新增
作为新的互操作性用户界面浪潮的一部分(请参阅@Aya Heshmat 在2025.1 和2025.3中介绍的新内容),v2026.1已经作为开发者预览版发布,这可能是您尝试一下的理由——它将发布用于消息查看和搜索的新用户界面,包括可视化跟踪(以及其他用户界面好东西)。
以下是一个快速预告:

InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
作为新的互操作性用户界面浪潮的一部分(请参阅@Aya Heshmat 在2025.1 和2025.3中介绍的新内容),v2026.1已经作为开发者预览版发布,这可能是您尝试一下的理由——它将发布用于消息查看和搜索的新用户界面,包括可视化跟踪(以及其他用户界面好东西)。
以下是一个快速预告:
大家好,我是姚鑫。
最近一段时间,我把自己过去几年在 InterSystems IRIS 项目中的开发经验,系统整理成了一本书—— 📕 《IRIS(数据平台)编程技术指南》 现已由 北京航空航天大学出版社 正式出版发行。
说实话,写书的过程比我想象中要难很多。 如果说写博客是“随手记录”,那么写书就是一次真正的“工程项目”:要保证结构完整、逻辑严谨、内容能从入门一路带到实战。
本书围绕 InterSystems IRIS 的核心开发语言 ObjectScript 展开,内容不仅讲语法,更注重“工程实践”。
主要包括:
✅ IRIS 平台介绍与开发环境搭建 ✅ ObjectScript 语法规则、变量体系、全局变量机制 ✅ 常用数据类型、表达式、系统命令、系统函数 ✅ 函数与方法、面向对象编程基础 ✅ %Persistent 持久类(ORM 与 SQL 映射) ✅ Storage 存储策略、懒加载机制、并发分析 ✅ 嵌入式数据结构、常见性能问题与技术难点解析
整体内容更偏向“项目实战型”,不是纯概念堆砌。
Hi 大家好!
备考 InterSystems 认证考试,仅阅读文档远远不够,更需要针对真实考试目标进行集中练习。如果您计划在 HL7、SQL、系统管理或开发领域验证自己的专业技能,系统化的准备将带来显著效果。
🧑🏫 备考平台

本平台提供了大量与认证领域相匹配的练习题,并附有详细的答案解析,指出相关文档参考。您还可以随时跟踪自己的学习进度,从而更清晰地了解哪些方面有所提升、哪些方面仍需加强。
通过教材与互动测验的结合,您可以找出薄弱环节,巩固知识,并以更充分的信心应对考试。
👉 点击此处开始练习
请注意,exam-prep.es 是一个独立的练习平台,与 InterSystems 无任何关联。本平台旨在作为备考的辅助工具使用。
我们在将 IRIS 实例迁移到另一台机器(甚至可能是升级版本)后,有多少次是在几天之后才猛然惊觉:我们忘了迁移那个对于业务操作(Business Operations)至关重要的 SSL 配置?或者是漏掉了某个凭据(Credential),又或是某个包里孤零零的一个类?
最简单的法子就是列一张清单¹。把我们必须迁移的实体项都罗列出来。但是,Word 文档里的简易清单往往会被人抛诸脑后,甚至干脆被无视。
管理学的基本原理告诉我们:如果你希望人们遵循流程,你可以采取以下手段:
Python 脚本固然可行,但人们可能会忘记脚本放在哪儿,或者去哪儿下载。一旦有了新版本,所有使用者都得重新下载。
IRIS 类或任务似乎也是理想选择,直到你意识到有时你是迁移到另一个网络的服务器,一个实例根本无法访问另一个。
这就是为什么我选择了浏览器插件一旦安装,它便触手可及(哪怕你几个月不用它);更新会自动完成。即便你换了浏览器或出于某种原因弄丢了插件,从应用商店重新安装也只是点击一下的事。
尽管LOCK(docs) 是 InterSystems IRIS 的基础部分,负责并发性,但开发者社区上关于它的讨论并不多。这是可以理解的,因为它是一个稳定且相当低级的命令。在本文中,我将举一个简单的例子,说明如何使用互操作性锁。在示例中,我们将有一个本地表,其中的引用数据由两个不同的进程使用:
这里的问题是,当业务操作更新表时(最糟糕的情况是进行完全重建),自定义函数将无法从表中获取数据,这将导致 DTL/规则处理出现问题。
锁可以帮助我们解决这个问题。具体方法如下:
更新器业务操作会先使用共享锁,然后再释放独占锁。一旦某个进程获得独占锁,IRIS 就会保证其他进程无法获得同一资源上的锁。这样,当独占锁被持有时,实用程序就无法获取共享锁。一旦我们的业务操作完成对表的更新,它就会释放独占锁,允许实用程序访问表。
让我们开始吧
有点简单(在实际项目中作为 LUT 可能会更好),但我们的目的是展示锁是如何工作的,而不是构建一个复杂的表:
Class Lock.大家好。又是我!!😀
最近,我试图整理InterSystems IRIS😆的一些学习材料,并意识到这些资源实际上非常分散。
因此,我在这里列出了一个按类别分组的列表,供以下人员使用:
此外,我还补充了一些自己的经验,说明哪些有用(哪些没用,可能只是对我没用🤫🤐)。
如果您不知道从哪里开始,请从这里开始:
我的体验 从 Developer Hub + 入门开始效果很好。它提供了快速运行的足够条件(无需安装,直接测试!!!!ᾒ)。
不适合我的地方 一开始就直接进入文档→正如我常说的...我知道句子中的每个单词,但就是不理解🥲。
当你想真正开始工作时:
InterSystems IRIS® 数据平台、InterSystems IRIS® for HealthTM 和HealthShare® Health Connect 的2025.1.4 和 2024.1.6维护版本现已全面上市 (GA)。这些版本包括对最近发布的一些警报和建议的修复,其中包括以下内容:
请通过Ideas Portal使用 "发布后反馈"类别分享您的反馈意见,以便我们共同打造更好的产品。
您可以在这些页面上找到详细的变更列表和升级检查列表:
现在有许多 EAP 可用。请查看此页面并注册您感兴趣的项目。
关键词 氛围编码(Vibe coding), Windsurf, IRIS, TIE
迄今为止,有人没有尝试过 "氛围编码(vibe coding) "吗?
即使仅仅在三年前,如果有人问
你可能会大笑一声,尽量不生气,找把椅子坐下来,开始计算光是这些分析/SoW/需求/设计/测试/服务文档就需要多少人*日或人*周,以及实际工程工作。
然而,随着基础模型的飞跃和进步,今天的情况肯定会变得更加现实。
我也希望了解其他人是如何使用它的。 以下只是我自己匆忙写下的随笔。
《WebGateway系列(4): 配置HTTPS访问IRIS的Web服务》中介绍了在Web服务器中配置SSL/TLS以实现从客户端浏览器到Web服务器之间的安全连接,从Web服务器到IRIS之间是否也可以通过配置SSL/TLS建立起安全连接呢?尤其是在Web服务器与IRIS没有安装在同一台Server上的情况下,这段连接的安全性也是需要考虑的。答案是肯定的,接下来我们就来介绍下配置Web Gateway使用SSL/TLS连接到IRIS的基本步骤。
1.首先,我们先准备一下所需要的证书。通讯的双方为Web Gateway 和 IRIS Super Server, 双方都需要准备好各自的证书和key。IRIS自带的Public Key Infrastructure(PKI)功能内置了OpenSSL,可以用来生成服务器端及客户端的证书和key。在使用此功能时,IRIS可以同时作为CA Server和CA Client,作为CA Server时可以生成自签名的证书,可以批准CA Client的证书申请并将证书下发给CA Client。
1)配置本地证书颁发机构服务器,生成sever端的证书和key。

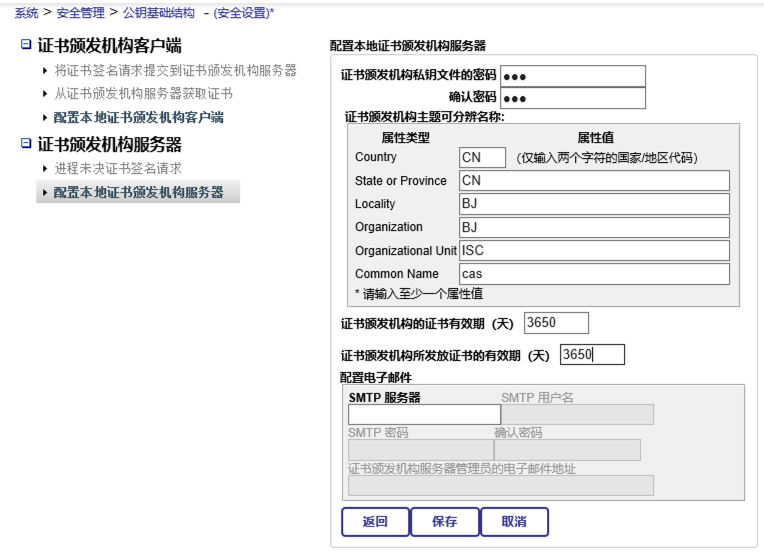
2)配置本地证书颁发机构客户端,如下
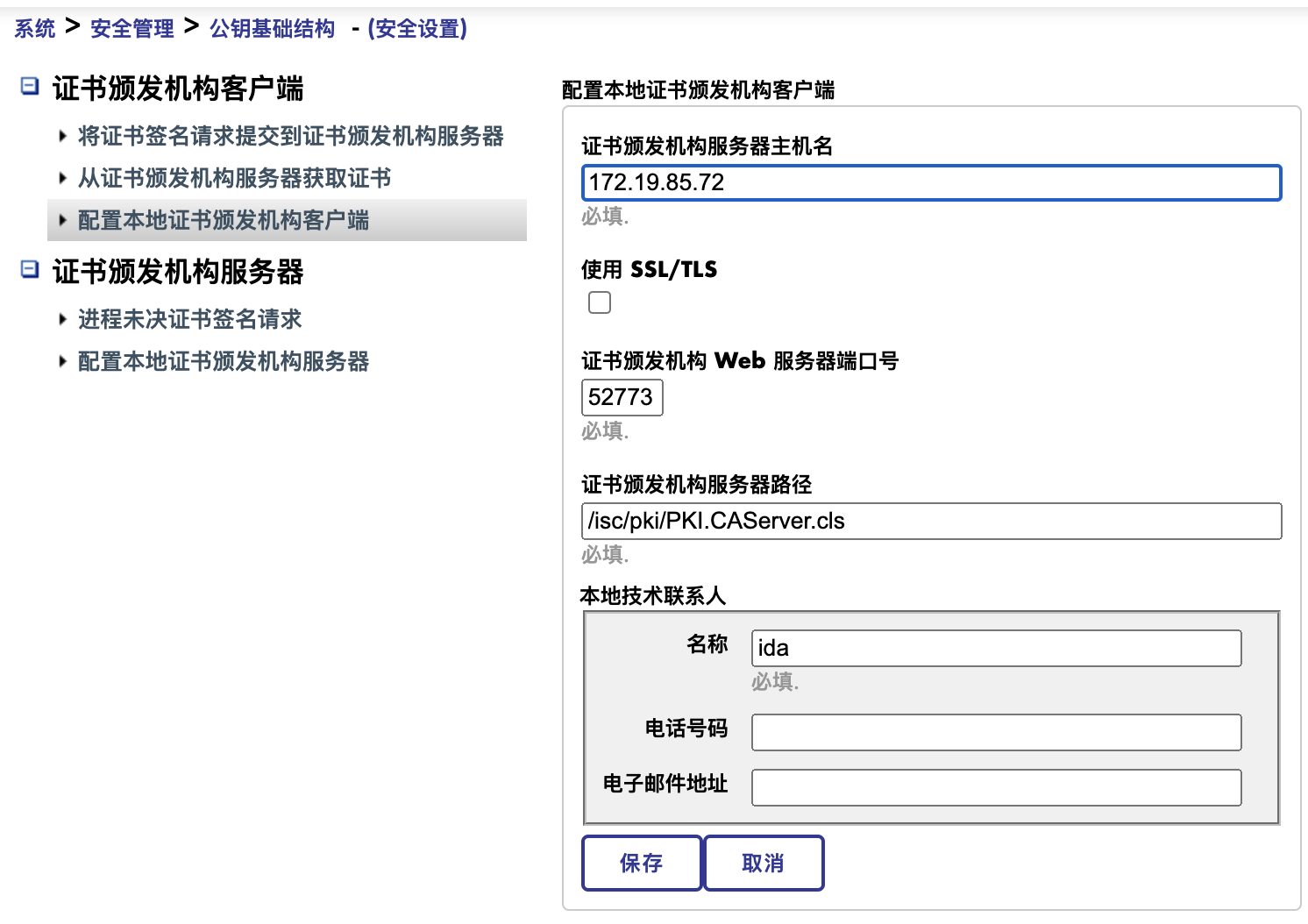
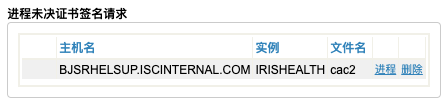
3)将证书签名请求提交到证书颁发机构服务器
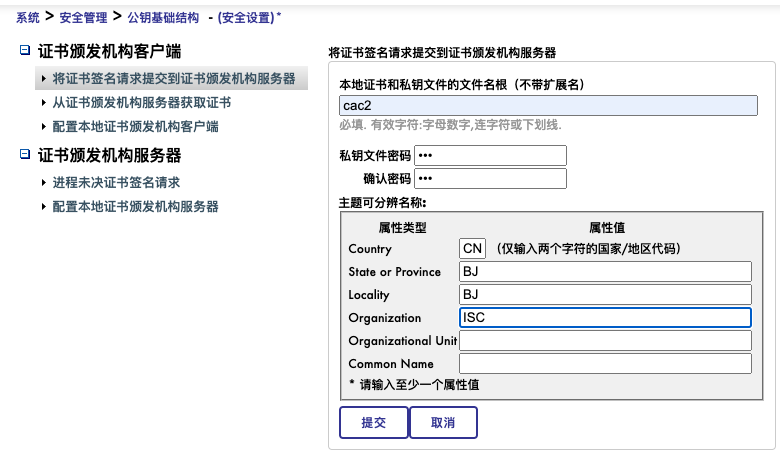
4)进程未决证书签名请求
发放证书。
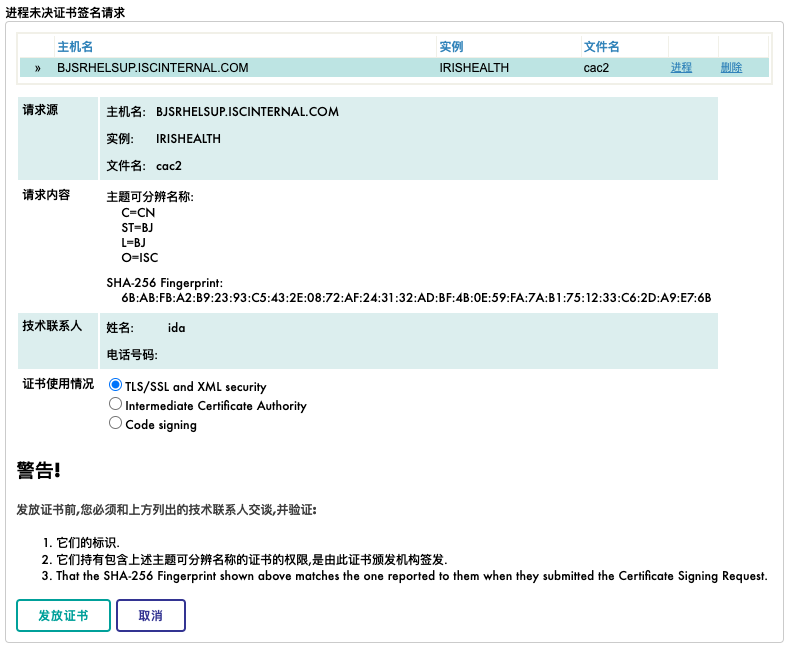
至此,Client以及Server端证书和key都已准备完成。
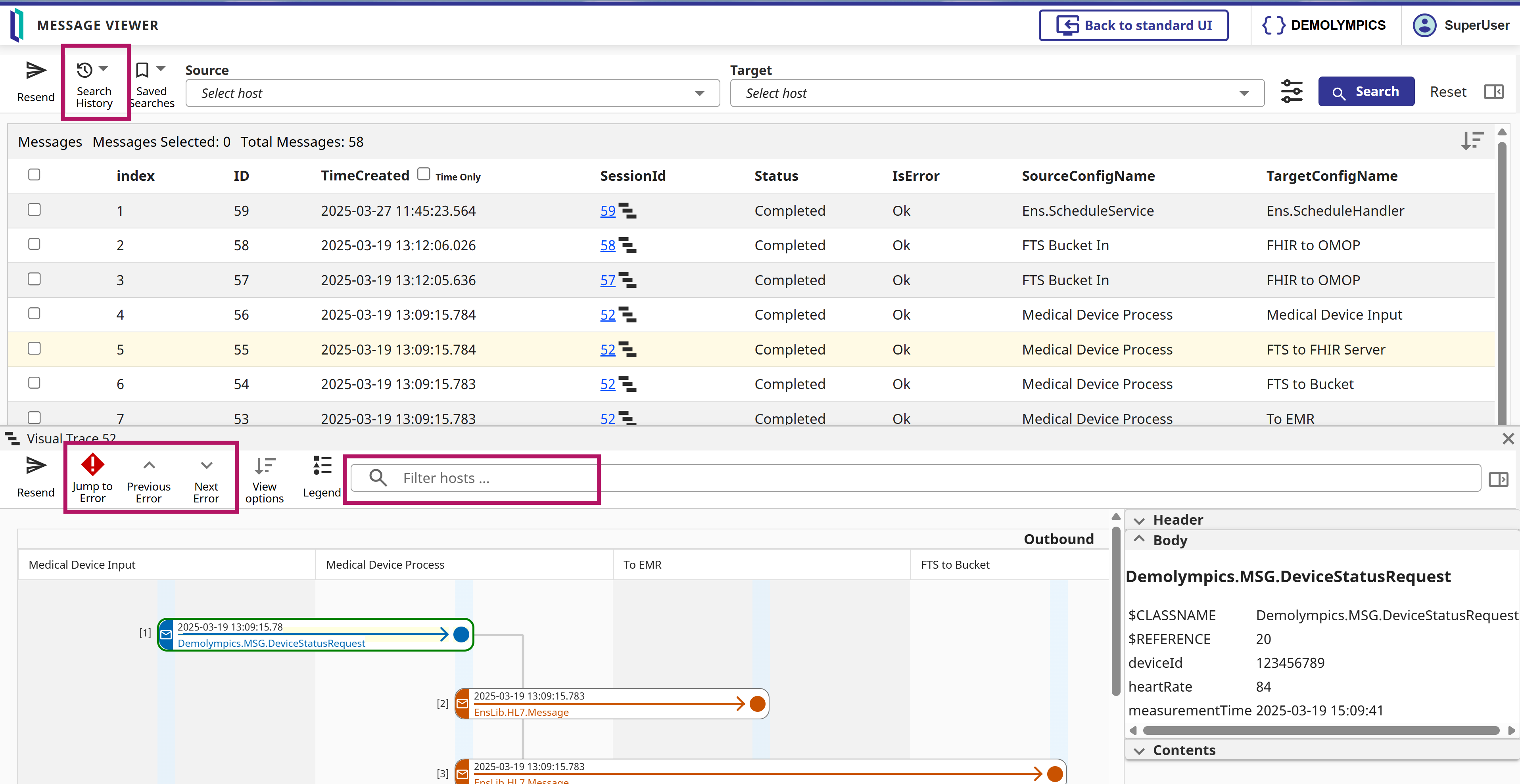
互操作性用户界面项目在 2025.1 版本的基础上继续进行 ,并采纳了客户和合作伙伴提出的许多建议和意见。 我们将继续投资于反馈和更新这一重要的用户体验。 在最新发布的 2026.1 版(适用于 IRIS、 IRIS for Health、 HealthConnect 和 Health Connect Cloud) 中 , BPL 编辑器(BPL Editor) 和 信息查看器/可视跟踪(Message Viewer/Visual Trace) 应用程序现在可供选择使用!
注意:
处理文件通常很简单:打开文件,读取并处理。这种方法非常有效,直到文件碰巧是 Excel 文件。
常见假设
起初,Excel 文件(.xlsx)看起来就像另一个数据文件,行、列和值。因此,我们很自然地认为它可以像 .txt 或 .csv 文件一样被读取。但问题就出在这里。
Excel 文件为何表现不同
关键区别在于数据的存储方式:
-> .txt / .csv - 纯文本,逐行存储。
-> .xlsx - 压缩、结构化格式(非纯文本)
excel 文件实际上不是一个简单的可读行流。从内部看,它是一个包含结构化数据的打包文件,标准文件读取命令无法解释这些数据。
如果把它当作文本文件处理,会发生什么情况?
重要事项 --> 这不是限制,而是工具和文件格式不匹配 。
实用的处理方法
与其只使用基于文本的方法,还有更好的选择、
如果有人曾在 IRIS 中处理过 Excel 文件,或有其他行之有效的方法,请随时分享。)
下面提到几个例子。
本文介绍如何在 InterSystems IRIS 中通过继承
EnsLib.HTTP.GenericOperation(或EnsLib.REST.GenericOperation)实现 OAuth2.0 支持,包括 OAuth2.0 Client 配置、Access Token 自动获取与 Header 注入,适用于各类第三方 REST API 集成场景。
在企业集成项目中,我们经常需要通过 REST API 对接第三方平台,例如 CRM、支付系统、云服务和 Open API 网关。
这些接口大多数采用 OAuth 2.0 作为授权机制。
虽然 InterSystems IRIS 提供了功能强大的通用 HTTP / REST 业务操作类:
EnsLib.HTTP.GenericOperationEnsLib.REST.GenericOperation但目前它们不直接支持 OAuth2.0 Access Token 自动注入。
本文将介绍一种常见且推荐的实现方式:
通过继承 GenericOperation类,自定义一个支持 OAuth2.0 的通用业务操作类(Business Operation)
实现以下能力:
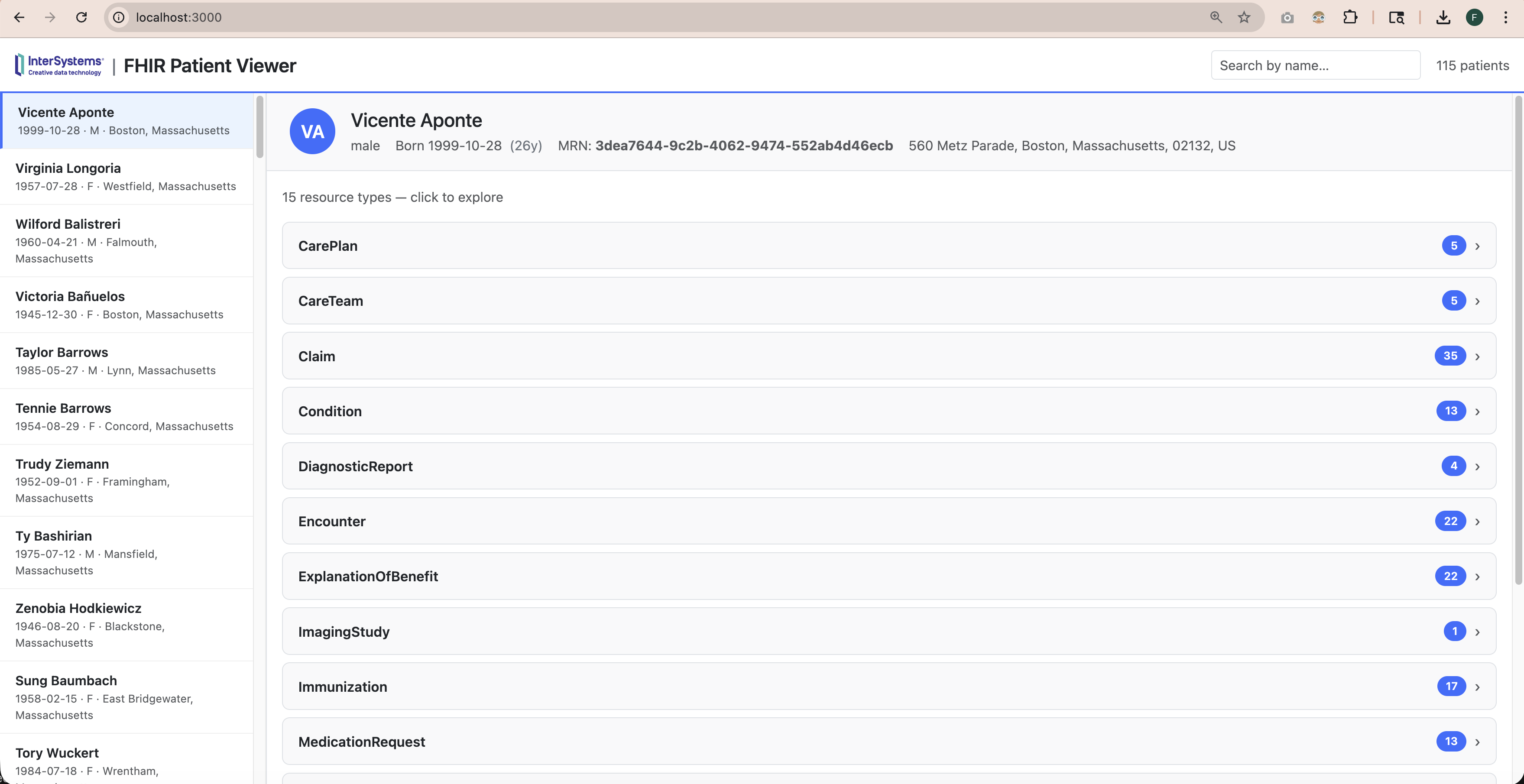
FHIR(快速医疗互操作资源)是存储和交换临床数据的现代标准。但是,一旦您的数据存储在 FHIR 服务器中,如何才能真正浏览这些数据呢?FHIR 数据以 JSON 格式存储,虽然功能强大,但直接读取并不实用。我希望有一种工具,可以让您点击病人,以简洁、可读的格式查看他们的病情、用药、化验结果等。于是,我创建了FHIR 患者查看器(FHIR Patient Viewer)。
该应用完全在 Docker 中运行,并直接连接 InterSystems IRIS for Health FHIR 服务器。启动时,它会自动将 115 个合成患者载入 IRIS,无需手动设置。
点击任何患者,查看其所有临床记录
逐字段展开每条记录
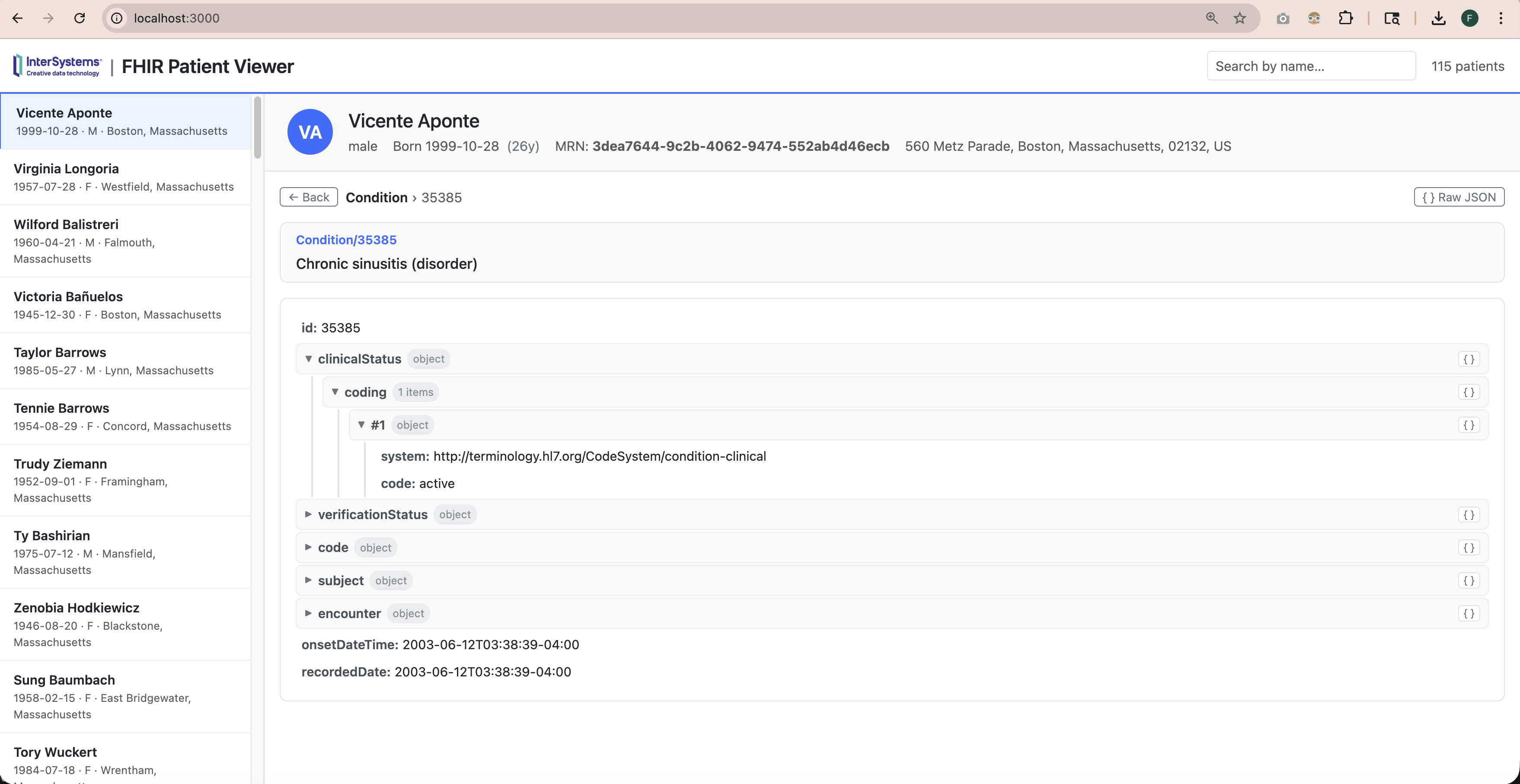
随时查看底层原始 JSON 文件
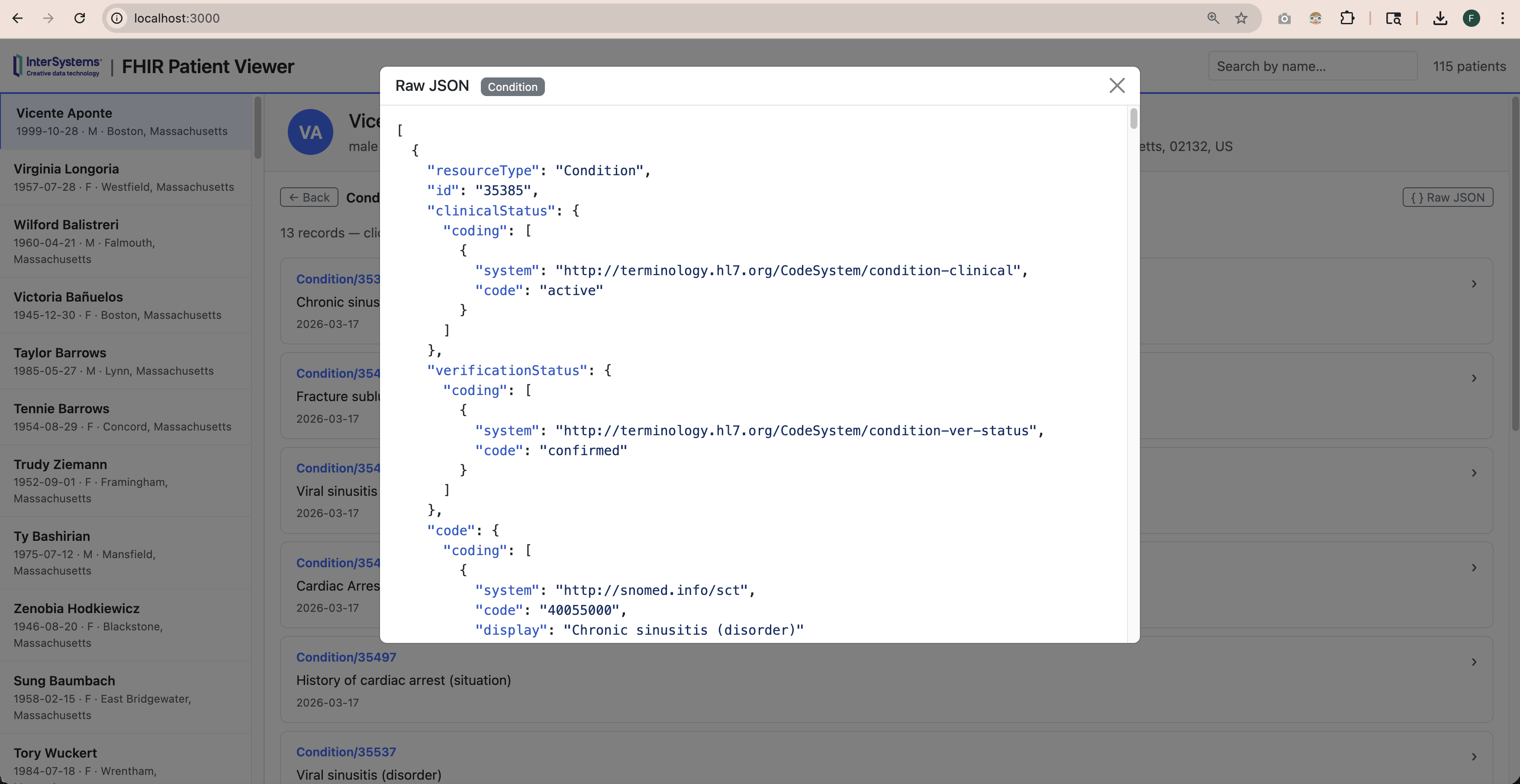
它预装了由Synthea生成的 115 个合成患者数据
Open Exchange 上有完整的源代码和设置说明:
https://openexchange.intersystems.com/package/FHIR-Patient-Viewer-2
欢迎反馈!
在我年轻的时候(具体有多年轻不在本文讨论范围之内),"token"这个词意味着乐趣。你看,每年我都会有几次机会去街机厅,和朋友们一起玩一些有趣的电子游戏。
如今,token意味着安全。JSON 网络令牌(JWT)身份验证已成为确保 REST API 安全的最流行标准之一。幸运的是,对于 IRIS 用户来说,我们有一种直接的方法来设置应用程序,使其受到这种方式的保护。然而,这种想法仍与我以前玩街机时的想法相似。如果你想玩游戏,就需要获取一些token!
设置
我们的首要任务是为 IRIS 做好准备,使用户能够获取token。首先,我们要在全系统范围内允许使用 JWT 身份验证。为此,我们将打开系统管理门户并登录。然后,我们将进入System Administration > Security > System Security > Authentication\Web Session选项。在同一区域,我们还可以授权其他身份验证替代方案,如 LDAP 和双因素身份验证。在变体列表的底部附近,我们会发现一个名为 "JWT Issuer Field "的字段,在这里我们必须键入一些值来标识token发行者。它可以是任何唯一的字符串,但通常是一个 URL 或域。这应该由应用程序接口和前端开发人员事先商定。您可以选择用户访问 API 时发送请求的 URL。在我的示例中,我将选择 www.myurl.
在本文中,我将向你展示如何在笔记本电脑上快速建立一个分片 IRIS 节点集群。本文的目的既不是详细讨论分片,也不是定义生产就绪架构的部署,而是展示如何在自己的电脑上快速建立一个配置为分片节点的 IRIS 实例集群,并利用它来玩转和测试这一功能。如果你想了解更多有关 IRIS 分片的信息,请点击此处查看相关文档。
首先,我要说明的是,IRIS分片允许我们做两件事:
因此,正如我所说,我们可以在其他文章中讨论分片表或联合表,现在只需关注前一步,即设置分片节点集群。
您熟悉 SQL 数据库,但不熟悉 IRIS 吗? 请继续阅读...
大约一年前,我加入了 InterSystems,IRIS 就这样进入了我的视线。 我使用数据库已经有 40 多年了,其中大部分时间都是为数据库供应商工作,我以为 IRIS 与我所知道的其他数据库大致相同。 然而,我惊讶地发现,IRIS 在很多方面都与其他数据库截然不同,而且往往要好得多。 这是我在 Dev Community 上发表的第一篇文章,我将为已经熟悉 Oracle、SQL Server、Snowflake、PostgeSQL 等其他数据库的人提供 IRIS 的高级概述。 希望我的介绍能让您更清楚、更简单,并节省您的入门时间。
首先,IRIS 支持 ANSI 标准 SQL 命令和语法。它有表格、列、数据类型、存储过程、函数......所有关系型的东西。 你还可以使用 ODBC、JDBC 和 DBeaver 或任何你喜欢的数据库浏览器。 因此,是的,您在其他数据库中知道和做的大多数事情都可以在 IRIS 上正常运行。 耶!
但我提到的那些不同之处又是怎么回事呢? 好了,系好安全带:
多模型(Multi-Model):IRIS 是一个关系数据库,但同时也是一个面向对象的数据库,还是文档存储,支持向量和立方体/MDX,以及.你知道我要说什么。
InterSystems IRIS® 数据平台、InterSystems IRIS® for HealthTM 和HealthShare® Health Connect 的2026.1版本现已全面上市 (GA)。这是一个扩展维护 (EM) 版本。
版本亮点:
InterSystems IRIS®数据平台的2023.1.7维护版本 、 InterSystems IRIS® for **** for HealthTM和HealthShare®Health Connect的 2023.1.7 维护版本现已全面上市 (GA)。
请通过Ideas Portal使用 "发布后反馈"类别分享您的反馈意见,以便我们共同打造更好的产品。
您可以在这些页面上找到详细的变更列表和升级清单:
现在有许多 EAP 可用。请查看此页面并注册您感兴趣的项目。
InterSystems IRIS 和 InterSystems IRIS for Health 的完整安装包可从 WRC 的InterSystems IRIS 数据平台完整工具包页面获取。HealthShare Health Connect工具包可从 WRC 的HealthShare 完整工具包页面获取。容器映像可从InterSystems 容器注册中心获取。
此版本附带适用于所有支持平台的经典安装包,以及 Docker 容器格式的容器映像。 有关完整列表,请参阅支持的平台文档。这些维护版本的版本号是2023.
SystemPerformance 已内置 NFS 磁盘命令(包括 nfsiostat),但默认处于禁用状态。通过以下命令启用:
$$Enablenfs^SystemPerformance()
启用后,系统将添加以下 NFS 命令(以 Linux 为例):
/usr/sbin/nfsstat -cn/usr/sbin/nfsiostat [间隔] [次数]请确保这些命令已安装且可通过操作系统运行
如需重新禁用,可执行:
$$Disablenfs^SystemPerformance()
添加任意操作系统工具时,会在 ^IRIS.SystemPerformance("cmds","user")下创建一个"用户"命令。
示例:
%SYS>set ^IRIS.SystemPerformance("cmds","user",$i(^IRIS.SystemPerformance("cmds","user")))=$lb("nfsiostat","/usr/sbin/nfsiostat ","间隔"," ","次数"," > ")
操作建议:
添加前建议先查看现有命令结构,选择合适的配置文件名称:
zwrite ^IRIS.我以前可能提到过这一点:我认为可视化跟踪(Visual Traces),即包含每个步骤完整内容的序列图,是 IRIS 数据平台的一项神奇功能!以可视化跟踪的方式提供有关 API 内部工作原理的详细信息,对 IRIS 平台上的项目非常有用。当然,这适用于我们没有开发高负荷解决方案的情况,在这种情况下,我们根本没有时间保存/读取信息。对于所有其他情况,欢迎阅读本教程!
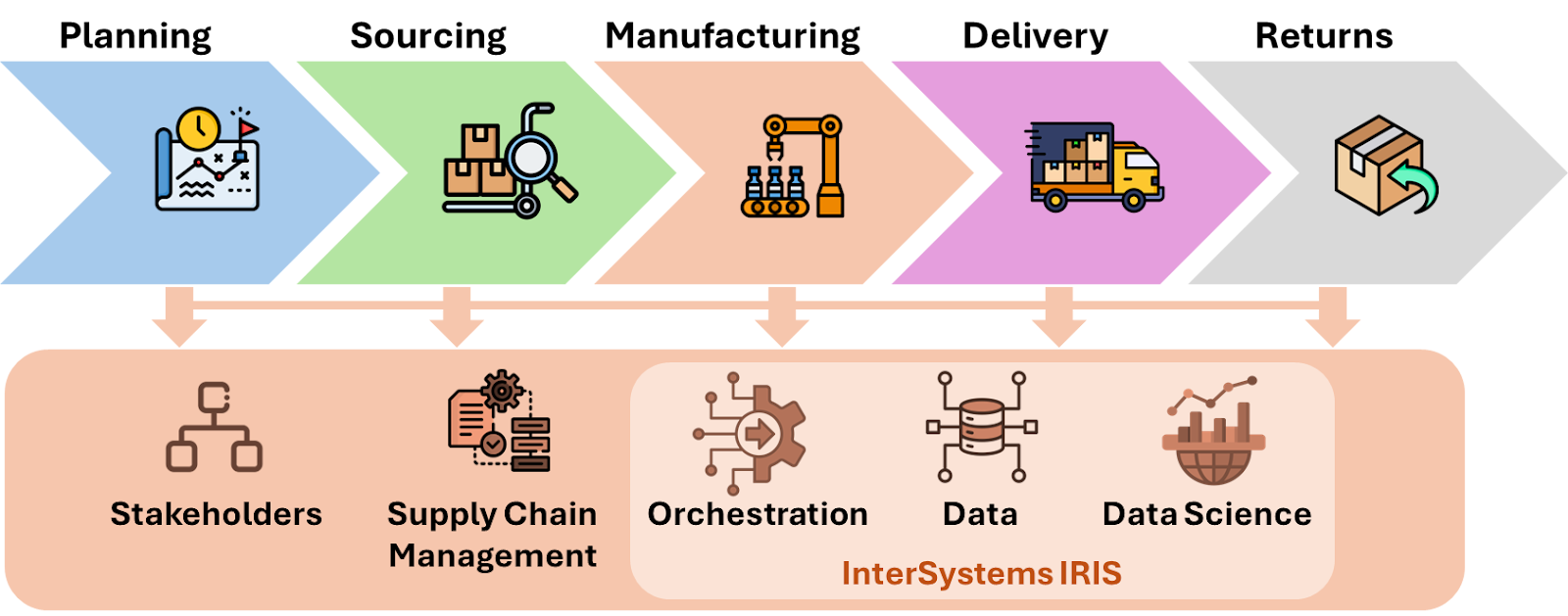
供应链是指由公司业务领域及其供应商和合作伙伴(利益相关者)执行的一系列流程和活动,从原材料采购、生产到交付给最终消费者。利用 InterSystems IRIS 的协调功能,供应链管理解决方案可以更好地管理供应链:
大家好。好久不见。我想再次与大家分享我最近学习的内容 通过 JDBC 使用 SQL 创建外来表。
因为我同时也在学习 IRIS BI,所以我从这个 Sample-BI docker 环境开始。
https://github.com/intersystems/Samples-BI
启动环境后,以超级用户身份登录管理门户http://localhost:52773/csp/sys/UtilHome.csp。
将命名空间切换为IRISAPP。
.png)
我们会发现所有样本数据都存储在IRISAPP 命名空间中。让我们找一张简单的表来测试外来表功能 🤣
System Explorer > SQL
.png)
让我们通过在 "执行查询(Execute Query tab) "选项卡中执行以下 SQL 查询来试试表HoleFoods.Outlet
SELECT
ID, City, Country, Latitude, Longitude, Population, Type
FROM HoleFoods.Outlet
.png)
太棒了!😉 表中有 35 个条目。
直到今年年初,我几乎没怎么做过编程工作——我已经厌倦了它。
在担任多年一线软件工程师和数据科学家后,我在2015年左右陷入了职业倦怠。我转而从事以“外部创新”为主的业务拓展角色,并于2019年加入InterSystems担任产品经理。我怀念编程的创造性,但并不怀念其中的枯燥乏味。无休止的样板代码编写、调试和上下文切换让我创意枯竭。就像电影《好好先生》(Yes Man)中金·凯瑞饰演的角色一样,我发现自己对新项目总是说“不”——以至于我换了职业!
然后,AI编程助手出现了。而我,成了对机器人说“好”的“好好先生”。
当我刚开始使用AI编程助手(先是Windsurf,然后是Cline,接着是Roo Code,现在是Claude Code,还尝试过opencode)时,感觉就像变魔术一样。自然语言 → 可运行的代码。我对每个建议、每个重构、几乎每个疯狂的想法都说“好”。
我第一个主要的AI辅助项目是几个月前启动的一个内部项目——为IRIS开发的一系列Python脚本和管道。我兴奋不已,让机器人尽情发挥: “添加这个功能!”——好!“重构那个模块!”——好!“让它可配置!”——好!“添加更多集成!”——好!
创意的能量回来了。代码如泉涌。我又感到自己高效了起来。
然后,我的实习生——一名软件工程专业的学生——查看了代码库。
他并不满意。
| 警报编号 | 受影响的产品和版本 | 风险类别和评分 | 明确要求 |
| DP-448888 | 产品: |
在上述版本中,如果数据库缓存大于或等于 2,097,152 MB(2 TB),实例可能无法启动或在运行过程中挂起。请注意,未配置实例的初始数据库缓存分配是系统物理内存的 25%;因此,如果物理内存≥ 8 TB,则未配置实例可能存在风险。更多信息,请参阅为数据库和常规缓存分配内存以及数据库缓存 (globals) 配置参数。
如果使用高级配置选项分配多个块大小的缓冲区,则必须以global缓冲区为单位计算限制。只要所有大小的缓冲区总和少于 268,435,456 个,就不会有风险。
此问题影响以下产品的 2024.3、2025.1.0 - 2025.1.3、2025.2.0 和 2025.3.
InterSystems 常见问题
如果您尝试从顶级节点删除在子脚本级别映射的全局变量,您将收到一个<SLMSPAN>错误,并且它不会被删除。这是因为用于子脚本级别映射全局变量的kill命令不能跨映射使用。
// Suppose subscript-mapped globals exist in different databases, as shown below:
^TEST(A*~K*) -> database A
^TEST(L*~Z*) -> database B
// Trying to kill from the top level will result in a <SLMSPAN> error.
NAMESPACE>Kill ^TEST
<SLMSPAN> <- This error is output.要只删除当前命名空间(数据库)中的全局,请使用以下命令:
NAMESPACE>Kill ^["^^."]TEST在子脚本级别映射的全局变量必须移动到数据库并直接删除。
要切换到数据库,请使用以下命令:
zn "^^c:\intersystems\iris\mgr\user"
or
set $namespace="^^c:\intersystems\iris\mgr\user"使用 $System.OBJ.
在上一篇文章中,我们介绍了IrisOASTestGen——一个基于OpenAPI 2.0规范为InterSystems IRIS生成REST API测试代码的工具。该文章展示了如何使用OpenAPI Generator附带的默认模板来搭建测试用例。本文将聚焦于接下来的自然步骤**:自定义生成的测试代码**。通过使用Mustache模板扩展代码生成逻辑,我们可以表达更丰富的语义、实现CRUD感知测试,并创建更有意义的测试套件。本文的示例将修改IrisOASTestGen,为createPerson操作生成测试,包括遍历所有预期响应。这将展示如何使用OpenAPI规范中的自定义字段来驱动Mustache模板内的条件渲染。
为了使代码生成支持CRUD操作,OpenAPI规范可以在vendorExtensions中包含自定义字段。这些自定义字段作为标志,Mustache模板可以检测到它们。
InterSystems 定期更新我们的软件发布政策和实践,以适应客户的需求。
为了让客户和合作伙伴更容易预测,我们现在改变了维护版本的发布节奏,并对其他几个方面进行了调整。
本文总结了我们数据平台产品的发布周期和最近的变化,并宣布了一些新的更新。
有什么相同之处?功能发布节奏提醒
自 2018 年以来,InterSystems 一直在使用 InterSystems IRIS 的双流功能发布节奏(请参阅原始公告)。我们提供
EM 发行版的版本号为 YYYY.1(例如 2022.1 或 2023.1),因此很容易识别。 CD 发行版的版本号为 YYYY.2、YYYY.3 等。
大家好! 👋
欢迎来到IRIS IO 工具系列的第二部分。这个扩展是我提交给InterSystems 2025 年 "将想法变为现实 "竞赛的作品,它为您提供了一个直观而强大的界面,可直接在 VS 代码中导入和导出数据。
如果你觉得这个扩展有用,请考虑在竞赛中为我投票!
在上一篇文章中,我们介绍了
现在是时候深入了解导入引擎(Import Engin)了_它旨在支持
该扩展具有智能推理层,可分析输入文件并自动建议最佳的 IRIS 表格数据格式,提供有指导的辅助数据建模。
该扩展支持两种不同的方案:
在以下情况下,这是理想的选择
会发生什么?
数据库表中索引的力量
在使用数据库时,大多数开发人员都了解索引的概念以及使用索引的原因:加快数据检索速度。但是,索引的真正影响往往只有在比较有索引和没有索引的情况时才会显现出来。
你知道没有索引会发生什么吗?
试想一个有三列的表:姓名、年龄和手机号码。
.png)
现在,考虑一下这个查询:
.png)
如果年龄列没有索引,数据库引擎会
这意味着引擎会遍历整个数据结构,这对于大型表来说非常耗时。
索引会发生什么情况?
现在,如果年龄列有索引,流程就会发生巨大变化:
这就是为什么索引是如此强大的优化工具。
现实生活中的一课
最近,我们遇到了一个有趣的情况,凸显了索引的重要性。
我们的表有 5 条记录,而年龄列是有索引的。然后,我们错误地从索引结构(而不是主表)中删除了两个条目。这两个条目对应的是 ID X001 和 X005,它们的年龄都是 26 岁。
.png)
当我们运行
SELECT ID, Age, EmpId, Mobile, NameFROM Company.Employee WHERE Age = 26
我们预计会有 3 条记录(因为主表中仍有这些记录),但只出现了 2 条记录。
.png)
为什么呢?