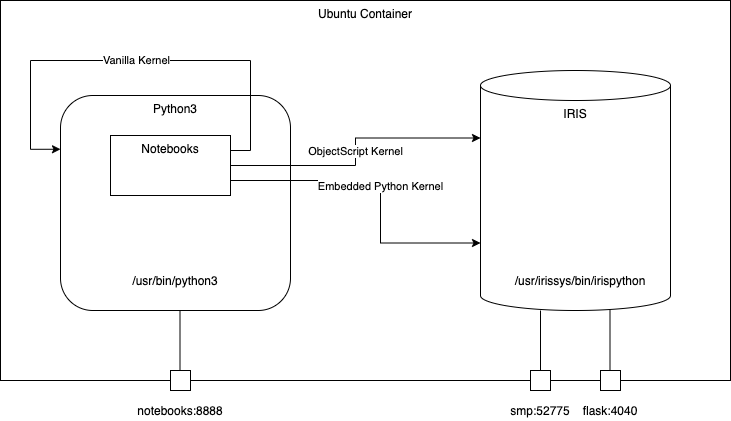
可以使用内嵌REST API用描述文件生成REST服务
请求消息如下:
POST: http://[YourServer]/api/mgmnt/v2/INTEROP/cmAPI
Body: API 描述文件,例如下面的Json文件
Basic Authorization Username: 用户名
Basic Authorization Password: 密码
Content-Type Header: application/json
** 注意**:调用接口前,需要创建相应命名空间,本示例为INTEROP
API 描述文件:
{
"swagger": "2.0",
"info": {
"description": "An API for coffee sales using InterSystems IRIS",
"version": "1.0.0",
"title": "Coffee Maker API",
"license": {
"name": "Apache 2.0",
"url": "http://www.apache.org/licenses/LICENSE-2.0.html"
}
},
"schemes": [
"https"
],
"paths": {
"/coffeemakers": {
"post": {
"description": "Returns all coffeemakers\n",
"operationId": "QueryAll",
"produces": [
"application/json"
],
"parameters": [],
"responses": {
"200": {
"description": "Success"
},
"500": {
"description": "Server error"
}
}
}
},
"/newcoffeemaker": {
"post": {
"description": "Add a new coffeemaker to the store. ID is autogenerated. Other info must be provided in the request body. Name and brand are required fields. Returns new coffeemaker\n",
"operationId": "NewMaker",
"produces": [
"application/json"
],
"parameters": [
{
"in": "body",
"name": "body",
"required": true,
"schema": {
"$ref": "#/definitions/CoffeeMaker"
}
}
],
"responses": {
"200": {
"description": "Success"
},
"400": {
"description": "Invalid message body"
},
"500": {
"description": "Server error"
}
}
}
},
"/coffeemaker": {
"post": {
"description": "Retrieve existing coffeemaker given ID and data. Returns coffeemaker\n",
"operationId": "QueryMaker",
"produces": [
"application/json"
],
"parameters": [
{
"name": "id",
"in": "query",
"description": "CoffeemakerID",
"required": true,
"type": "integer"
},
{
"name": "prod",
"in": "query",
"required": false,
"type": "boolean"
}
],
"responses": {
"200": {
"description": "Success"
},
"404": {
"description": "Coffeemaker not found"
},
"500": {
"description": "Server error"
}
}
},
"put": {
"description": "Update existing coffeemaker given ID and data. Returns updated coffeemaker\n",
"operationId": "EditMaker",
"produces": [
"application/json"
],
"parameters": [
{
"name": "id",
"in": "query",
"description": "CoffeemakerID",
"required": true,
"type": "integer"
},
{
"in": "body",
"name": "body",
"description": "coffeemaker info",
"required": true,
"schema": {
"$ref": "#/definitions/CoffeeMaker"
}
},
{
"name": "prod",
"in": "query",
"required": false,
"type": "boolean"
}
],
"responses": {
"200": {
"description": "Success"
},
"400": {
"description": "Invalid message body"
},
"404": {
"description": "Coffeemaker not found"
},
"500": {
"description": "Server error"
}
}
},
"delete": {
"description": "Delete existing cofffeemaker given ID. Returns deleted coffeemaker\n",
"operationId": "RemoveMaker",
"produces": [
"application/json"
],
"parameters": [
{
"name": "id",
"in": "query",
"description": "CoffeemakerID",
"required": true,
"type": "integer"
},
{
"name": "prod",
"in": "query",
"required": false,
"type": "boolean"
}
],
"responses": {
"200": {
"description": "Success"
},
"404": {
"description": "Coffeemaker not found"
}
}
}
}
},
"definitions": {
"CoffeeMaker": {
"type": "object",
"properties": {
"Name": {
"type": "string"
},
"Brand": {
"type": "string"
},
"Price": {
"type": "number"
},
"NumCups": {
"type": "integer"
},
"Color": {
"type": "string"
},
"Img": {
"type": "string"
}
}
}
}
} 首先,什么是数据匿名化?
首先,什么是数据匿名化?.png)