.png)
 按点赞
按点赞挑战
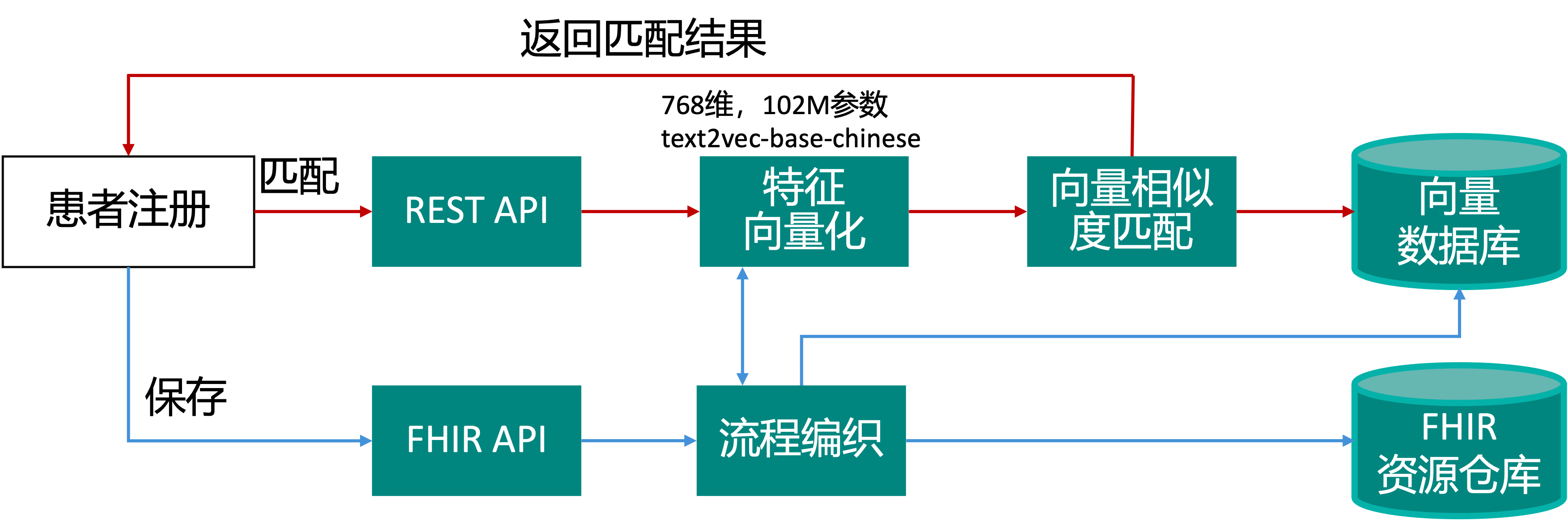
在使用FHIR进行开发的过程中,我们会面对海量的FHIR规范中定义的数据结构,具体来说在FHIR规范中定义了超过150个资源、700多个资源内元素。每个定义里都包括了对自身结构的描述以及数据约束、数据绑定值集等。对于一个开发人员要记住这些内容非常困难。
同时FHIR数据,特别是Json格式的FHIR数据是典型的“有向图”结构,它的资源中嵌套元素定义、集合以及复杂的资源间“关系”,在这些复杂结构的数据间导航并操作,非常困难。
.png)
解决方案
在InterSystems IRIS for Health 2024.1之前,我们会将FHIR数据以Json文档的方式载入 %DynamicAbstractObject,例如下面的代码
.jpg)
 Open Exchange app
Open Exchange app