社区朋友们好,
传统的基于关键词的搜索方式在处理具有细微差别的领域特定查询时往往力不从心。而向量搜索则通过语义理解能力,使AI智能体能够根据上下文(而非仅凭关键词)来检索信息并生成响应。
本文将通过逐步指导,带您创建一个具备代理能力的AI RAG(检索增强生成)应用程序。
实现步骤:
- 添加文档摄取功能:
- 自动获取并建立文档索引(例如《InterSystems IRIS 2025.1版本说明》)
- 实现向量搜索功能
- 构建向量搜索智能体
- 移交至主智能体(分流处理)
- 运行智能体
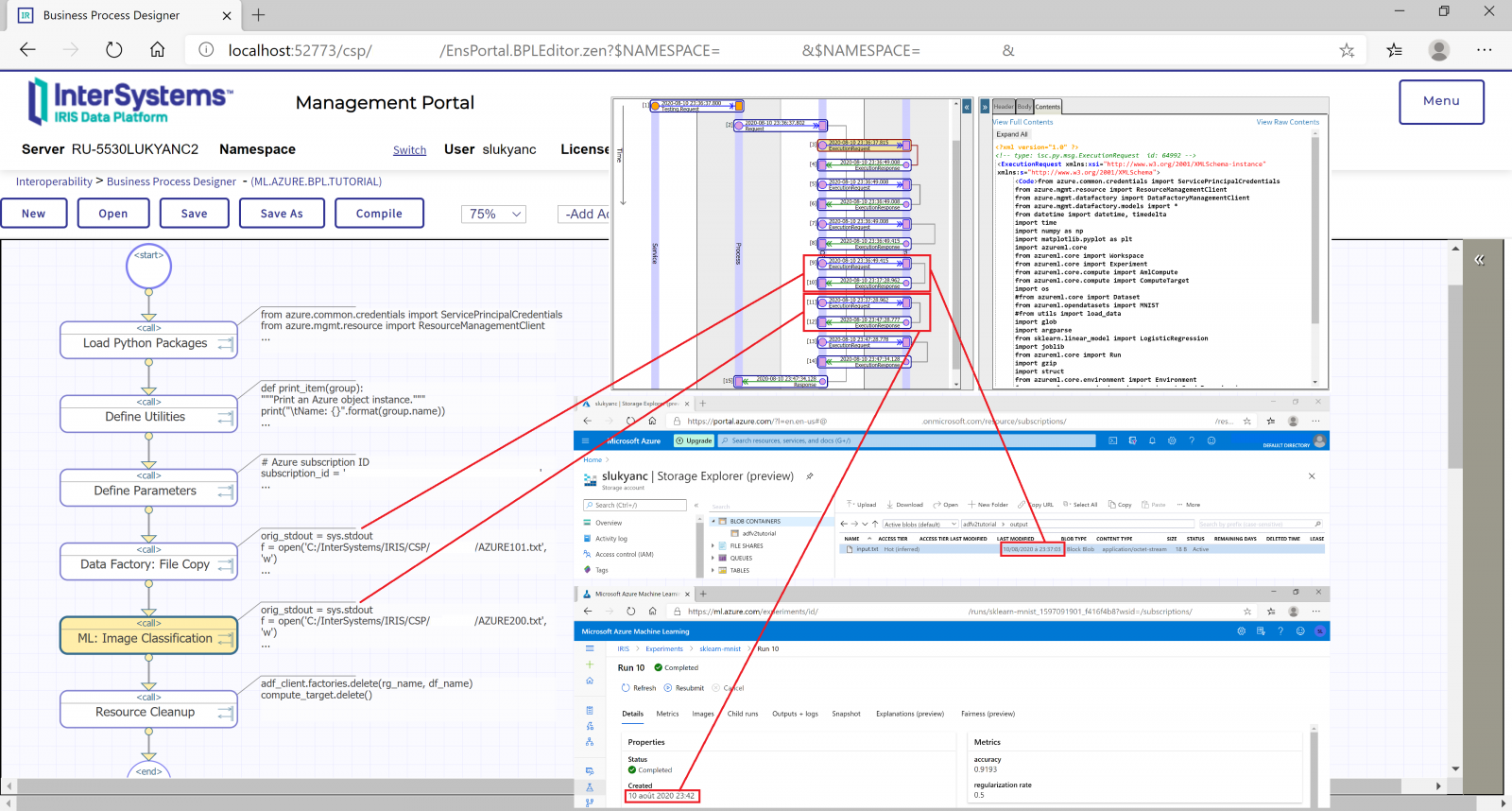
1. Create Agent Tools 添加文档摄取功能
Implement Document Ingestion: Automated ingestion and indexing of documents
1.1 - 以下是实现文档摄取工具的代码:
def ingestDoc(self):
embeddings = OpenAIEmbeddings()
loader = TextLoader("/irisdev/app/docs/IRIS2025-1-Release-Notes.txt", encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
db = IRISVector.from_documents(embedding=embeddings,documents=texts, collection_name = self.COLLECTION_NAME, connection_string=self.CONNECTION_STRING,)
向量搜索智能体(Vector Search Agent)能够自动完成文档的摄取(ingest)与索引构建(index), 该新功能在InterSystems IRIS 2025.1的数据资源文件夹里) 至 IRIS 向量存储, 只有当数据尚未存在时,才执行该操作。
.png)
运行以下查询以从向量存储中获取所需数据:
SELECT
id, embedding, document, metadata
FROM SQLUser.AgenticAIRAG
1.2 - 实现向量搜索功能
以下代码为智能体提供了搜索能力:
def ragSearch(self,prompt):
embeddings = OpenAIEmbeddings()
db2 = IRISVector (
embedding_function=embeddings,
collection_name=self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
docs_with_score = db2.similarity_search_with_score(prompt)
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
template = f"""
Prompt: {prompt}
Relevant Docuemnts: {relevant_docs}
"""
return template
分流代理处理传入的用户查询,并将其委托给矢量搜索代理,后者执行语义搜索操作,以检索最相关的信息。
 按点赞
按点赞 Open Exchange app
Open Exchange app

.png)
.jpg)