按日期
按日期适用于 InterSystems IRIS® 数据平台、InterSystems IRIS® for HealthTM 和 HealthShare® Health Connect 的维护版本 2024.1.4 和 2023.1.6 现已正式发布 (GA)。 这些版本包含对最近发布的以下提醒的修复 - 提醒:SQL 查询返回错误结果 | InterSystems。 请通过开发者社区分享您的反馈,以便我们可以共同打造更出色的产品。

InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
.png)
 Open Exchange app
Open Exchange app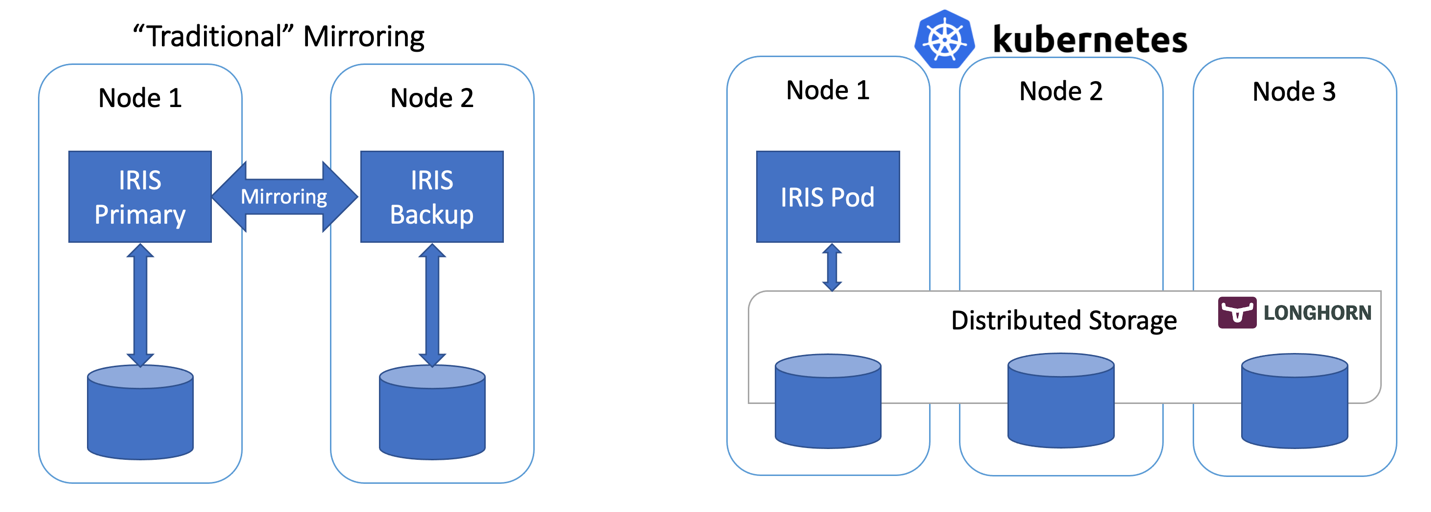
.png)
.png)
.png)
.png)