新增
给大家推荐一种新的大型表格管理方式!看看分区如何帮助您管理和查询数据:
给大家推荐一种新的大型表格管理方式!看看分区如何帮助您管理和查询数据:
如果您是 InterSystems 的新用户,欢迎访问InterSystems 开发者交流中心(Developer Hub)。

您可以从这里开始使用 InterSystems 技术——安装 InterSystems IRIS,连接到它,运行一些实际的东西,或者直接在基于浏览器的交互环境中试用产品(无需设置)。
如果你想知道从哪里开始,这里有你会发现的内容:
开发者入门指南 - 介绍 InterSystems IRIS 的结构以及如何设置它
快速入门 - 简短实用的指南,帮助您从零开始进行设置
尽管LOCK(docs) 是 InterSystems IRIS 的基础部分,负责并发性,但开发者社区上关于它的讨论并不多。这是可以理解的,因为它是一个稳定且相当低级的命令。在本文中,我将举一个简单的例子,说明如何使用互操作性锁。在示例中,我们将有一个本地表,其中的引用数据由两个不同的进程使用:
这里的问题是,当业务操作更新表时(最糟糕的情况是进行完全重建),自定义函数将无法从表中获取数据,这将导致 DTL/规则处理出现问题。
锁可以帮助我们解决这个问题。具体方法如下:
更新器业务操作会先使用共享锁,然后再释放独占锁。一旦某个进程获得独占锁,IRIS 就会保证其他进程无法获得同一资源上的锁。这样,当独占锁被持有时,实用程序就无法获取共享锁。一旦我们的业务操作完成对表的更新,它就会释放独占锁,允许实用程序访问表。
让我们开始吧
有点简单(在实际项目中作为 LUT 可能会更好),但我们的目的是展示锁是如何工作的,而不是构建一个复杂的表:
Class Lock.RefData Extends %Persistent
{
Property Value;
}在本文中,我将向你展示如何在笔记本电脑上快速建立一个分片 IRIS 节点集群。本文的目的既不是详细讨论分片,也不是定义生产就绪架构的部署,而是展示如何在自己的电脑上快速建立一个配置为分片节点的 IRIS 实例集群,并利用它来玩转和测试这一功能。如果你想了解更多有关 IRIS 分片的信息,请点击此处查看相关文档。
首先,我要说明的是,IRIS分片允许我们做两件事:
因此,正如我所说,我们可以在其他文章中讨论分片表或联合表,现在只需关注前一步,即设置分片节点集群。
您熟悉 SQL 数据库,但不熟悉 IRIS 吗? 请继续阅读...
大约一年前,我加入了 InterSystems,IRIS 就这样进入了我的视线。 我使用数据库已经有 40 多年了,其中大部分时间都是为数据库供应商工作,我以为 IRIS 与我所知道的其他数据库大致相同。 然而,我惊讶地发现,IRIS 在很多方面都与其他数据库截然不同,而且往往要好得多。 这是我在 Dev Community 上发表的第一篇文章,我将为已经熟悉 Oracle、SQL Server、Snowflake、PostgeSQL 等其他数据库的人提供 IRIS 的高级概述。 希望我的介绍能让您更清楚、更简单,并节省您的入门时间。
首先,IRIS 支持 ANSI 标准 SQL 命令和语法。它有表格、列、数据类型、存储过程、函数......所有关系型的东西。 你还可以使用 ODBC、JDBC 和 DBeaver 或任何你喜欢的数据库浏览器。 因此,是的,您在其他数据库中知道和做的大多数事情都可以在 IRIS 上正常运行。 耶!
但我提到的那些不同之处又是怎么回事呢? 好了,系好安全带:
多模型(Multi-Model):IRIS 是一个关系数据库,但同时也是一个面向对象的数据库,还是文档存储,支持向量和立方体/MDX,以及.你知道我要说什么。
本文将讨论 Microsoft Visual Studio Code IDE中包含的所有调试工具 。
内容包括
让我们从了解调试要求开始!
前提条件
有两个插件(扩展)可用于调试 ObjectScript:
第一个是 InterSystems ObjectScript 扩展包的一部分 。第二个是 Serenji,它是一个独立的插件,提供编辑器、文件管理器和调试功能。这两个插件都可以从插件商店安装。要激活关键功能,Serenji 需要许可证。在本文中,我们将使用 InterSystems ObjectScript 扩展包来降低学习难度。在掌握基础知识后,您可以考虑购买 Serenji 的付费许可证。
InterSystems IRIS 的架构将数据的逻辑组织(命名空间)与其物理存储位置(数据库)分开。理解这种分离以及命名空间和数据库之间的区别对于有效的数据管理、安全性,尤其是高性能数据共享至关重要。
在本文中,我将讨论这些基础组件,并提供利用全局映射跨不同逻辑环境共享本地数据结构(全局)的实用指南。
数据库代表了数据存储在磁盘上的物理现实。首先,它是文件系统中名为 IRIS.dat 的文件(例如,<安装文件夹>\mgr\user\IRIS.DAT )。该文件的最大容量为 32TB。它是所有实际数据和代码的容器。数据库由 IRIS 内核管理,它在物理文件级别处理缓存、日志和事务日志。
安装 InterSystems IRIS DBMS 时,会自动安装以下数据库:
大家好,社区成员们:
对于刚接触InterSystems IRIS的开发者而言,这有个好消息!我们现已在Instruqt平台上推出了实操互动教程!这些教程非常适合希望快速上手、在真实环境中演练,并建立对基于IRIS的开发信心的开发者。(译者注:国内需要🪜)
.png)
大家好! 我最近才加入 InterSystems,但发现尽管我们推出了完全免费且出色的社区版,但大家并不是十分清楚如何获取。 因此我决定编写一份指南,详细介绍获取 InterSystems IRIS 社区版的所有不同方式:
对于刚刚接触 InterSystems IRIS 开发的伙伴,推荐使用社区版的容器化实例,在我看来,这是最简单直接的方式。 InterSystems IRIS 社区版可以在 DockerHub 上获取;如果您有 InterSystems SSO 帐户,还可以在 InterSystems 容器注册表中获取。
在这两种情况下,您都需要使用 docker CLI 拉取所需镜像:
docker pull intersystems/iris-community:latest-em
// or
docker pull containers.intersystems.com/intersystems/iris-community:latest-em接下来,您需要启动容器:要从容器外部与 IRIS 进行交互(例如使用管理门户),您需要发布一些端口。 以下命令将运行 IRIS 社区版容器,并发布超级服务器和 Web 服务器端口;请注意,此时不能运行其他依赖 1972 或 52773 端口的程序!
docker run --name iris -d --publish 1972:1972 --publish 52773:52773 intersystems/iris-community:latest-emAutomating Configuration of InterSystems IRIS with Configuration Merge
CPF merge通过合并一个人工编辑的merge file, 自动的配置新创建的iris instance, 或者修改已有的iris instance。适用于:
Caché 和早期的IRIS版本提供了manifest功能,用来做IRIS实例的配置。 Manifest很繁琐,而且各个版本的配置中有细微的区别,非常难以管理。 如今有了CPF merge, maifest的所有功能都可以在CPF merge实现, 因此manifest在新版IRIS中也就完全被替代了。

执行merge可以在操作系统命令行下执行, 如下面的例子
# 第2个参数可选,如果为空,自动使用系统当前的iris.cpf
$ iris merge iris /external/irismerge.conf /usr/irissys/iris.cpf
iris-main是IRIS镜像的的ENTRYPOINT程序。 在Container中,ENTRYPOINT 指令允许你指定一个可执行程序或者脚本,作为容器启动后运行的主程序。这个程序会在容器启动时自动执行。
执行docker ps 命令可以看到当前container的ENTRYPOINT是什么:
hma@CNMBP23HMA demo % docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8f31a857dc90 .../irishealth:2024.2 "/tini -- /iris-main" 3 days ago Up 3 days 2188/tcp, 52773/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:1980->1972/tcp iris-a
hma@CNMBP23HMA demo %
在创建webgateway的container时,可以使用ISC_DATA_DIRECTORY=参数, 选择把CSP文保存在主机而不仅仅是container内部。如下面的例子: 使用volumnes映射了主机的./dur-wg-a目录到container的目录, 而command中的会讲webgateway的配置文件, log文件等保存在主机。
webgateway-apache:
image: containers.intersystems.com/intersystems/webgateway-arm64:2024.1
container_name: wg-tls
hostname: wg-tls
ports:
- "8080:80"
- "4433:443"
volumes:
- ./webgateway/csp:/external
- ./dur-wg-a:/dur
environment:
- TZ=CST-8
- ISC_CSP_CONF_FILE=/external/CSP-apache.conf
- ISC_CSP_INI_FILE=/external/CSP-merge.ini
- ISC_DATA_DIRECTORY=/dur
上一篇文章使用人工配置的方法简单的配置了webgateway container. 接下来来介绍如何在docker-compose里做自动化部署。
先总结我们要做的事情:
这些是最基本的功能。除此之外, 用户还可能会要求建立WebGateway到IRIS的TLS连接,或者在Apache2部署自己的网页等等。后面的文章会一一介绍。
上一篇文章中,我通过Webgateway管理页面定义了Webgateway到IRIS的连接,其实是定义了webgateway的配置文件CSP.ini。 无论WebServer是什么类型,IIS,Apache, Nginx, CSP.ini的都是一样的。在Linux中, CSP.ini位于/opt/webgateway/bin目录。
InterSystems提供了一个工具叫 CSP merge。 简单的说,就是可以定义一个被合并的文件, webgateway运行时会不停的扫描这个文件,发现有内容的修改,就把修改后的配置项合并到工作中的CSP.
在
#;这一部有可能需要科学上网,否则无法正常登陆
hma@CNMBP23HMA ~ % docker login -u="hma" -p="k8zIqpoafIUaViP2BA4gCZdcC4EeKyb0svSjnyVtcWMb" containers.intersystems.com
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
Login Succeeded
# pull iris image,webgateway,Passhash, arbiter, etc.
hma@CNMBP23HMA ~ % docker pull containers.intersystems.com/intersystems/healthconnect-arm64:latest-cd
hma@CNMBP23HMA ~ % docker pull containers.intersystems.com/intersystems/webgateway-arm64:latest-cd
...
我在3年前写过同样内容的文章。随着IRIS版本的更新,安装的细节有了些变化,而且,尤其是2024年以后的版本不再使用PWS(Private Web Server), 安装最新版本的IRIS通常同时要安装一个外部的Web服务器,Apache或者nginx。 另外, 大家对自动部署的需要越来越多,因此我也会在下面的内容里面包括自动部署,配置iris, 安装软件等等内容。希望给各位一个基本完整的介绍。
内容列表如下:
基础篇
iris-main和在container外保存iris数据随时更新
在这一系列文章中,我想向大家介绍并探讨使用 InterSystems 技术和 GitLab 进行软件开发可以采用的几种方式。 我将介绍以下主题:
在第一篇文章中,我们介绍了 Git 基础知识、深度理解 Git 概念对现代软件开发至关重要的原因,以及如何使用 Git 开发软件。
在第二篇文章中,我们介绍了 GitLab 工作流 – 一个完整的软件生命周期流程,并介绍了持续交付。
在第三篇文章中,我们介绍了 GitLab 安装和配置以及将环境连接到 GitLab
在这篇文章中,我们将介绍编写 CD 配置。
首先,我们需要多个环境以及与之对应的分支:
| 环境 | 分支 | 交付 | 有权提交的角色 | 有权合并的角色 |
|---|---|---|---|---|
| 测试 | master | 自动 | 开发者、所有者 | 开发者、所有者 |
| 预生产 | preprod | 自动 | 无 | 所有者 |
| 生产 | prod | 半自动(按下按钮进行交付) | 无 |
所有者 |
作为示例,我们将使用 GitLab 流程开发一个新功能,并使用 GitLab CD 进行交付。
在这一系列文章中,我想向大家介绍并探讨使用 InterSystems 技术和 GitLab 进行软件开发可以采用的几种方式。 我将介绍以下主题:
在上一篇文章中,我们介绍了 Git 基础知识、深度理解 Git 概念对现代软件开发至关重要的原因,以及如何使用 Git 开发软件。 我们的侧重点仍是软件开发的实现部分,但本部分会介绍:
大家都搭建了测试环境。
有些人很幸运,可以在完全独立的环境中运行生产。
-- 佚名
.
在这一系列文章中,我想向大家介绍并探讨使用 InterSystems 技术和 GitLab 进行软件开发可以采用的几种方式。 我将介绍以下主题:
第一部分将介绍现代软件开发的基础 – Git 版本控制系统和各种 Git 流程。
各位社区成员,大家好,
利用面向您的组织中的各个角色提供的全套 InterSystems 学习资源(在线或面授形式),您可以全面挖掘 InterSystems IRIS 的潜力,并帮助您的团队完成入门流程。 开发者、系统管理员、数据分析师和集成商可以快速上手。
在深入学习角色特定的资源之前,我们先来总体了解一下现有的学习资源:
有两篇很棒的有关删除消息关联的孤儿记录的内容以及如何处理孤儿的问题的WRC议最佳实践文章Ensemble Orphaned Messages | InterSystems Developer Community | Best DeleteHelper - A Class to Help with Deleting Referenced Persistent Classes (intersystems.com)
本文并不是要取代 Intersystems 专业人员撰写的这些文章,而是要在此基础上介绍我们如何利用这些信息和其他讨论(包括我们实际清理这些数据的方法)来帮助我们的数据库变得更加紧凑。
我们的备份越来越多。年初的时候,我们遇到过一台服务器被强制故障的情况,需要进行还原。由于数据库庞大,即使复制这个数据库也需要很长时间,更不用说还原重建shadow服务器了。因此,我们不得不决定最终解决这一增长问题。最初的原因已经确定
理解你的数据您在数据库中存储了哪些数据?您是否有必须保存在记录表中的数据?
最近有某国内三甲医院为满足评级和飞行检查要求,希望提升HIS和IRIS的SQL查询效率,客户和实施工程师整理了一个慢查询的SQL列表, 有一些查询比较慢, 查询时间在甚至大于60分钟。
在我们和厂商共同努力下,对整个库的SQL查询做了优化。 下表是记录了我们在进行了大部分优化工作后的结果,您可以看到大多查询从几十分钟减少到了几十秒甚至1秒以内。其中有几个慢到几分钟的查询,最后经过细调, 也把查询耗时减少到了一分钟以内。 优化的效果还是很明显的。
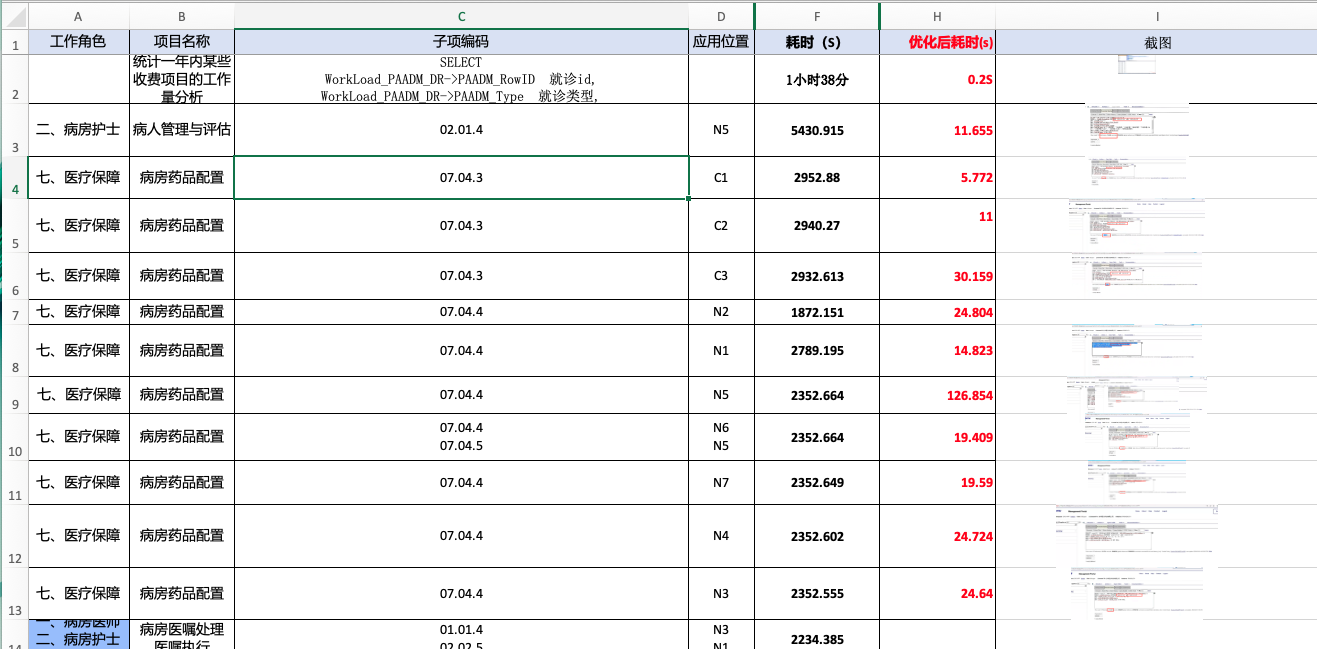
这里我分享一下操作的要点,以便给其他有同样问题的客户一个思路。
其实如果您看过我前面的帖子,应该已经有了基本的概念。我就把工作流程总结一下,其实就这么几个步骤:
步骤一:
检查硬件配置。 配置中和SQL性能相关的有这么几个: 1. 数据缓存大小,应该至少为物理内存的一半以上。 2. BBSIZE, 也就是单个进程最大的内存占用,对应不同的Caché/IRIS版本和不同的应用,这个配置有区别,但当然是越大越好,询问您的实施工程师配置是否正确。 3. 是否使用了大页内存,这个能从messages.log里看到。
步骤二
执行Tunetable。 在上面说的这个客户的系统上从来没人执行过Tunetable, 因此SQL引擎其实是没法正确工作的。执行后基本可以解决80%的慢SQL问题。时间短风险小见效快, 找个半夜业务小的时候直接在生产环境执行。
SQL查询优化器一般情况下能给出最好的查询计划,但不是所有情况都这样,所以InterSystems SQL还提供了一个方式, 也就是在查询语句里加入optimize-option keyword(优化关键字), 用来人工的修改查询计划。
比如下面的查询:
SELECT AVG(SaleAmt) FROM %PARALLEL User.AllSales GROUP BY Region
其中的%PARALLEL, 就是最常用的优化关键字, 它强制SQL优化器使用多进程并行处理这个SQL。
您可以这样理解: 如果查询优化器足够聪明,那么绝大多数情况下,根本就不需要优化关键字来人工干预。因此,您也一定不奇怪在不同的IRIS/Caché版本中, 关键字的表现可能不一样。越新的版本,应该是越少用到。比如上面的%PARALLEL, 在Caché的大多数版本中, 在查询中加上它一般都能提高查询速度,而在IRIS中,尤其是2023版本以后, 同样的SQL查询语句,很大的可能查询优化器已经自动使用多进程并行查询了,不再需要用户人工干预了。
因此,先总结有关优化关键字的要点:
优化关键字主要是FROM语句中使用。 UPDATE, INSERT语句也有可以使用的关键字,比如%NOJOURAL等等, 这里我不介绍了,请各位自己查询文档。
SQL性能监控是DBA最重要的日常工作。经常被问起:"Caché/IRIS怎么发现慢SQL"? 答案很简单: 到管理门户的SQL页面,点开如下的“SQL语句“子页, 您能看到这个命名空间的所有执行过的SQL语句,知道每个SQL语句执行了多少次,平均执行时间是多少, 被那个客户端编译的,第一次执行是那一天等等。
请看下面的截图
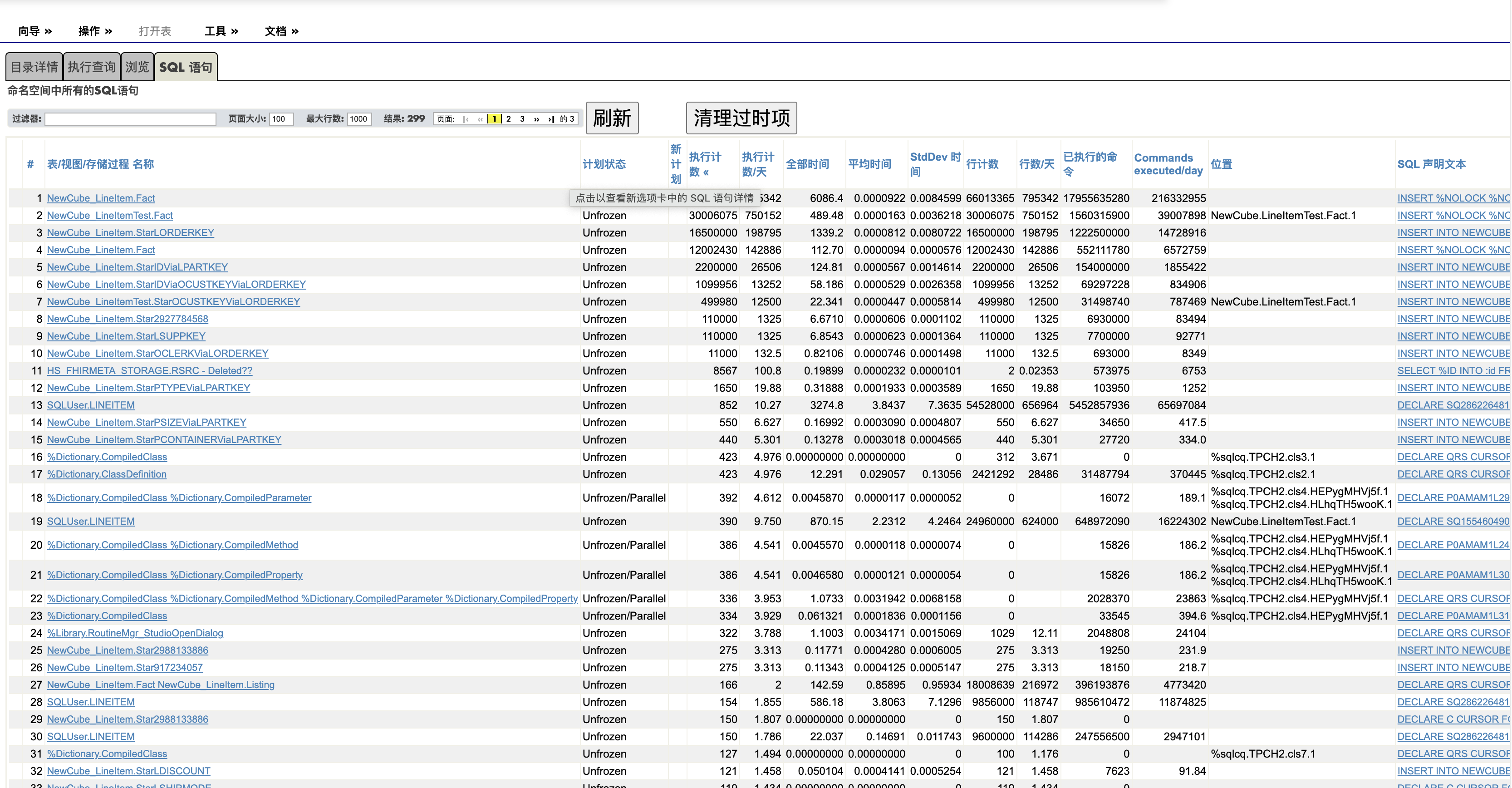
图中的各个栏目基本都不需要解释,有个别的内容在这里总结一些:
表/视图/存储过程名称:列出这个查询使用的所有的表/视图/存储过程的名字。如果你想看某个表有关的查询,可以使用上面的过滤器。
位置(Location) : 对于动态查询, 列出所使用的缓存的查询的类名,对于嵌入SQL(Embedded SQL)查询,列出使用的routine名字。
每个字段的标题栏可以用于排序,比如上图是按执行次数倒序显示的,所以前几位都是执行了很多的INSERT。 如果是日常维护查找慢SQL, 您可以按平均时间倒序显示。
计划状态: 通常是"Unfrozn"或者“Unfrozen/Parallel"。除非您需要升级或者有“Frozen Qeury Plan“的需要,您可以不关心这个栏目。
用鼠标单击上图的最左列或者最右列“SQL声明文本”, 会显示这个SQL语句的详细执行数据。 注意这个页面上的两个按钮: “导出” 和**”查询测试“**, 您可以试试它们。
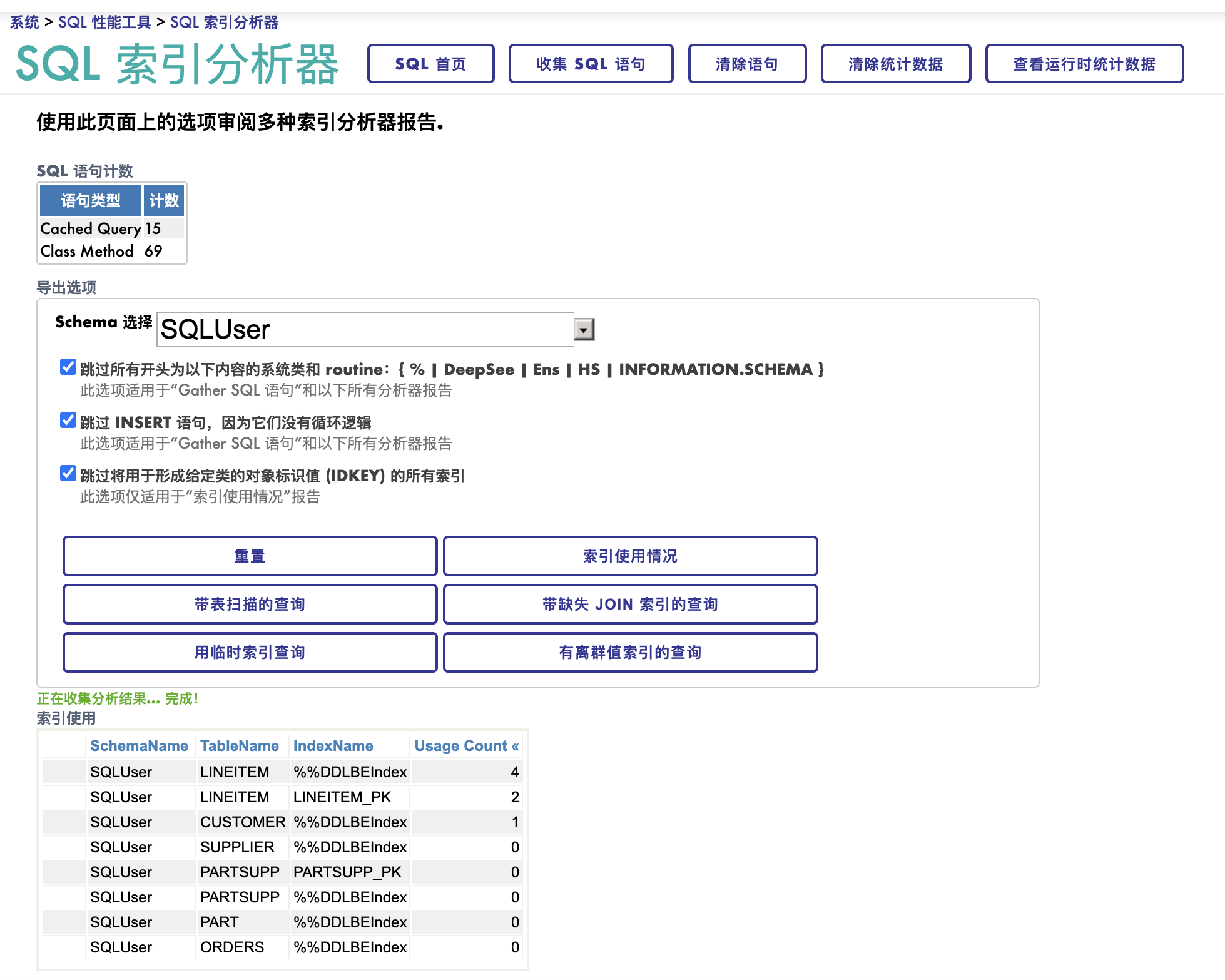
索引分析器工具用来分析索引的使用情况,对DBA和开发者非常有用。 他们需要知道那些查询进行了全表扫描,那些查询缺失了索引, 而那些索引从来又从来没有被用过。多余的索引降低系统性能,浪费了磁盘空间。
索引使用情况
到“管理门户”的" 系统 > SQL 性能工具 > SQL 索引分析器", 点击**“索引使用情况”**, 您将看到这样的图
执行SQL语句查询会带来更多的灵活性。上面的查询可以写成下面这个SQL,
SELECT TableName, indexname, UsageCount
FROM %SYS_PTools.UtilSQLAnalysisDB order by usagecount desc
2016年以后的Caché版本就已经有了'索引使用情况'的查询。使用管理门户没有区别, 但SQL语句不同,使用的是比较老的类和表名,各位请参考文档。
注意上图中另外几个按钮,它们的介绍在文档的这个链接, 简单的做个翻译:
全表扫描的查询:
可识别当前命名空间中进行全表扫描的所有查询。应尽可能避免全表扫描。全表扫描并非总能避免,但如果某个表有大量全表扫描,则应检查为该表定义的索引。通常情况下,表扫描列表和临时索引列表会重叠;修复一个会移除另一个。结果集列出了从最大块计数到最小块计数的表。显示计划链接可显示语句文本和查询计划。
为什么要读Query Plan, 在线文档中有句话是这么说的:
While the SQL compiler tries to make the most efficient use of data as specified by the query, sometimes the author of the query knows more about some aspect of the stored data than is evident to the compiler. In this case, the author can make use of the query plan to modify the original query to provide more information or more guidance to the query compiler.
翻译一下是这样:系统给你的查询计划并不总是最好的,如果您能对查询计划,可以人工做更精细的优化。
我们先看看读Query Plan的几个基本知识:
MAP
An SQL table is stored as a set of maps. 您有看到3种map: Master map, index map, bitmap.
# 回表读主数据,
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
# 读普通索引
Read index map DWBC.CT_MDRDictionary(T1).UniCodeIdx, using the given %SQLUPPER(UniCode), and getting T1.ID.
# 读bitmap索引
Read bitmap index My.ppl1.idxWLRecDep, looping on %SQLUPPER(WLRecDep) (with a given set of values) and bitmap chunks.
这个帖子内容有点深。如果您读的有困难,请直接跳过这篇,对绝大多数IRIS/Caché使用者,它一点都不重要。
数据库表的Collation(排序规则)本来是一个非常简单的概念。说到它是因为曾经发现过由Collation引起的性能问题。
我试图用一句话来解释数据库的排序规则:
很简单,在表一级定义Collation的SQL语句是:
CREATE TABLE Sample.MyNames (
LastName CHAR(30),
FirstName CHAR(30) COLLATE SQLstring)
事情在IRIS/Caché里变的有点复杂。
Bitmap索引是指对某个,或者某几个字段建立的bit map(位图映射)。如果是对整个表的记录,也就是表的%ID做位图映射,得到的特殊的bitmap索引在IRIS/Caché里被称为Bitmap Extent。
建立Bitmap Extent索引的目的就是加快COUNT(*)的执行。提高了多少呢? 下面两个显示的是最简单的全表查询花费的时间:
相差有几百倍。
.png)
有关Bitmap Extent你需要了解:
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
CREATE BITMAPEXTENT INDEX Patient ON TABLE Sample.Patient