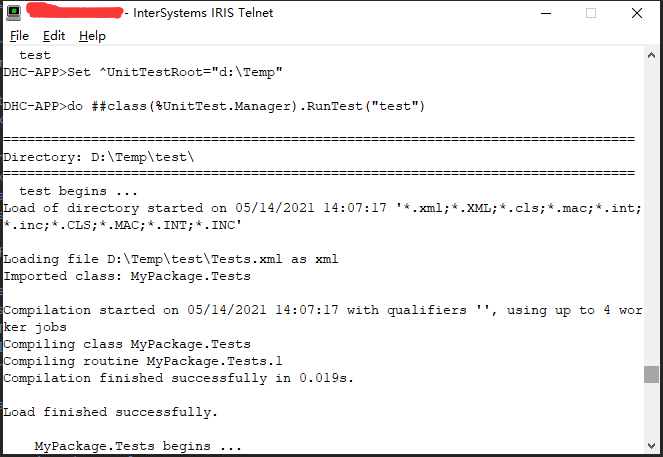
嗨,社区,
我正在尝试访问对象的另一个进程的内容,例如%request和%session。我正在使用类/方法“%SYS.ProcessQuery:VariableByPid”。有谁知道如何从数据库服务器上运行的一个进程中获取诸如%request.Data(“ ID”,1)之类的属性的值?
我想做的例子:
set rs=##class(%ResultSet).%New("%SYS.ProcessQuery:VariableByPid")
set tsc=rs.Execute(ProcessID,"%request")
while rs.%Next() {
w "Name:"_$g(rs.Data("Name")),!
w "Value:"_$g(rs.Data("Value")),!
}
do rs.Close()
Output:
Name:%request
Value:1@%CSP.Request
我只是可以看到对象引用1@%CSP.Request,我不确定我们是否有办法检查对象属性。
.png)

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f9VqwzNP-1608850948003)(3E1D939266954ED48BDAEA9B8086B11E)]](https://img-blog.csdnimg.cn/20201225070433434.png)