 按查看数
按查看数
 Open Exchange app
Open Exchange app集成平台的关键在于解决系统之间的互联互通和互操作性的问题,是一个多厂商、多协议的体系结构。医院在集成平台实施的过程中,面临的第一件重要的事情就是交互标准的选择,目前的建设中,分为两队:非标准队和标准队。非标准队一般采用视图抓取、xml格式、json等等的自定义格式,标准队一般采用HL7 V3、HL7 V2、FHIR、DICOM等医疗领域标准,下面会简单介绍一下各种方式以及实施落地的难易程度。(以下内容中将以难易程度总分5★来表示,星数量越多代表难度越高)
1、非标准队
与其说非标准,不如定义为院内交互标准,交互仅限于院内,是一种很有限的互操作,而且定制程度很高,需要很好地把握系统的内部知识。方案缺乏通用性,难以规模推广。但由于其技术门槛较低,学习成本较低,在集成系统数量较少时不失为一种经济快速的方法。
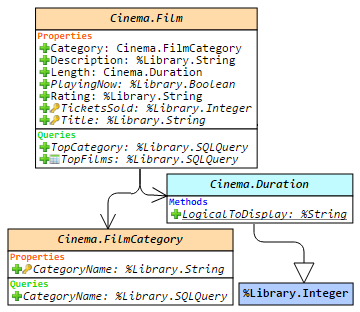
.png)