按更新时间
按更新时间第五十一章 使用 ^SystemPerformance 监视性能 - Apple macOS 平台的 InterSystems IRIS 性能数据报告
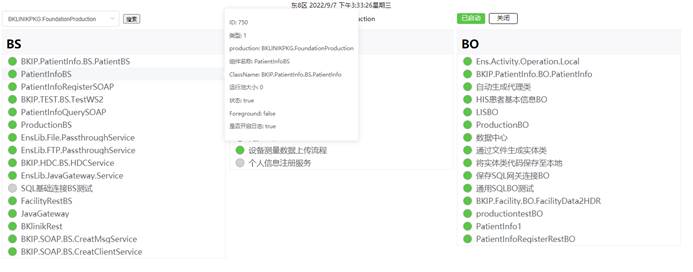
%SS- 使用ALL^%SS命令在运行过程中采集了四个样本。Configuration *- 来自服务器的IRIS实例名称和主机名、完整的IRIS版本字符串、许可客户名称和许可订单号。cpf file *- 当前活动配置文件的副本。-
irisstat -c- 使用命令irisstat cache -p-1 -c-1 -e1 -m8 -n2 -N127在运行过程中以均匀的间隔采集四个样本。以下是对每个参数的简要说明:
.png)
 Open Exchange app
Open Exchange app