
InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
以下步骤展示如何显示 /api/monitor 服务提供的指标列表示例。
在上个帖子中,我概述了以 Prometheus 格式显示 IRIS 指标的服务。 该贴介绍了如何在容器中设置和运行 IRIS 预览版 2019.4,然后列出了指标。
本帖假定您已安装 Docker。 如果未安装,现在就为您的平台安装吧 :)
按照预览发行版的下载说明下载预览版许可证密钥和 IRIS Docker 映像。 例如,我选择了 InterSystems IRIS for Health 2019.4。
按照 Docker 容器中的 InterSystems 产品初见中的说明操作。 如果您熟悉容器,请跳转到标题为“下载 InterSystems IRIS Docker 映像”的部分。
以下终端输出说明了我用来加载 docker 映像的过程。 docker load 命令可能需要几分钟的时间才能运行;
$ pwd
/Users/myhome/Downloads/iris_2019.4
$ ls
InterSystems IRIS for Health (Container)_2019.4.0_Docker(Ubuntu)_12-31-2019.ISCkey irishealth-2019.4.0.379.0-docker.刚才好像发了一遍没成功
试用IRIS,关闭了workspace之后;再打开、没有project. 只能从打开最近的workspace中找,怎么回事噢?哈哈哈哈哈
亲爱的社区开发者们,大家好!
欢迎积极参与新一轮InterSystems开发者竞赛!
🏆 InterSystems 编程大赛:人工智能与机器学习 🏆
竞赛时间: 2021年6月28日 - 7月25日
奖金总额: $8,750

如果一张图片胜过千言万语,那么一段视频又价值几何? 当然胜过敲一个帖子。
请在 InterSystems Developers YouTube 观看我的“Coding talks”:
1. 使用 Yape 分析 InterSystems IRIS 系统性能。 第 1 部分:安装 Yape
在容器中运行 Yape。
2. Yape 容器 SQLite iostat InterSystems
提取和绘制 pButtons 数据,包括时间范围和 iostat。
供应商或内部团队要求说明如何为 VMware vSphere 上运行的_大型生产数据库_进行 CPU 容量规划。
总的来说,在调整大型生产数据库的 CPU 规模时,有几个简单的最佳做法可以遵循:
通常,这会引出几个常见问题:
我以下面的示例回答这些问题。 但也要记住,最佳做法并不是一成不变的。 有时需要做出妥协。 例如,大型生产数据库虚拟机很可能不适合 NUMA 节点,但我们会看到,其实是没问题的。 最佳做法是指必须针对应用程序和环境进行评估和验证的准则。
大家好, 在本文中,我比较了 Gartner 最新DBMS 魔力象限中的主要领先数据库产品的功能。 请见按现有功能数量排序的列表。 1. InterSystems IRIS 2020.3 - 60 个功能 (https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls) 2. Oracle Database 21c - 54 个功能 (https://docs.oracle.com/en/database/oracle/oracle-database/index.html) 3. Microsoft SQL Server - 45 个功能 (https://docs.microsoft.com/en-us/sql/sql-server/?view=sql-server-ver15) 4. AWS Aurora - PostgreSQL - 34 个功能 (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_Auror…) 我只比较了功能,未进行任何性能比较(关于此内容,请参见性能测试:https://cn.community.intersystems.
(ECP) Caché 出色的可用性和扩展特性之一是企业缓存协议 (ECP)。 在应用程序开发过程中,如对使用 ECP 的分布式处理加以考虑,可以横向扩展 Caché 应用程序的架构。 应用程序处理可以调整为非常高的速率,处理能力从单个应用程序服务器扩展到最多 255 个应用程序服务器,并且不需要任何应用程序更改。
在我参与的 TrakCare 部署中,ECP 已广泛使用多年。 十年前,主要供应商之一的一台“大型”x86 服务器可能总共只有八个核心。 对于大型部署来说,ECP 是横向扩展商业服务器处理能力的方式,不适合单台昂贵的大型企业服务器。 即使是高核心数的企业服务器也有限制,因此 ECP 也用于扩展这些服务器上的部署。
如今,大多数的新 TrakCare 部署或升级到当前硬件_不需要 ECP_ 即可扩展。 目前的双插槽 x86 生产服务器可以拥有数十个核心和巨大容量的内存。 我们看到,在最近的 Caché 版本中,TrakCare 以及许多其他 Caché 应用程序具有可预测的线性扩展能力,能够随着单台服务器中 CPU 核心数量和内存的增加而支持逐渐增多的用户和事务。 在现场,我看到大多数的新部署都是虚拟化的,即使如此,虚拟机也可以根据需要扩展到主机服务器的规模。 如果资源需求超过单个物理主机可以提供的资源,则使用 ECP 进行横向扩展。
下载网址:
https://hub.docker.com/r/yape/yape/
$ docker container run --rm -v "$(pwd)":/data yape/yape --version yape 2.2.6
在以下网址查看自述文件:
https://github.com/murrayo/yape
更改包括:
现在,GitHub 和容器保持同步。
注(2019 年 6 月):许多内容发生了变化,最新的详细信息请参见此处 注(2018 年 9 月):自本帖首次发布以来,内容已经有了很大改动,我建议使用 Docker 容器版本,以容器形式运行的项目以及详细信息仍然在 GitHub 的同一个地址发布,您可以下载、运行并根据需要进行修改。
与客户合作进行性能评估、容量规划和故障排除时,我经常解包和查看来自 pButtons 的 Caché 和操作系统指标。 我不久前发布了一个帖子,介绍了一个用来解包 pButtons 指标的实用工具(该实用工具使用 unix shell、perl 和 awk 脚本编写),而不是费力地浏览 html 文件,再将需要绘制的部分剪切并粘贴到 excel 中。 虽然这是一个有用的省时工具,但还不够完善... 我还使用脚本自动绘制指标图表,以便快速查看并包含在报告中。 但是,这些绘图脚本不容易维护,并且当需要站点特定的配置(例如 iostat 或 Windows perfmon 的磁盘列表)时会变得特别混乱,所以我从未公开发布过绘图实用工具。 不过我现在可以很高兴地说,已经有了简单得多的解决方案。
当我与 Fabian 一起在客户站点查看系统性能时,有了意外发现,他向我展示了使用实用的 Python 绘图模块所做的工作。
可以使用%XML.Node的以下方法。以检查当前节点的属性。
AttributeDefined() 如果当前元素具有具有给定名称的属性,则返回非零(TRUE)。FirstAttributeName() 返回当前元素的第一个属性的属性名称。GetAttributeValue() 返回给定属性的值。如果元素没有该属性,则该方法返回NULL。GetNumberAttributes() 返回当前元素的属性数。LastAttributeName() 返回当前元素的最后一个属性的属性名称。NextAttributeName() 在给定属性名称的情况下,无论指定的属性是否有效,此方法都会按排序顺序返回下一个属性的名称。PreviousAttributeName() 在给定属性名称的情况下,无论指定的属性是否有效,此方法都会按排序顺序返回上一个属性的名称。下面的示例遍历给定节点中的属性并编写一个简单报表:
/// d ##class(Demo.XmlDemo).ShowAttributes("<?xml version='1.0'?%XML.Document类和%XML.Node类使可以将任意XML文档表示为DOM(文档对象模型)。然后,可以导航此对象并对其进行修改。还可以创建一个新的DOM并将其添加到其中。
注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码,InterSystems IRIS将使用本书前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。
要打开现有XML文档以用作DOM,请执行以下操作:
%XML.Reader的实例。Format属性,以指定要导入的文件的格式。默认情况下, IRIS假定XML文件为文字格式。如果文件是SOAP编码格式,则必须指明这一点,以便可以正确读取该文件。
除非使用Correlate()和Next(),否则此属性无效。
%XML.Reader的以下方法之一。OpenFile() — 打开一个文件。OpenStream() —打开一个流。OpenString() — 打开字符串。OpenURL() — 打开URL。在每种情况下,都可以选择为该方法指定第二个参数,以重写Format属性的值。
Document属性,它是一个DOM。/// desc:灵活读取类
ClassMethod Read(mydir, myfile, class, element)
{
set reader=##class(%XML.Reader).%New()
if $extract(mydir,$length(mydir))'="/" {set mydir=mydir_"/"}
set file=mydir_myfile
set status=reader.OpenFile(file)
if $$$ISERR(status) {do $System.Status.DisplayError(status)}
do reader.Correlate(element,class)
while reader.Next(.object,.status)
{
if $$$ISERR(status) {do $System.Status.DisplayError(status)}
set status=object.%Save()
if $$$ISERR(status) {do $System.Status.DisplayError(status)}
}
}
请注意,当读入Person对象时,会自动读入其相应的Address对象。
默认情况下,next()方法不检查是否存在与标记为必需的属性相对应的元素和属性。要使读取器检查此类元素和属性是否存在,请在调用Next()之前将读取器的CheckRequired属性设置为1。出于兼容性原因,此属性的默认值为0。
如果将CheckRequired设置为1,并且调用next(),而导入的XML缺少必需的元素或属性,则next()方法会将sc参数设置为错误代码。例如:
SAMPLES>set next= reader.Next(.object,.status)
SAMPLES>w next
0
SAMPLES>d $system.Status.DisplayError(status)
ERROR #6318: Property required in XML document: ReqProp
由于源XML文档可能包含意外的元素和属性,因此%XML.Adaptor提供参数来指定导入此类文档时的反应方式。
为对象启用XML时,需要指定将空值和空字符串投影到XML的方式
其中一个选项是在支持XML的类中将XMLIGNORENULL设置为等于“Runtime”(不区分大小写)。在这种情况下,当使用%XML.
https://openexchange.intersystems.com/package/sql-rest-api
https://openexchange.intersystems.com/package/ObjectScript-Package-Mana… (ZPM is the most useful tool for installing Open Exchange Applications
https://openexchange.intersystems.com/package/zpm-registry This will show you a list of OEX apps that are zpm ready
https://github.com/robtweed/qewd
but also look at the QEWD-related postings I've put in here on Open Exchange:
https://openexchange.intersystems.com/package/QEWD-js
https://openexchange.intersystems.com/package/qewd-jsdb-kit-iris
本章介绍如何使用%XML.Reader将XML文档导入到 IRIS对象中。
注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码, IRIS将使用前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。
还可以使用%XML.Reader读取任意XML文档并返回DOM(文档对象模型)。
IRIS提供了一些工具,用于读取XML文档并创建与该文档的元素相对应的启用XML的 IRIS对象的一个或多个实例。基本要求如下:
%XML.Adaptor。除了少数例外,该对象引用的类还必须扩展%XML.Adaptor。提示:如果相应的XML模式可用,可以使用它来生成类(以及任何支持的类)。
%XML.Reader的实例,然后调用该实例的方法。这些方法指定XML源文档,将XML元素与启用XML的类相关联,并将源中的元素读取到对象中。%XML.Reader使用类中的%XML.Adaptor提供的方法执行以下操作:
InterSystems非常高兴地宣布,InterSystems IRIS数据平台、InterSystems IRIS for Health和HealthShare Health Connect的2021.1版本现已向我们的客户和合作伙伴全面开放。
这个版本的为开发者提供了更大的自由度,使他们可以用自己选择的编程语言在服务器端和客户端建立快速和强大的应用程序。这个版本还使用户能够通过新的和更快的分析能力更有效地消费大量的信息。
方法的作用是:以规范化的形式编写XML节点。此方法具有以下签名:
method Canonicalize(node As %XML.Node, ByRef PrefixList, formatXML As %Boolean = 0) as %Status
node是文档的一个子树,作为%XML.Node的实例。PrefixList是以下其中之一:
PrefixList指定为“c14n”。
在本例中,输出的形式是XML Canonicalization Version 1.0,由https://www.w3.org/TR/xml-c14n。PrefixList指定为具有以下节点的多维数组:| Node | Value |
|---|---|
PrefixList(前缀),其中前缀是名称空间前缀 |
与此名称空间前缀一起使用的名称空间 |
FormatXML控制格式。如果format XML为true,则编写器使用为编写器实例指定的格式,而不是XML规范化规范指定的格式。因此,输出不是规范的XML,但是已经对规范的XML进行了命名空间处理。本帖概述了通过为 InterSystems 数据平台(InterSystems IRIS、Caché 和 Ensemble)上的数据库磁盘创建 LVM 物理盘区 (PE) 条带来实现低延迟存储 IO 的最佳实践配置,并提供了有用链接。
一致的低延迟存储是获得最佳数据库应用程序性能的关键。 例如,对于在 Linux 上运行的应用程序,经常在数据库磁盘中使用逻辑卷管理器 (LVM) ,因为它能够扩展卷和文件系统,或者为在线备份创建快照。 对于数据库应用程序,在使用 LVM PE 条带化逻辑卷的情况下,并行写入还可提高数据 I/O 的效率,从而有助于提高大规模连续读取和写入的性能。
如将对象投射到XML中所述,可以将类分配给名称空间,以便相应的XML元素属于该名称空间,还可以控制类的属性是否也属于该名称空间。
将类中的对象导出为XML时,%XML.Write提供其他选项,例如指定元素是否为其父级的本地元素。本节包括以下主题:
%XML.Writer如何处理命名空间注意:在InterSystems IRIS XML支持中,可以按类指定名称空间。通常,每个类都有自己的命名空间声明;但是,通常只需要一个或少量的命名空间。还可以在逐个类的基础上指定相关信息(而不是以某种全局方式)。这包括控制元素是否为其父元素的本地元素以及子元素是否合格的设置。为简单起见,建议使用一致的方法。
若要将启用XML的类分配给命名空间,请设置该类的Namespace参数,如将对象投影到XML中所述。在%XML.Writer会自动插入命名空间声明,生成命名空间前缀,并在适当的地方应用前缀。例如,以下类定义:
Class GXML.Objects.WithNamespaces.Person Extends (%Persistent, %Populate, %XML.如果使用RootElement()启动文档的根元素,则负责生成该根元素内的每个元素。有三个选择:
可以从InterSystems IRIS对象生成输出作为元素。在本例中,使用object()方法,该方法写入支持XML的对象。输出包括该对象中包含的所有对象引用。可以指定此元素的名称,也可以使用在对象中定义的默认值。
只能在RootElement()和EndRootElement()方法之间使用object()方法。
此示例为给定启用XML的类的所有已保存实例生成输出:
/// desc:将表里数据输出本地文件里
/// w ##class(PHA.TEST.Xml).WriteAll("Sample.Person")
ClassMethod WriteTableAllToXml(cls As %String = "", directory As %String = "E:\temp\")
{
if '##class(%Dictionary.CompiledClass).%ExistsId(cls) {
Write !, "类不存在或未编译"
Quit
}
s check=$classmethod(cls, "%Extends", "%XML.在%XML.Writer会自动插入命名空间声明,生成命名空间前缀,并在适当的地方应用前缀。例如,以下类定义:
Class Sample.Person Extends (%Persistent, %Populate, %XML.Adaptor)
{
Parameter NAMESPACE = "http://www.yaoxin.com";
}
如果导出此类的多个对象,则会看到类似以下内容:
DHC-APP> w ##class(Demo.XmlDemo).Obj2Xml(1)
<?xml version="1.0" encoding="UTF-8"?>
<Person xmlns="http://www.yaoxin.com">
<Name>yaoxin</Name>
<SSN>111-11-1117</SSN>
<DOB>1990-04-25</DOB>
<s01:Home xmlns="" xmlns:s01="http://www.yaoxin.若要指定要在输出文档中使用的字符集,可以设置Writer实例的Charset属性。选项包括“UTF-8”、“UTF-16”以及InterSystems IRIS支持的其他字符集。
XML文件的序言(根元素之前的部分)可以包含文档类型声明、处理指令和注释。
在writer实例中,以下属性会影响prolog:
控制两件事:XML声明中的字符集声明和(相应的)输出中使用的字符集编码。
控制输出是否包含XML声明。在大多数情况下,默认值是0,这意味着已经编写了声明。如果没有指定字符集,并且输出定向到字符串或字符流,则默认为1,并且不写入任何声明。
在根元素之前,可以包含文档类型声明,该声明声明了文档中使用的模式。
要生成文档类型声明,需要使用WriteDocType()方法,该方法有一个必选参数和三个可选参数。
就本文档而言,文档类型声明包括以下可能的部分:
<!DOCTYPE doc_type_name external_subset [internal_subset]>
如这里所示,文档类型有一个名称,根据XML规则,该名称必须是根元素的名称。 声明可以包含外部子集、内部子集或两者。
Hi colleagues!
Is there a way to export globals in XML if I have the access to Management Portal or any other web app?
Currently, it gives the option to export into gof format only.
Hi 同事们好!
是否有办法通过管理门户或任何其他的web app以XML的形式导出globals?
目前,它只提供了导出为gof格式的选项。
本章介绍如何从InterSystems IRIS对象生成XML输出。
InterSystems IRIS提供了用于为InterSystems IRIS对象生成XML输出的工具。可以指定XML投影的详细信息,如将对象投影到XML中所述。然后创建一个Writer方法,该方法指定XML输出的整体结构:字符编码、对象的显示顺序、是否包括处理指令等。
基本要求如下:
如果需要特定对象的输出,则该对象的类定义必须扩展%XML.Adaptor。除了少数例外,该对象引用的类还必须扩展%XML.Adaptor。
输出方法必须创建%XML.Writer的实例,然后使用该实例的方法。
下面的终端会话显示了一个简单的示例,在该示例中,我们访问启用了XML的对象并为其生成输出:
/// d ##class(Sample.Person).Populate(100)
/// w ##class(PHA.TEST.Xml).Obj2Xml(1)
ClassMethod Obj2Xml(ID)
{
s obj = ##class(Sample.Person).%OpenId(ID)
s xml = ##class(%XML.Writer).%New()
s xml.Indent=1
s status = xml.介绍了如何使用 IRIS XML工具。
InterSystems IRIS为XML处理带来了对象的力量--可以使用对象作为XML文档的直接表示,反之亦然。由于InterSystems IRIS包括本机对象数据库,因此可以将此类对象直接用于数据库。此外,InterSystems IRIS提供了用于处理XML文档和DOM(文档对象模型)的工具,即使它们与任何InterSystems IRIS类无关。
有些InterSystems IRIS XML工具主要用于支持XML的类。要为类启用XML,需要将%XML.Adaptor添加到其超类列表中。%XML.Adaptor类使能够将该类的实例表示为XML文档。可以添加类参数和属性参数来微调投影。
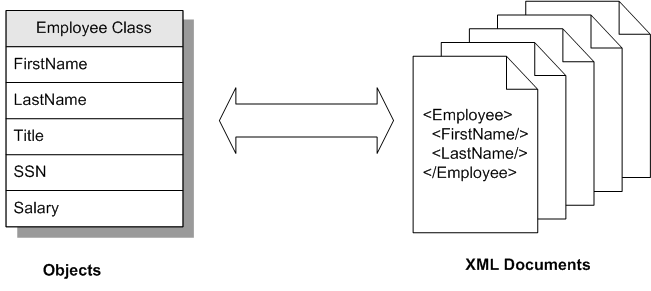
对于启用了XML的类,数据可以采用以下所有形式:
XML文档中,可以是文件、流或其他文档。DOM(文档对象模型)中。下图概述了用于在这些表单之间转换数据的工具:
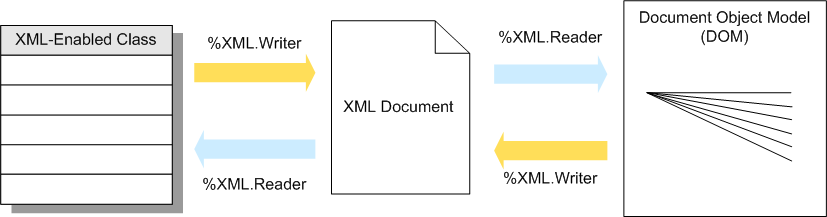
%XML.Writer类使能够创建XML文档。输出目的地通常是文件或流。确定要包括在输出中的对象,系统根据在类定义中建立的规则生成输出。
%XML.Reader类使能够将合适的XML文档导入到类实例中。
.png)
这是一个系列的第一篇文章。我将使用bpmn符号提供细节,如何开发、部署、保护、运营和消费IRIS数字服务,并与IRIS文档相联系。每一个子流程都将用一个单独的bpmn图来描述。这就是宏观过程。
Documentation links:
1. https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_data_science
2. https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=D2GS
3. https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_rest_json, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_soap
4. https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_multimodel
5. https://docs.intersystems.com/irislatest/csp/docbook/Doc.
%JSON快速参考本节提供本章中讨论的%JSON方法、属性和参数的快速参考。
%JSON.Adaptor方法这些方法提供了从JSON序列化和序列化到JSON的能力。
%JSON.Adaptor.%JSONExport()将启用JSON的类序列化为JSON文档,并将其写入当前设备。
method %JSONExport(%mappingName As %String = "") as %Status
%mappingName(可选)-要用于导出的映射的名称。基本映射由"" 表示,并且是默认映射。%JSON.Adaptor.%JSONExportToStream()将启用`JSON的类序列化为JSON文档并将其写入流。
method %JSONExportToStream(ByRef export As %Stream.Object,
%mappingName As %String = "") as %Status
export - 包含序列化的JSON文档的导出流。%mappingName(可选)-要用于导出的映射的名称。基本映射由""表示,并且是默认映射。%JSON.Adaptor.
JSON适配器是一种将ObjectScript对象(registered, serial or persistent)映射到JSON文本或动态实体的方法。本章涵盖以下主题:
JSON的对象并演示%JSON.Adaptor导入和导出方法JSON字段的属性参数。JSON-演示如何使用%JSON.ForMatter格式化JSON字符串。%JSON快速参考-提供本章中讨论的每个%JSON类成员的简要说明。从JSON序列化或序列化到JSON的任何类都需要子类%JSON.Adaptor,它包括以下方法:
%JSONExport()将启用JSON的类序列化为JSON文档,并将其写入当前设备。%JSONExportToStream()将启用JSON的类序列化为JSON文档并将其写入流。%JSONExportToString()将启用JSON的类序列化为JSON文档并将其作为字符串返回。%JSONImport()将JSON作为字符串或流导入,或者作为%DynamicAbstractObject的子类导入,并返回启用JSON的类的实例。之所以称为Dynamic,是说这个对象在代码编译的时候可以不定义对象的属性和结构,在runtime时才根据装入的数据来产生对象定义。IRIS里用Dynamic Object来处理JSON数据。简单说: 先定义一个Dynamic Object, 把JSON数据装进去,然后用对象的方式处理JSON文档。
让我们看看是它是怎么工作的。
创建一个Dynamic Object很简单, 标准而且啰嗦的写法是:
set dynObject1 = ##class(%DynamicObject).%New()
大家通常用简单的写法,像这样用一个{}来定义Dynamic Object:
DEMO>set dynObject1 = {}
DEMO>zw dynObject1
dynObject1={} ;
把JSON数据从字符串或者流导入DynamicObject被称作Deserializing;反之,把DynamicObject里的JSON导出来到String或者Stream叫Serializing。在类%DynmicObject中用的是%FromJSON()和%ToJSON()两个方法,一个是类方法,一个是实例方法:
//从字符串,流里导入数据到%DynmicObject。