单位时间的操作数)、高并发性(并发用户总数)、缓存的高效使用,并且不需要与性能相关的持续维护(例如频繁的重建、重新索引或压缩)。
用于存储全局变量的物理结构是完全封装的;应用程序不会以任何方式担心物理数据结构。
全局变量存储在磁盘上的一系列数据块中;每个块的大小(通常为8KB)是在创建物理数据库时确定的。为了提供对数据的高效访问,InterSystems IRIS维护了一种复杂的B树状结构,该结构使用一组指针块将相关数据块链接在一起。InterSystems IRIS维护一个缓冲池-经常引用的块的内存缓存-以降低从磁盘获取块的成本。
虽然许多数据库技术使用类似B树的结构来存储数据,但InterSystems IRIS在许多方面都是独一无二的:
本章描述全局变量的逻辑视图,并概述全局变量是如何在磁盘上物理存储的。
全局变量是存储在物理InterSystems IRIS®数据库中的命名多维数组。 在应用程序中,全局变量到物理数据库的映射基于当前名称空间——名称空间提供一个或多个物理数据库的逻辑统一视图。
全局名称指定其目标和用途。有两种类型的全局变量和一组单独的变量,称为“进程私有全局变量”:
全局变量的命名约定如下:
^)前缀开头。这个插入符号区分全局变量和局部变量。^)前缀后的第一个字符可以是:
ASCII 65到ASCII 255范围内的字母字符。如果全局名称以“%”开头(但不是“%Z”或“%z”),则此全局名称供InterSystems IRIS系统使用。%GLOBAL通常存储在IRISSYS或IRISLIB数据库中。|)或左方括号([)-表示扩展全局引用或进程专用全局变量。InterSystems IRIS®的核心功能之一是其多维存储引擎。此功能允许应用程序以紧凑、高效的多维稀疏数组存储数据。这些数组称为全局数组。
本章介绍:
globals ),以及可以对其执行的操作。全局变量提供了一种在持久的多维数组中存储数据的易于使用的方法。
例如,可以使用名为^Settings的全局变量将值“Red”与键“Color”相关联:
SET ^Settings("Color")="Red"
可以利用全局变量的多维特性来定义更复杂的结构:
SET ^Settings("Auto1","Properties","Color") = "Red"
SET ^Settings("Auto1","Properties","Model") = "SUV"
SET ^Settings("Auto2","Owner") = "Mo"
SET ^Settings("Auto2","Properties","Color") = "Green"
全局变量具有以下功能:
有两种方式显示SQL语句的详细信息:
可以使用“SQL语句详细信息”显示来查看查询计划,并冻结或解冻查询计划。
“SQL语句详细信息”提供冻结或解冻查询计划的按钮。
它还提供了一个Clear SQL Statistics按钮来清除性能统计,一个Export按钮来将一个或多个SQL语句导出到一个文件,以及一个Refresh和Close页面按钮。
SQL语句详细信息显示包含以下部分。
大多数SQL语句都有一个关联的查询计划。查询计划是在准备SQL语句时创建的。默认情况下,添加索引和重新编译类等操作会清除此查询计划。下次调用查询时,将重新准备查询并创建新的查询计划。冻结计划使可以跨编译保留(冻结)现有查询计划。查询执行使用冻结的计划,而不是执行新的优化并生成新的查询计划。
对系统软件的更改也可能导致不同的查询计划。通常,这些升级会带来更好的查询性能,但软件升级可能会降低特定查询的性能。冻结计划使可以保留(冻结)查询计划,以便查询性能不会因系统软件升级而改变(降级或提高)。
使用冻结计划有两种策略-乐观策略和悲观策略:
%NOFPLAN关键字重新运行查询(这会导致冻结的计划被忽略)。比较这两个查询的性能。如果忽略冻结的计划没有提高性能,请保持冻结该计划并从查询中删除%NOFPLAN。经常被问到有关IRIS如何支持SSL,HTTPS的问题,有必要写个东西介绍一下。
##HTTPS的原理 简单的说,https实现两个目的:一是访问网站加密,2是确认被访问的网站是真的。
首先,被访问的网站要申请一个证书,这个证书必须是权威机构发放的,比如google, VeriSign等等,所有的浏览器里有预装了这些组织的公钥(Public Key),因此能确认你提供的证书真是这些组织给出的,而这个证书可以证明你的网站的身份。注意证书证明的是提供服务的组织和服务的真实性,和用什么设备没关系,也就是说,IRIS不管证书的事儿。
接下去,被访问的服务器可以生成公钥和私钥,和客户端交换key,生成整个世界只有两者知道的security code,用来两者之间数据的交换。详细的过程和消息交互可以在网上找到很多很好的文章和视频,比如这个: How does HTTPS work? What's a CA? What's a self-signed Certificate?。
如果是测试环境或者使用者可以控制的内部网络,self-signed证书非常常用。self-signed证书就是不去花钱找人认证,而是告诉客户端,我这个证书是自己认证的,你知道我这台机器试内网的一个机器,不用权威机构证明我服务器的身份,咱们交换一下钥匙把通信加密了吧。
前言
着手书写“临床医生与信息系统的‘爱恨情愁’”系列文章的初衷是,希望从终端用户的视角阐述我们所期待的信息系统,为医学信息工作者提供参考,助力医学信息系统不断改进,最终迎来医疗品质的完美提升。在这个系列中,笔者会以临床常见疾病为例,用真实的临床场景说明亲身经历过的信息系统的优势和不足。其中肯定有思虑不周全或逻辑不严谨之处,望各位读者按需审阅,取其精华、弃其糟粕。同时,文中不涉及机构管理、收银财务、耗材库管等环节对临床工作的影响。此外,本系列更多在于探讨信息系统在临床应用场景中的“可能性”,而非“可行性”;文中部分图片尚处于设想模拟阶段,并非真实系统图片,请知悉。
正文
《中国心血管疾病报告2018》明确指出,心血管疾病死亡率居所有死因首位,且其发病率仍然处于上升阶段。胸痛中心作为欧美发达国家普遍应用的急性心血管疾病急救诊疗体系,凭借全新的管理理念和多学科协作的医疗模式及规范化的胸痛诊治流程,实现早期快速诊断、危险评估分层、正确分流、科学救治和改善预后,有效地缩短救治时间,降低患者的死亡率和并发症发生率。为了让更多心血管疾病和其他危重胸痛患者可以得到更及时和有效的救治,切实推进《健康中国行动2019-2030》的顺利实施,最终实现“以疾病为中心”到“以健康为中心”的战略转移,卫健委在过去的九年里,联合权威专家,主持并推进了中国胸痛中心的建设。
这个SQL语句列表为每个表提供了SQL查询和其他操作的记录,包括插入、更新和删除。 这些SQL语句链接到一个查询计划,该链接提供冻结该查询计划的选项。
系统为每个SQL DML操作创建一条SQL语句。 这提供了一个按表、视图或过程名称列出的SQL操作列表。 如果更改表定义,可以使用此SQL Statements列表来确定每个SQL操作的查询计划是否会受到此DDL更改的影响,以及/或是否需要修改某个SQL操作。 然后,可以:
注意:SQL语句是一个SQL例程列表,它们可能会受到表定义更改的影响。 它不应该用作表定义或表数据更改的历史记录。
下面的SQL操作会创建相应的SQL语句:
数据管理(DML)操作包括对表的查询、插入、更新和删除操作。 每个数据管理(DML)操作(动态SQL和嵌入式SQL)在执行时都会创建一个SQL语句。
SELECT命令在准备查询时创建SQL语句。
此外,在管理门户缓存查询列表中创建了一个条目。本章介绍由ShowPlan生成的InterSystems SQL查询访问计划中使用的语言和术语。
SQL表存储为一组映射。 每个表都有一个包含表中所有数据的主映射; 表还可以有其他的映射,如索引映射和位图。 每个映射可以被描绘成一个多维全局,其中一些字段的数据在一个或多个下标中,其余字段存储在节点值中。 下标控制要访问的数据。
RowID或IDKEY字段通常用作映射下标。RowID/IDKEY字段用作附加的较低级别的下标。RowID。编译SQL查询会生成一组指令来访问和返回查询指定的数据。
这些指令表示为. int例程中的ObjectScript代码。
指令及其执行顺序受到SQL编译器中有关查询中涉及的表的结构和内容的数据的影响。 编译器尝试使用表大小和可用索引等信息,以使指令集尽可能高效。
查询访问计划(ShowPlan)是对结果指令集的可读翻译。
查询的作者可以使用这个查询访问计划来查看将如何访问数据。
虽然SQL编译器试图最有效地利用查询指定的数据,但有时查询的作者对存储的数据的某些方面的了解要比编译器清楚得多。
本章介绍可用于主动分析特定SQL语句的分析工具。这些工具收集有关这些SQL语句执行的详细信息。使用这些信息,开发人员可以采取措施提高低效SQL语句的性能。
根据请求的详细程度,此活动分析可能会显著增加服务器上的负载。因此,SQL性能分析工具包旨在进行协调一致的代码分析工作。它不是用来连续监视执行代码的。
SQL性能分析工具包为开发人员和支持专家提供了分析特定SQL语句或语句组的能力。通过在执行特定SQL语句期间使用这些工具,它们可以收集详细信息,这些信息可用于单独或跨活动工作负载分析有问题的语句。
要记录的细节级别是可配置的,最细粒度的设置在模块级别收集信息,为语句的查询计划中的不同“步骤”提供信息。
%SYSTEM.SQL.PTools类方法。
修改过用户门户之后,重新启动就报这个错,然后使用自带的修复功能,修复之后依然报错,日志中显示没有C:\InterSystems\HealthConnect\mgr\IRIS.WIJ,我复制了别人的过来依然报错,由于代码没有做备份我不能重装,有没有什么办法修复一下,或者把代码备份一下,我再重装。

在ensemble使用$SYSTEM.Encryption.SHA1Hash()加密“ensmble”得到“t????????????m??Afù????÷??%í”,但使用网络的SHA1加密方法得到”74ba9a06cbbc92f06d9b4166f9c5b4f7f8251aed“,如何使用ensemble得到与网络上一样的加密结果
可以在SELECT、INSERT、UPDATE、DELETE或TRUNCATE表命令中为查询优化器指定一个或多个注释选项。
注释选项指定查询优化器在编译SQL查询期间使用的选项。
通常,注释选项用于覆盖特定查询的系统范围默认配置。
语法/*#OPTIONS */(在/*和#之间没有空格)指定了一个注释选项。
注释选项不是注释;
它为查询优化器指定一个值。
注释选项使用JSON语法指定,通常是“key:value”对,例如: /*#OPTIONS {"optionName":value} */。
支持更复杂的JSON语法,比如嵌套值。
注释选项不是注释;
除了JSON语法之外,它可能不包含任何文本。
包含非json文本在/* ... */分隔符导致SQLCODE -153错误。
InterSystems SQL不验证JSON字符串的内容。
#OPTIONS关键字必须用大写字母指定。
JSON的大括号语法中不应该使用空格。
如果SQL代码用引号括起来,比如动态SQL语句,JSON语法中的引号应该是双引号。
例如:myquery="SELECT Name FROM Sample.
m 里面如何获取cpu的序列号?
数据库日志经常性出现如下日志,希望遇到过的朋友给出解决方法!
04/13/21-07:21:28:522 (191540) 0 ECP: Lost net connection: Error 104=(Connection reset by peer)
04/13/21-07:21:28:522 (191540) 1 ECP: connection from 'ECP1:HIS-AAA4:CACHE' dropped (1.1.1.1:14400)
04/13/21-07:21:28:672 (198470) 0 ECP: Mirror Connection request from 'ECP1:HIS-AAA:CACHE' (1.1.1.1:14419)
最近尝试使用
如何做到处方审核便捷性与安全性共存,一直是个“鱼与熊掌”的情形。开始正文前,先说个故事——
可以使用解释或显示计划工具来显示SELECT、DECLARE、UPDATE、DELETE、TRUNCATE TABLE和一些INSERT操作的执行计划。这些操作统称为查询操作,因为它们使用SELECT查询作为其执行的一部分。InterSystems IRIS在准备查询操作时生成执行计划;不必实际执行查询来生成执行计划。
默认情况下,这些工具显示InterSystems IRIS认为的最佳查询计划。对于大多数查询,有多个可能的查询计划。除了InterSystems IRIS认为最佳的查询计划外,还可以生成和显示备用查询执行计划。
InterSystems IRIS提供以下查询计划工具:
$SYSTEM.SQL.ExPlan()方法可用于生成和显示XML格式的查询计划以及备选查询计划(可选)。EXPLAIN命令可用于生成XML格式的查询计划,还可以选择生成备选查询计划和SQL统计信息。所有生成的查询计划和统计信息都包含在名为Plan的单个结果集字段中。请注意,EXPLAIN命令只能与SELECT查询一起使用。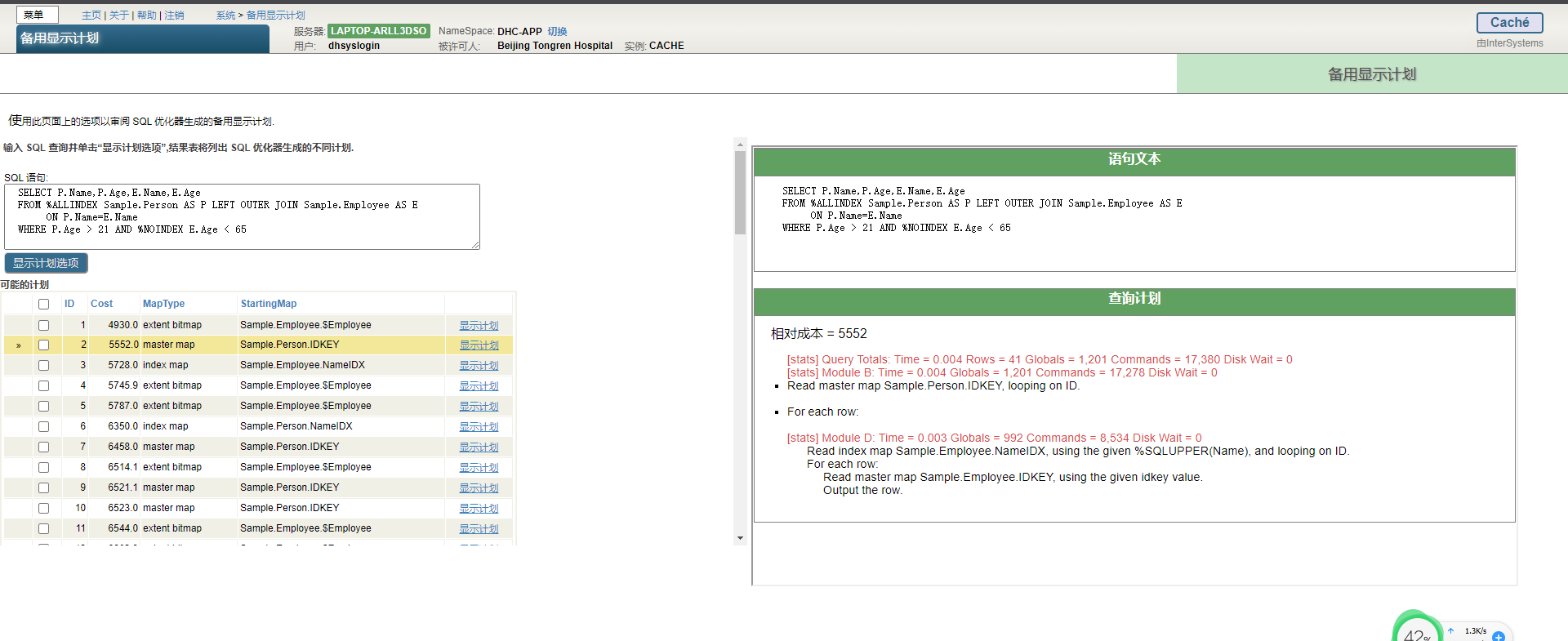
对于生成的%PARALLEL和分片查询,这些工具显示所有适用的查询计划。
我需要能修改xml 文件里面某个节点的值,目前 使用的方法是EnsLib.EDI.XML.Document 里面的
InterSystems IRIS、IRIS for Health和HealthShare Health Connect的2021.1版本的预览版现已发布。
由于这是一个预览版,我们希望在下个月的通用版本发布之前了解您对这个新版本的体验。请通过开发者社区分享您的反馈,以便我们能够共同打造一个更好的产品。
InterSystems IRIS数据平台2021.1是一个扩展维护(EM)版本。自2020.1(上一个EM版本)以来,在持续交付(CD)版本中增加了许多重要的新功能和改进。请参考2020.2、2020.3和2020.4的发布说明,了解这些内容的概况。
这个版本的增强功能为开发人员提供了更大的自由度,可以用他们选择的语言构建快速和强大的应用程序,并使用户能够通过新的和更快的分析功能更有效地处理大量的信息。
通过InterSystems IRIS 2021.1,客户可以部署InterSystems IRIS Adaptive Analytics,这是一个附加产品,它扩展了InterSystems IRIS,为分析终端用户提供了更强大的易用性、灵活性、可扩展性以及效率,而不管他们选择何种商业智能(BI)工具。它能够定义一个利于分析的业务模型,并通过在后台自主构建和维护临时数据结构,透明地加速针对该模型运行分析查询时的工作负载。
索引通过维护常见请求数据的排序子集,提供了一种优化查询的机制。 确定哪些字段应该被索引需要一些思考:太少或错误的索引和关键查询将运行太慢; 太多的索引会降低插入和更新性能(因为必须设置或更新索引值)。
要确定添加索引是否会提高查询性能,请从管理门户SQL接口运行查询,并在性能中注意全局引用的数量。
添加索引,然后重新运行查询,注意全局引用的数量。
一个有用的索引应该减少全局引用的数量。
可以通过在WHERE子句或ON子句条件前使用%NOINDEX关键字来防止使用索引。
应该为联接中指定的字段(属性)编制索引。左外部联接从左表开始,然后查看右表;因此,应该为右表中的字段建立索引。在下面的示例中,应该为T2.f2编制索引:
FROM Table1 AS T1 LEFT OUTER JOIN Table2 AS T2 ON T1.f1 = T2.f2
内部联接应该在两个ON子句字段上都有索引。
执行“显示计划”,然后找到第一张map。
如果查询计划中的第一个项目是“Read master map”,或者查询计划调用的模块的第一个项目是“Read master map”,则查询的第一个映射是主映射,而不是索引映射。
因为主映射读取数据本身,而不是数据索引,这总是表明查询计划效率低下。
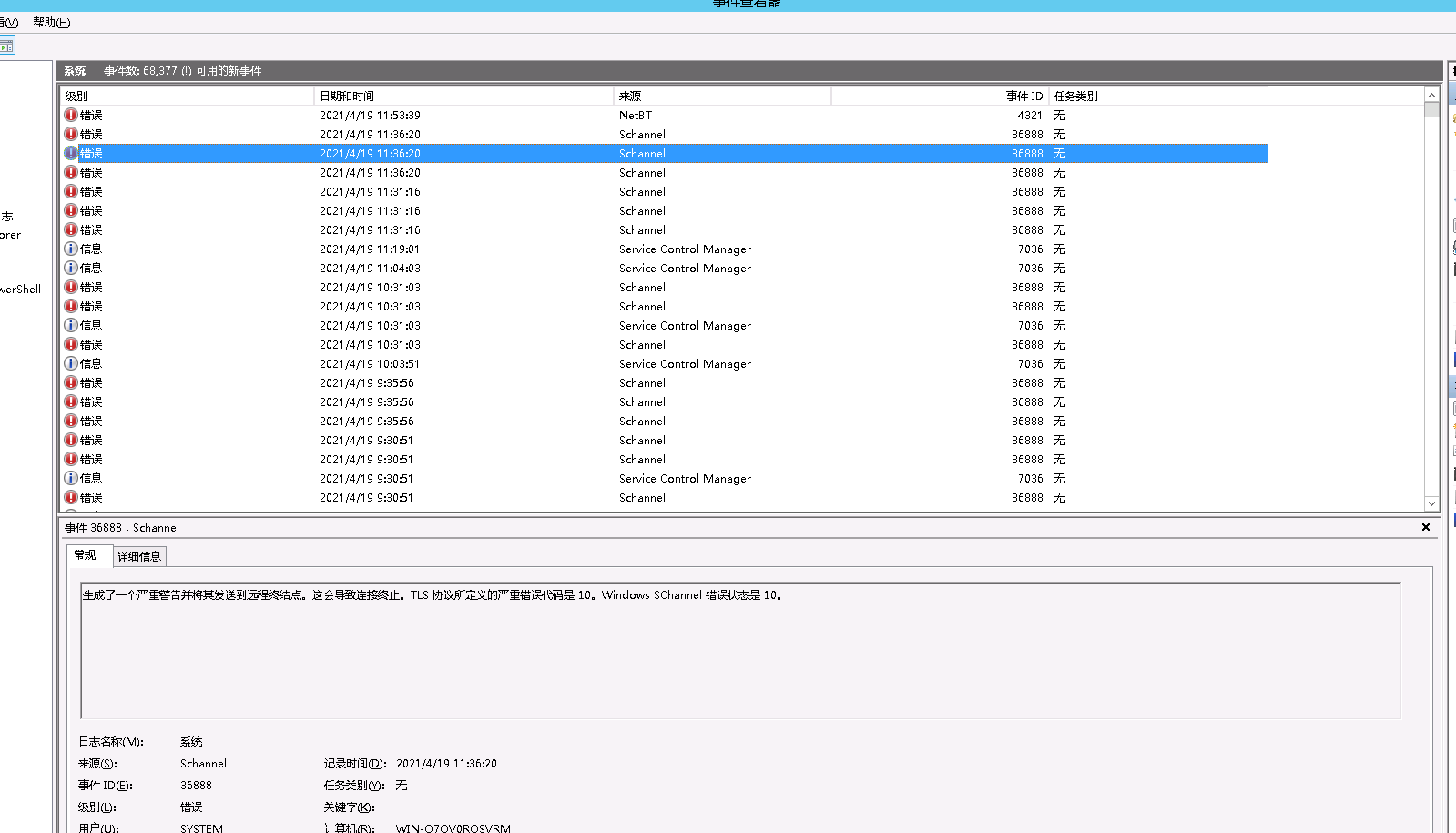
服务器操作系统频繁产生错误日志“生成了一个严重警告并将其发送到远程终结点。这会导致连接终止。TLS 协议所定义的严重错误代码是 10。Windows SChannel 错误状态是 10。” 想请问一下,这个错误信息是我们产品导致产生的问题吗?
InterSystems SQL自动使用查询优化器创建在大多数情况下提供最佳查询性能的查询计划。该优化器在许多方面提高了查询性能,包括确定要使用哪些索引、确定多个AND条件的求值顺序、在执行多个联接时确定表的顺序,以及许多其他优化操作。可以在查询的FROM子句中向此优化器提供“提示”。本章介绍可用于评估查询计划和修改InterSystems SQL将如何优化特定查询的工具。
InterSystems IRIS®Data Platform支持以下优化SQL查询的工具:
SQL Runtime Statistics用于生成查询执行的运行时性能统计信息EXPLAIN命令、$SYSTEM.SQL.ExPlan()方法以及管理门户和SQL Shell中的各种Show Plan工具。查询计划和统计数据是在准备查询时生成的,不需要执行查询。


