.png)
FHIR® SQL Builder或 Builder 是 InterSystems IRIS 医疗版数据平台 的一个组件。它是一种复杂的投射工具,用于将 InterSystems IRIS 医疗版数据平台FHIR 存储库中的数据创建为自定义的 SQL 模式,而无需将数据移动到单独的 SQL 存储库中。 Builder 专门设计用于与 InterSystems IRIS 医疗版数据平台中的 FHIR 存储库和多模型数据库配合使用。
Builder 的目标是使数据分析师和商业智能开发人员能够使用熟悉的SQL分析工具使用 FHIR,而无需学习新的查询语法。 FHIR 数据以复杂的有向图编码,无法使用标准 SQL 语法进行查询。基于图的查询语言 FHIRPath 旨在查询 FHIR 数据,但它是非关系型的。 Builder 使数据管理员能够使用表、列和索引创建其 FHIR 存储库的自定义 SQL 来投射,使数据分析师能够查询 FHIR 数据,而无需学习 FHIRPath 或 FHIR 搜索语法的复杂性。
存储库将加载 FHIR 资源,您所需要做的就是配置 FHIR SQL BUILDER。
对于配置,导航到http://localhost:55037/csp/fhirsql/index.
.png)
.png)

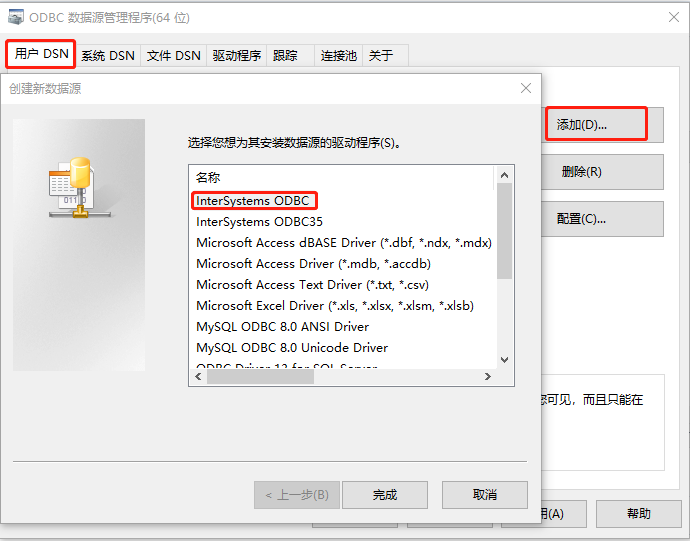
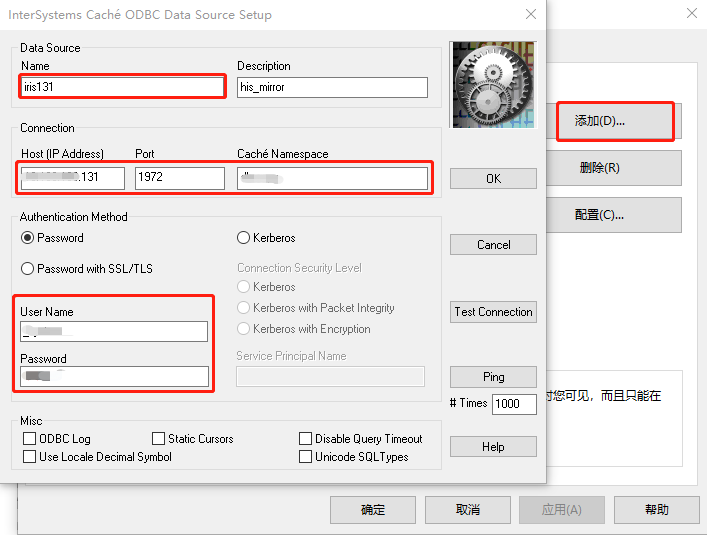

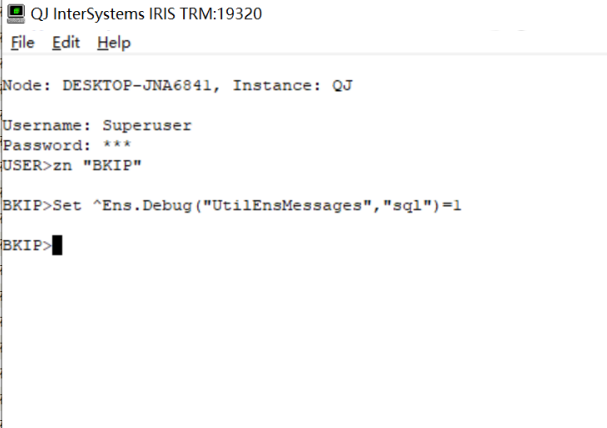
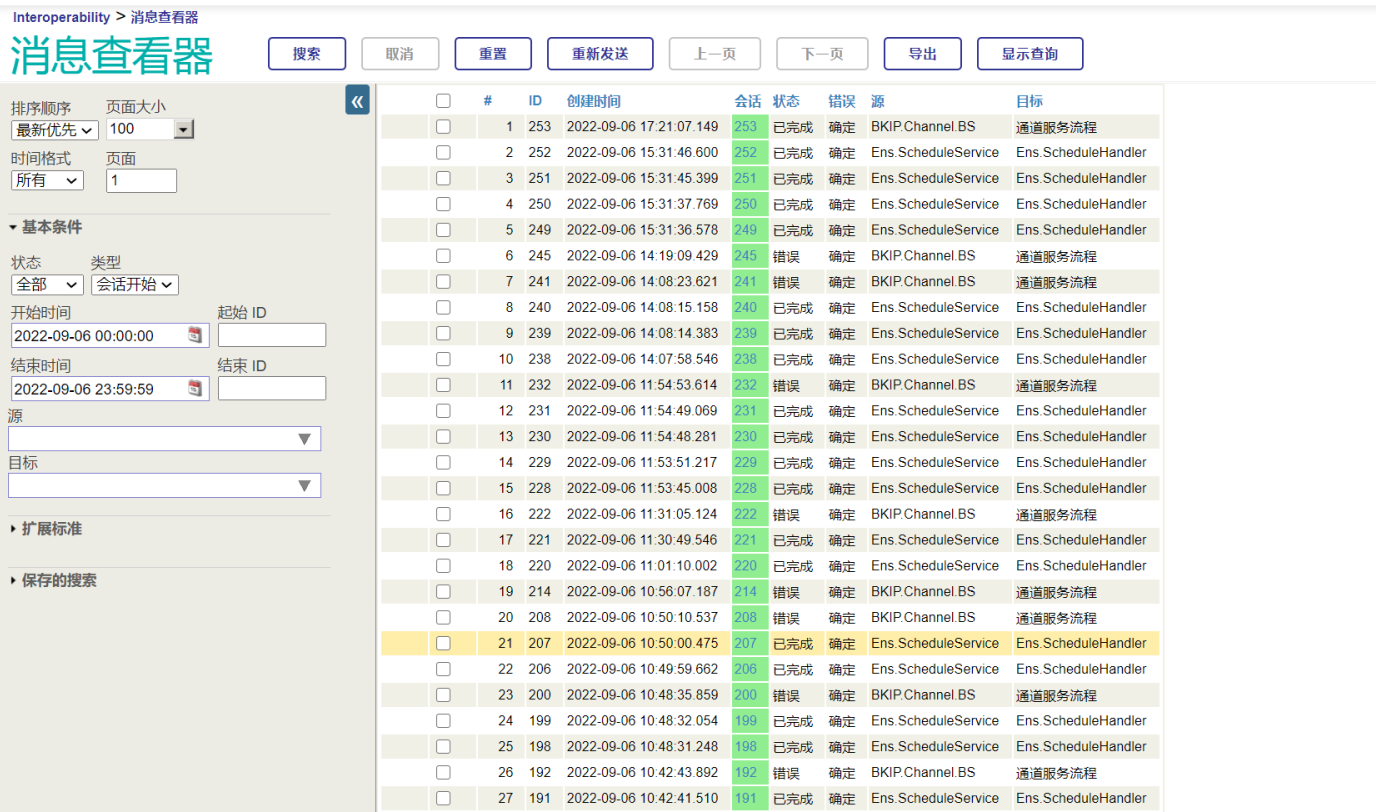
.png)