cache到iris的变化中,常用命令的变动有没有归纳的地方
ccontrol start —— iris start
比如在cache中d ^pButtons,但是在IRIS中就无法使用
cache到iris的变化中,常用命令的变动有没有归纳的地方
ccontrol start —— iris start
比如在cache中d ^pButtons,但是在IRIS中就无法使用
今天,我发布了一个新的Open Exchange 软件包,用于直接在 IRIS 中生成合成数据。
当你想制作一个演示应用程序时,找到合适的数据集是一个令人沮丧的过程。也许数据集并不那么重要,但您仍然希望它看起来有点真实,并有几个链接表,可以直接在 IRIS 中使用 -> 的隐式连接。也许您只是想让链接表可以很容易地安装到 IPM 中,用于基准查询,那么这种数据集生成方式就再好不过了。
我选择使用嵌入式 Python 创建数据集,这些数据集可通过自定义配置文件进行配置。这些数据集直接用一个 IRIS 类方法生成,并可使用乘数进行缩放,以创建任意大小的数据集,而无需测量配置。
目前我有四个数据集:
- 金融服务(如银行卡、账户、交易)
- 零售(商店、产品、用户、库存)
- 供应链(产品、销售订单、库存移动)
- 主题公园管理(公园、区域、游乐设施、事故)
我不是这些领域的专家,所以我怀疑它们是否超级准确,而且数据生成使用了 faker 等 python 库,统计加权生成使用了 numpy,所以感觉有点人工合成。
老实说,作为一个我无法投入大量时间的副业项目,这个项目的成功离不开人工智能。我在设计数据集和生成创建数据集的代码时广泛使用了人工智能。我监督、测试了个人使用的案例,并积极参与了项目设计,但代码都是人工智能生成的,我没有仔细审查过数据集的生成过程。
本演示将带你体验 IRIS SQL 全新的表分区(Table Partitioning)功能,并沿途讲解其作用与工作原理。
为了验证概念,我们仅使用几十条数据进行演示。但显而易见,该功能的真正威力在于应对体量高出数个数量级的海量数据集。
💡 想要更简短、高屋建瓴的介绍?
不妨查看在线学习模块:Managing Tables with Partitioning in InterSystems IRIS
ℹ️ 表分区(Table Partitioning)功能已作为实验性功能包含在 IRIS 2026.1 中。
为了获得最佳的表分区体验,请注册 InterSystems Early Access Program (EAP)。加入 EAP 后,你将获得:许可证密钥、更新说明、与表分区团队更直接高效的沟通渠道。你的反馈对我们至关重要:我们越了解你希望如何使用表分区,就越能针对性地改进它。在注册Early Access Programs 的同时,也欢迎关注涵盖其他激动人心新功能的早期访问计划!
表分区允许用户依据特定的逻辑规则,将大表中的数据拆分存储到多个数据库中,从而实现高效的管理。
在上一篇文章中, 我谈到了(iris-copilot),这是一种在不久的将来,任何人类语言都可以成为任何机器、系统或产品的编程语言的愿景。它的代理运行程序实际上就是在使用这种所谓的第三代Agent。为了自己的方便,我也想保留/分享一份关于它是什么的详细记录。我在最近的谈话中多次提到过这个问题,所以也许值得一记。
我们正在见证人工智能代理的世代飞跃,这几乎是巧合。
在过去的四年里,人工智能行业已经经历了三代不同的代理技术--每一代都不仅仅代表着渐进式的改进,而是我们对人工智能系统在实际工作中的思考模式的根本性转变。第一代为我们提供了信息(information)。第二代给了我们协调(orchestration)。第三代技术--我称之为 "线束工程"(Harness Engineering)--给我们带来了质的不同:信任。
这种转变最明显的证据是什么?这是在一个 npm 软件包中意外发布的。
2026 年 3 月 31 日,Anthropic 发布了 @anthropic-ai/claude-code v2.1.88 的例行 npm 更新。一个丢失的 .npmignore
高级工程的定义不在于代码量的多少,而在于策略性地避免代码量。在复杂的集成环境中,倾向于利用通用库来满足每一个细分需求会带来不必要的开销。要实现真正的架构成熟,就必须致力于 "最小化工具"--优先考虑有弹性、经过实战检验的系统实用程序,而不是自定义逻辑。本评估将检查我们的 PGP 加密/解密流水线,以展示如何从应用级库转向操作系统本地授权,从而提高系统的耐用性。
我们当前的 MPHP.HS.PGPUtil 类是一种高摩擦设计。现有的 InterSystems IRIS 业务流程虽然功能强大,但依赖性很强。通过桥接嵌入式 Python 来使用 pgpy 库,我们引入了一个 "重型 "堆栈,需要 Python 运行时、第三方库管理和特定的加密二进制文件。
经常有客户就内存大小问题与我联系,因为他们会收到 "可用内存 "低于阈值的警报,或者发现 "可用内存 "突然减少。出现问题了吗?他们的应用程序会不会因为运行系统和应用程序进程的内存不足而停止工作?答案几乎总是否定的,没有什么好担心的。但这个简单的答案通常是不够的。请看下图。它显示的是 vmstat 中 free 指标的输出。还有其他方法可以显示系统的可用内存,例如 free -m 命令。有时,_free 内存_会随着时间的推移而逐渐消失。然而,下图是一个极端的例子,但它很好地说明了发生了什么。 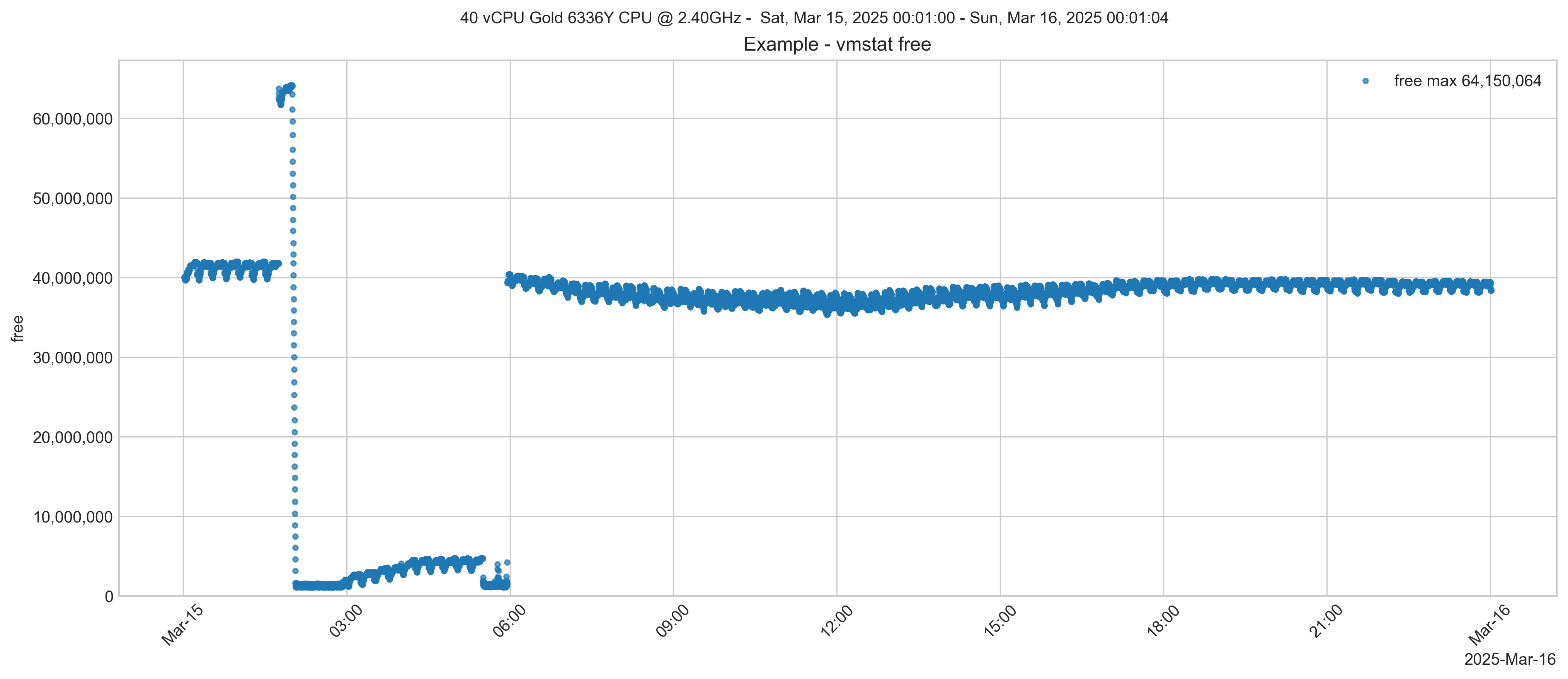 如你所见,在凌晨 2 点左右,一些内存被释放,然后突然下降到接近零。该系统正在 InterSystems IRIS 数据库上运行 IntelliCare EHR 应用程序。vmstat "信息来自一个收集 "vmstat"、"iostat "和许多其他系统指标的"^SystemPerformance "HTML文件。这个系统还发生了什么?现在是半夜,医院里应该没什么事。让我们看看数据库卷的
如你所见,在凌晨 2 点左右,一些内存被释放,然后突然下降到接近零。该系统正在 InterSystems IRIS 数据库上运行 IntelliCare EHR 应用程序。vmstat "信息来自一个收集 "vmstat"、"iostat "和许多其他系统指标的"^SystemPerformance "HTML文件。这个系统还发生了什么?现在是半夜,医院里应该没什么事。让我们看看数据库卷的 iostat 情况。 在_free memory_下降的同时,出现了一阵读取。报告的 free memory 下降与数据库磁盘的 中显示的大量块大小读取(2048 KB 请求大小)的峰值一致。这很可能是备份过程或文件复制操作
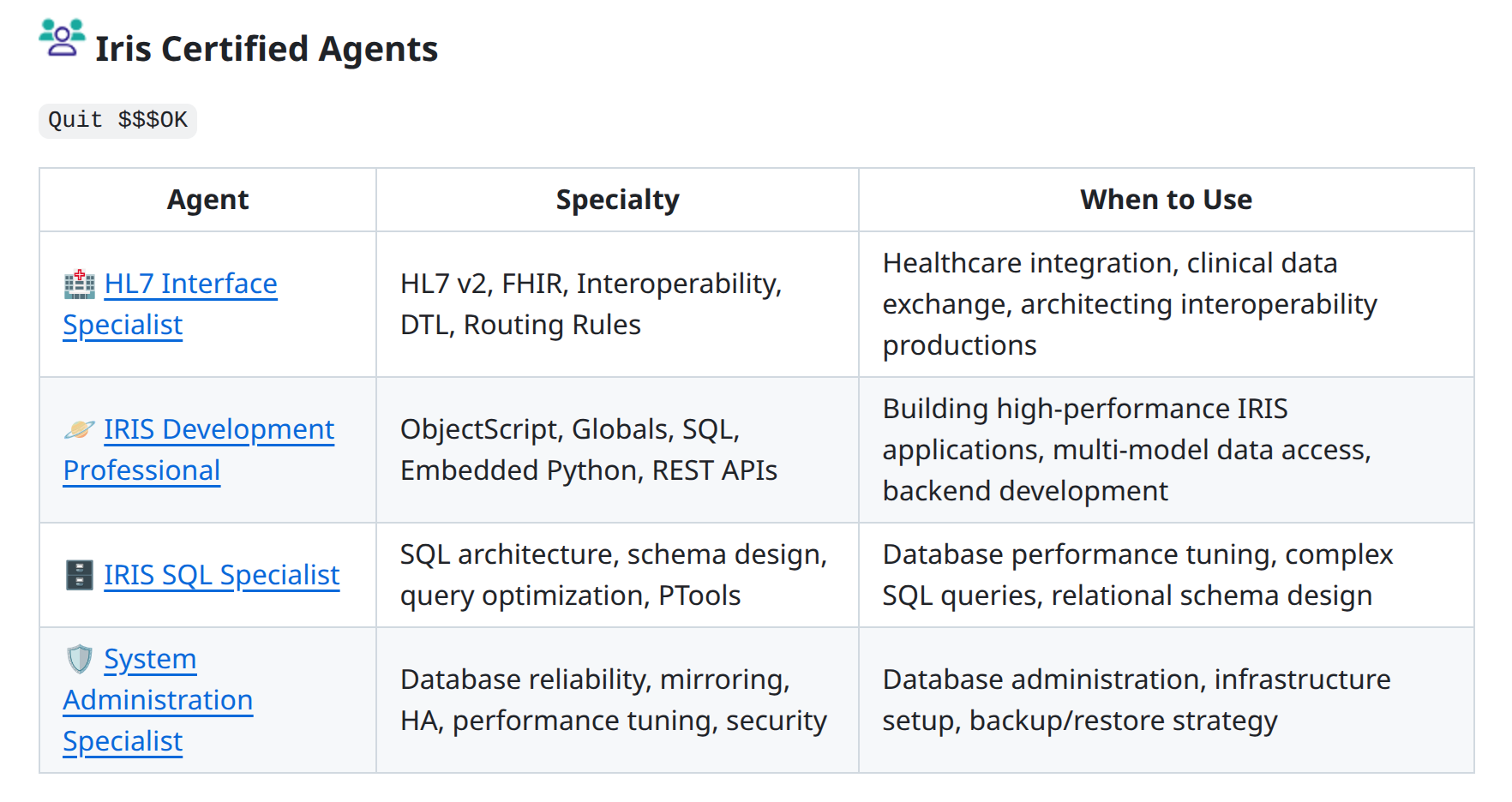
正在备考 InterSystems 认证?裁员裁掉了整个团队,却需要对 AI 赋能工作负载的承诺负责?刚接触 InterSystems 产品,或者正在基于 InterSystems 技术构建初创公司?那就 onboard 这些与你的模型和智能体 IDE 兼容的 InterSystems 智能体吧,让它们像协议机器人(Protocol Droid)一样流利地“说” InterSystems 技术。
# 将所有智能体安装到你的 Claude Code 目录
./scripts/install.sh --tool claude-code# 步骤 1 -- 为所有支持的工具生成集成文件
./scripts/convert.sh
# 步骤 2 -- 交互式安装(自动检测你已安装的工具)
./scripts/install.sh --tool antigravity
./scripts/install.sh --tool gemini-cli
从 Oracle、MSSQL 或其他纯关系型数据库系统迁移到多模型 InterSystems IRIS 是一项战略决策,需要认真规划和执行。虽然这种过渡具有显著的优势,包括增强性能、可扩展性和对现代架构的支持,但它也伴随着挑战。在本文中,我将重点介绍与编码相关的一些注意事项,以确保成功迁移。与结构和数据的实际迁移相关的所有事项都不在本文讨论范围之内。
.png)
首先,当你考虑迁移到不同的数据库系统时,你需要了解你的业务逻辑,无论是在应用程序(应用服务器)还是数据库服务器端。基本上,你需要重写的 SQL 语句在哪里?
大家好!
现在是时候庆祝我们的 18 位成员了,他们参加了InterSystems最新的技术文章竞赛,并撰写了
🌟21 篇精彩文章🌟
这次比赛汇集了优秀的稿件,展示了参赛者的专业知识和创新能力。面对如此众多的高质量稿件,评选出最佳稿件对评委来说确实是一项挑战。

让我们来认识一下获奖者,看看他们的文章:
![]()
如果您曾经在一个大型的IRIS命名空间中查找某个字符串、方法调用或模式的使用位置,您就会知道其中的痛苦:没有内置的方法可以在VS代码中对服务器端的ObjectScript代码进行grep式搜索--至少不需要跳过一些障碍。
这就是ObjectScript搜索要解决的问题。今天就从VS代码市场中简单安装一下试试吧。
如果不喜欢,卸载也很简单。但我认为你会喜欢它的--对于任何在 VS Code 中进行 ObjectScript 开发的人来说,它都是生活质量的巨大提升。
官方的 vscode-objectscript 扩展确实包含搜索功能。不过,要启用该功能,目前需要等待拟议中的 VS Code API 最终确定,或者手动安装扩展的自定义构建并启用拟议中的 VS Code API。这两种方法对于希望开箱即用的开发人员来说都不理想。
ObjectScript Search 是一个临时、独立的扩展,目前弥补了这一缺陷。它通过 InterSystems 活动栏中的专用面板提供全文服务器端搜索,无需特殊构建或拟议的 API。一旦官方扩展将搜索作为头等功能发布,该扩展将达到其目的,但在此之前,它在这里,它可以工作。
ObjectScript Search 的作用 ObjectScript Search 在 InterSystems 侧边栏中直接添加了搜索视图。