 按更新时间
按更新时间第二十七章 S 开头的术语
存储接口 (storage interface)
对象(Objects)
使用自定义存储或编写自己的存储类时必须实现的一组方法。
存储策略 (storage strategy)
对象(Objects)
类使用的存储策略在编译时评估为存储定义,决定数据的存储方式。
存储过程 (stored procedure)
SQL
存储过程允许你从 ODBC 或 JDBC 执行查询或类方法。
流接口 (stream interface)
对象(Objects)
IRIS 流接口用于在 ObjectScript、SQL 和 Java 中操作流。
流 (stream)
对象(Objects)
.png)
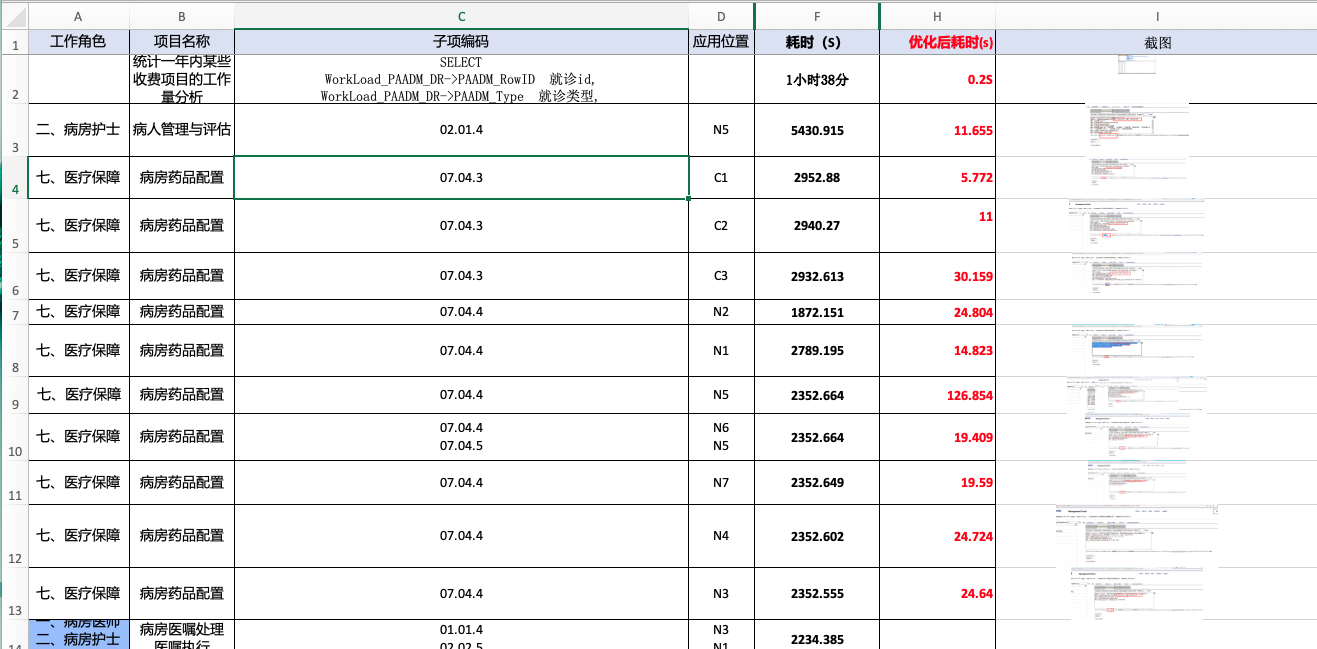
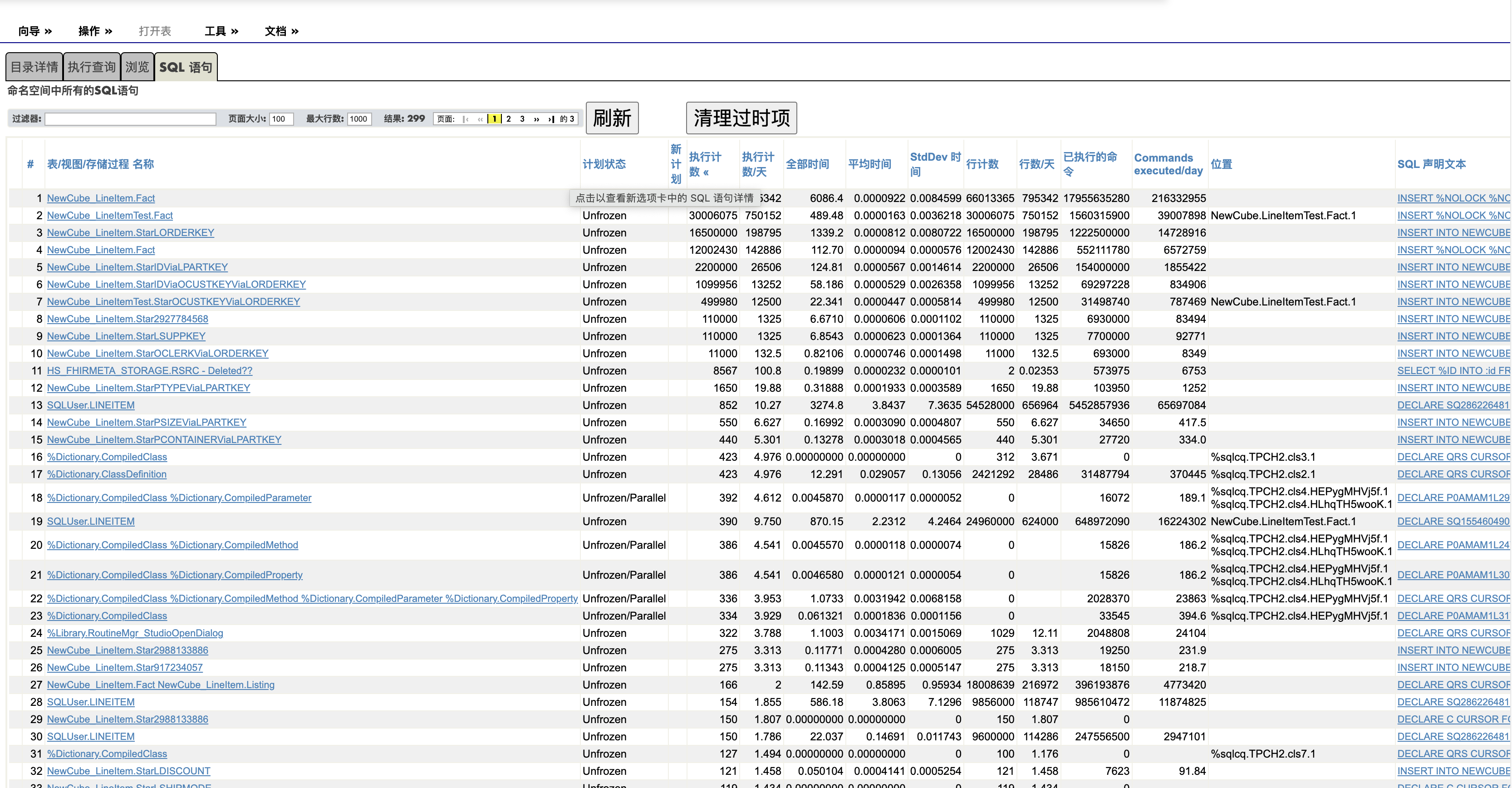
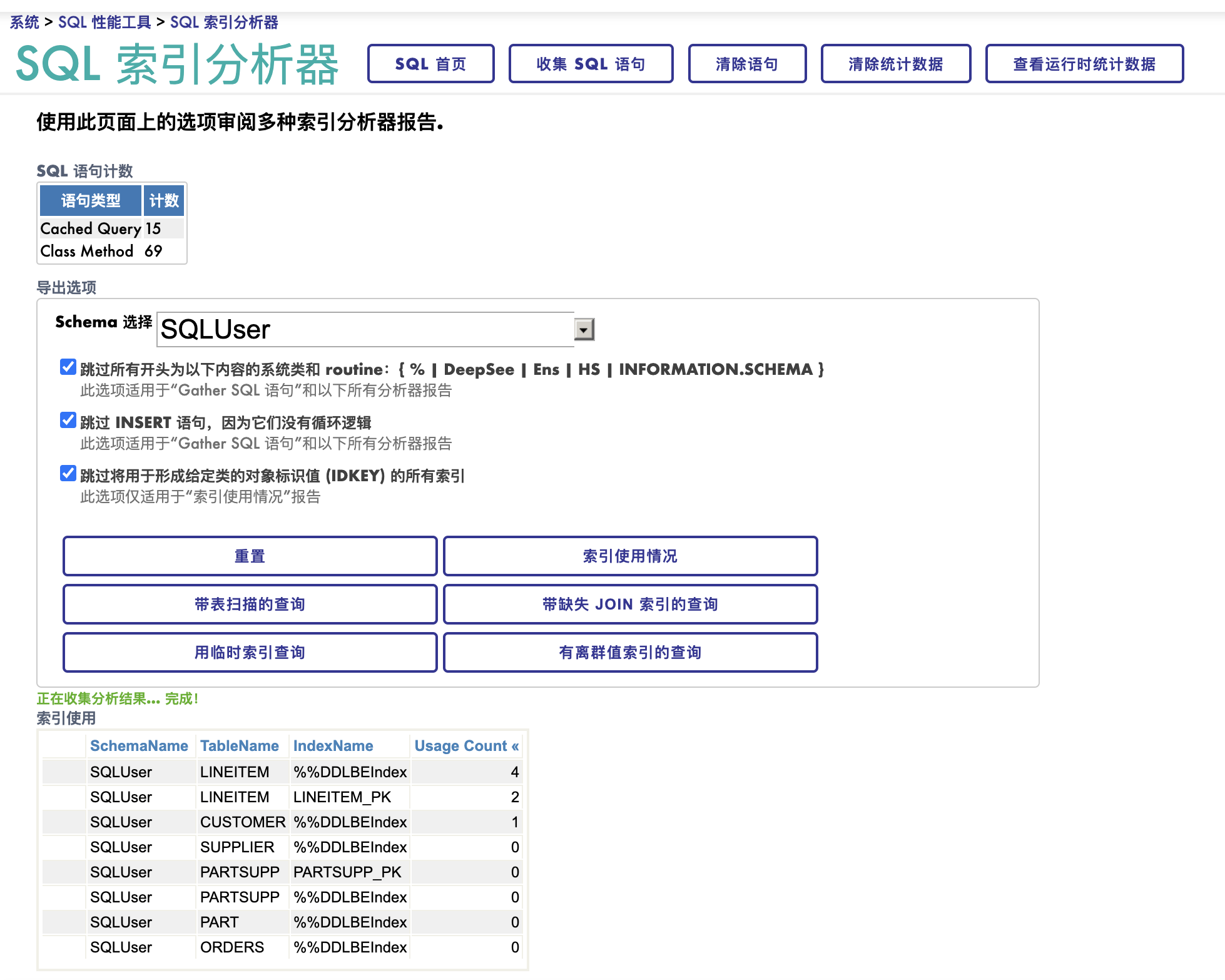
.png)
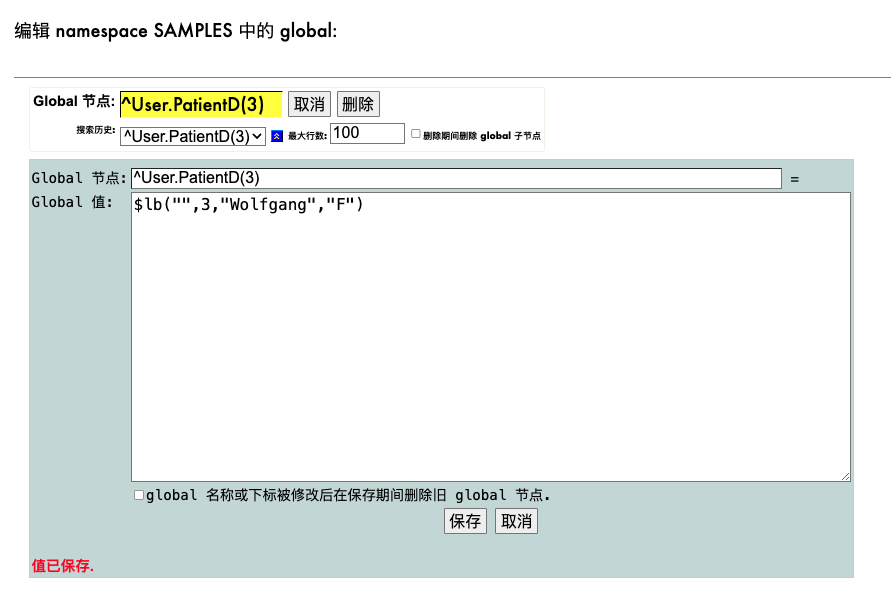
.png)