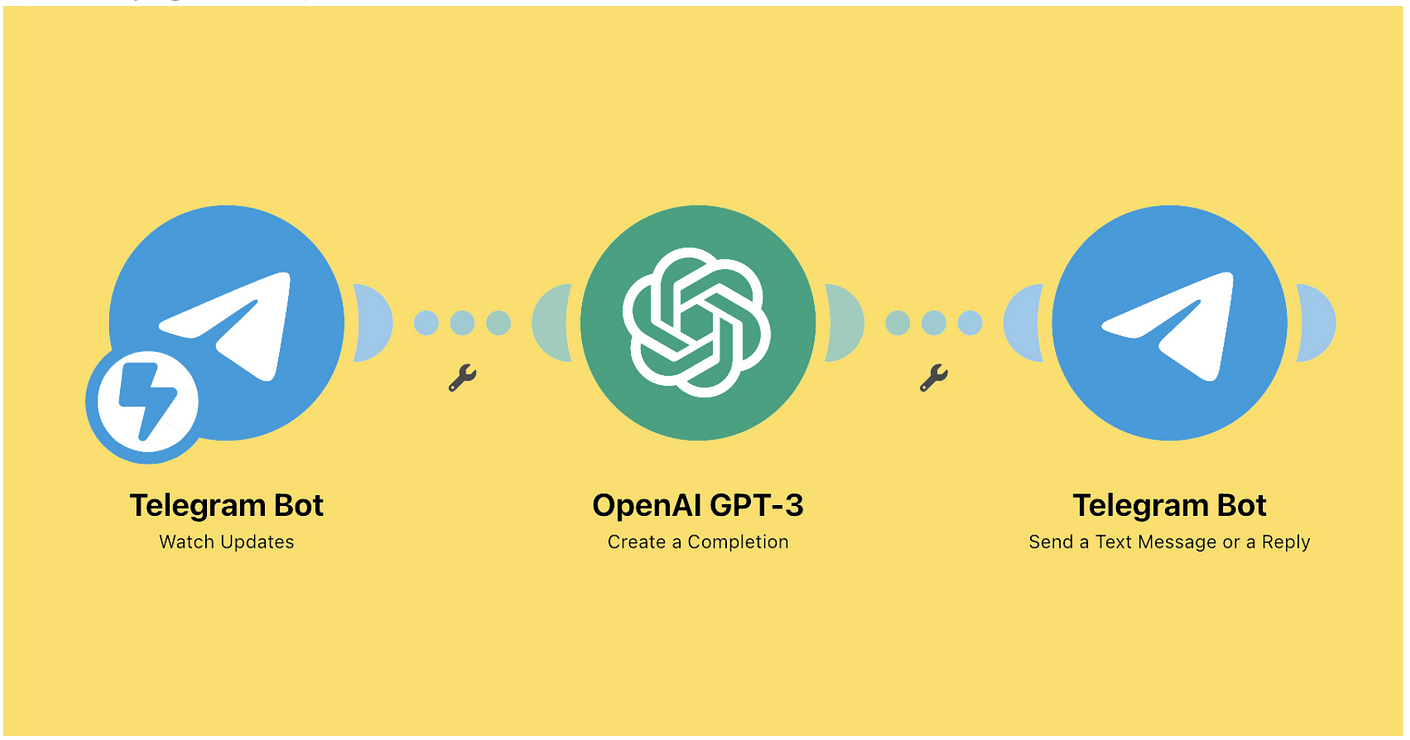
按查看数
按查看数 Open Exchange app
Open Exchange app关于 "智慧医院 "的真正内涵,有很多误解在流传。术语 "智慧Smart "已经成为 "自动化 "或 "数字设备 "的同义词。然而,事实是,增加技术、设备和传感器并不一定能使建筑或者医院变得'智慧'。而且,在某些情况下,数字创新被强加于医院,而没有真正考虑到其效果。
这种情况导致了一系列的复杂性和矛盾。例如,一方面,人们对医院采用数字技术的期望越来越高,但另一方面,人们越来越担心数字医疗解决方案正在创造更多离散的、孤岛的生态系统。同样,尽管医院面临着实现实时医疗系统的更大压力,但往往受制于其运营模式的孤岛性质或围绕各种医疗信息系统的互操作性问题。
这些相互冲突的压力表明,需要一种更协同、更集成、更综合、更全面的数字化转型方法--一种将系统整合在一起并从各个角度考虑影响的方法。
智慧医院数字孪生的出现,证明了这一技术为解决这些日益严峻的挑战提供了可行的手段。
在过去的几年里,数字孪生已经有了很大的发展,成为一项值得期待的技术。然而,尽管数字孪生被炒得沸沸扬扬,但对于数字孪生是什么(不是什么)以及它是否能实现其承诺,仍然存在相当大的困惑。像许多新技术一样,数字孪生正在 "幻觉破灭 "中挣扎并且在某些情况下被错误地描述。
在本文中,我们将通过回答这六个关键问题来正面解决这种困惑。

.png)
.png)