供应链是指由公司业务领域及其供应商和合作伙伴(利益相关者)执行的一系列流程和活动,从原材料采购、生产到交付给最终消费者。利用 InterSystems IRIS 的协调功能,供应链管理解决方案可以更好地管理供应链:
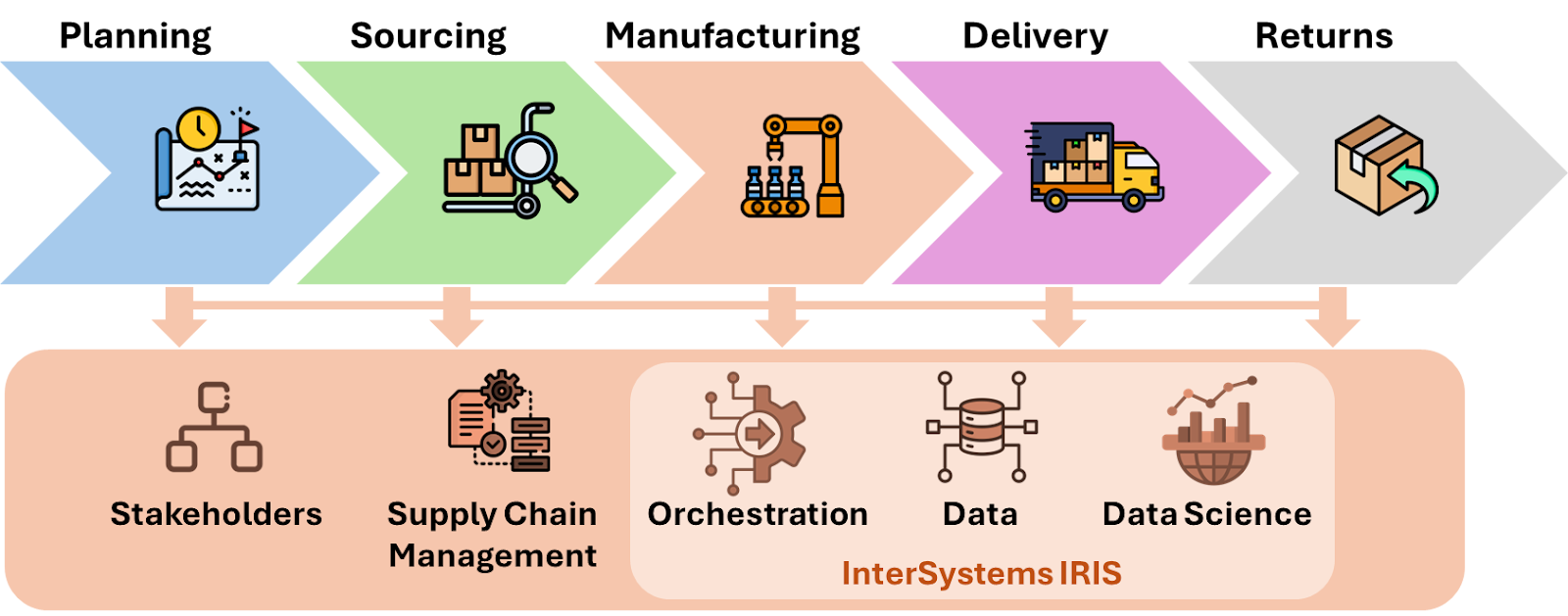
供应链是指由公司业务领域及其供应商和合作伙伴(利益相关者)执行的一系列流程和活动,从原材料采购、生产到交付给最终消费者。利用 InterSystems IRIS 的协调功能,供应链管理解决方案可以更好地管理供应链:
现代数据架构利用实时数据捕获、转换、移动和加载解决方案来构建数据湖、分析仓库和大数据存储库。它能够分析来自不同来源的数据,而不会影响使用这些数据的操作。要实现这一目标,必须建立连续、可扩展、弹性和稳健的数据流。最常用的方法是 CDC(变更数据捕获)技术。CDC 监控小型数据集的生产,自动捕获这些数据,并将其传送到一个或多个接收方,包括分析数据存储库。这样做的主要好处是消除了分析中的 D+1 延迟,因为数据一产生就会在源端被检测到,随后被复制到目的地。
本文将展示 CDC 场景中最常见的两种数据源,既可以是源数据源,也可以是目的地数据源。对于数据源(origin),我们将探讨 SQL 数据库和 CSV 文件中的 CDC。对于数据目的地,我们将使用列式数据库(典型的高性能分析数据库场景)和 Kafka 主题(将数据流传输到云和/或多个实时数据消费者的标准方法)。
本文将为以下互操作场景提供一个示例:

嗨社区,
这篇文章公开介绍我的 iris-fhir-client 客户端应用。
iris-fhir-client 可以可以借助嵌入式 python 连接到任何开放的 FHIR 服务器 fhirpy 图书馆.
通过终端和使用 CSP Web 应用程序获取资源信息。
在创建一个或多个立方体后,你通常会创建并打包一组透视表和仪表盘,而用户通常会根据需要创建新的透视表和仪表盘。
本章简要地引导你了解创建透视表和仪表盘的过程。它包括以下几个步骤。
在本教程的前面,我们创建了一个使用Patients cube的透视表。现在让我们创建使用你的新立方体Tutorial的透视表。
一个主题区是一个子立方体,可以选择覆盖项目的名称。你定义一个主题区是为了使用户能够关注较小的数据集,出于安全原因或其他原因。本章讨论了以下主题。
在本教程中,我们创建了两个主题区域,按邮政编码划分患者:
要创建主题区域,请做以下工作。
SELECT FROM [PPatients]
%FILTER %OR({[HOMED].[H1].[ZIP CODE].到目前为止,我们所创建的每个维度都包含一个具有一个level的层级结构。在这一节中,我们将在HomeD维度的层级结构中添加一个level。
在现实中,邮政编码和城市之间存在着多对多的关系,所以两者都不是对方的父级。
当我们添加邮政编码级别时,我们把它放在城市级别之后,这意味着城市是邮政编码的父级。这影响了系统为ZIP Code生成成员的方式。
点击主页,Analytics - > 模型。
.png)
系统会创建cube类,你也可以在Studio中查看和修改。
类浏览器提供了你的基类的类属性(除了关系属性)的有用视图,这使得基于这些属性创建DeepSee元素非常容易。然而,重要的是要知道,尽管这个视图提供了一个访问某些属性的方便方法,你也可以使用源表达式来访问任何数据。这些源表达式是在构建cube时进行评估的,因此不会影响你的运行时性能。
注意:基表是Patients,这意味着所有的度量都是关于病人的数据总结。
select count(*) as "count" ,avg(age) as avgage from BI_Study.Patient
InterSystems DeepSee的目的是使你能够将BI嵌入到你的应用程序中,这样你的用户就可以对他们的数据提出和回答复杂的问题。你的应用程序可以包括仪表盘,它包含图形部件。这些部件用来显示数据,由透视表和KPIs(关键绩效指标)驱动。对于一个透视表,用户可以显示一个列表,用其显示源值。
透视表、KPIs和列表是查询,在运行时执行。
数据透视表可以对运行时的输入作出反应,如用户的过滤器选择。在内部,它使用一个MDX(MultiDimensional eXpressions)查询,与DeepSee cube进行通信。一个cube由一个事实表和其索引组成。一个事实表由一组事实(行)组成,每个事实对应于一个基本记录。例如,这些事实可以代表病人或部门。DeepSee还生成了一组维度表(level tables)。所有的表都是动态维护的,根据你的配置和实现,DeepSee检测你的事务表的变化,并传播到事实表。当用户在分析器中创建透视表时,DeepSee会自动生成一个MDX查询。
KPI也可以对运行时的用户输入做出反应。在内部,它使用MDX查询(与DeepSee立方体)或SQL查询(与任何表)。在这两种情况下,你都可以手动创建查询,或从其他地方复制它。
列表显示来自用户选择的透视表行的源记录的选定值。在内部,一个列表是一个SQL查询。你可以指定要使用的字段,让DeepSee生成实际的查询。
比较不同的商业智能技术是非常有趣的。我很好奇它们在功能、开发工具、速度和可用性方面有什么不同。
在这个应用程序中,我选择了一个有欧洲各国水状况的数据集。这是一个开源的数据集,包含1991年到2017年的观测数据。
团队和我决定使用IRIS BI、Tableau、PowerBI和InterSystems Reports(由Logi Reports驱动)在这个BI数据集的基础上制作一个模型
对于前端,我们通过Embedded Python在PythonFlask中制作了一个网页界面。
顺便说一下,其结果可以在这个网页上看到:http://atscale.teccod.com:8080/
你可以看看demo stand (演示台),因为从资源库部署一个容器可能需要多至20分钟的时间。大量的python包,后面会有更多的原因。
主页面
事实上,数据似乎很小,期间只有17年 :)
因此,在现有的基础上,我想延续数据集,为此使用了一个神经网络。使用同样的嵌入式Python,使用了Tensorflow,这个包下载后占据了511MB,不要惊讶
实际上,这也是容器部署时间长的原因--为神经网络下载了很多包,相当多的相关包,安装时间很长。不过会有一篇关于神经网络和Integrated ML(一体化机器学习)的单独文章,我很快会发表。
我还要说的是,预测的结果被输入到同一个数据库,所以你可以通过BI工具看到数据集。
我们很高兴与你分享有趣的信息,以及告诉你为什么Python是好的,它被用在哪里。
其中使用最多的库是NumPy和Pandas。NumPy(Numerical Python)用来对大型数据集进行分类。它简化了数组上的数学运算及其矢量化。Pandas提供两种数据结构:系列Series(一个元素列表)和数据框架DataFrames(一个有多列的表格)。这个库将数据转换为数据框架,允许你删除和添加新的列,以及执行各种操作。
Python为数据分析项目提供了无数的工具,可以帮助完成任何任务。
以下步骤展示如何显示 /api/monitor 服务提供的指标列表示例。
在上个帖子中,我概述了以 Prometheus 格式显示 IRIS 指标的服务。 该贴介绍了如何在容器中设置和运行 IRIS 预览版 2019.4,然后列出了指标。
本帖假定您已安装 Docker。 如果未安装,现在就为您的平台安装吧 :)
按照预览发行版的下载说明下载预览版许可证密钥和 IRIS Docker 映像。 例如,我选择了 InterSystems IRIS for Health 2019.4。
按照 Docker 容器中的 InterSystems 产品初见中的说明操作。 如果您熟悉容器,请跳转到标题为“下载 InterSystems IRIS Docker 映像”的部分。
以下终端输出说明了我用来加载 docker 映像的过程。 docker load 命令可能需要几分钟的时间才能运行;
$ pwd
/Users/myhome/Downloads/iris_2019.4
$ ls
InterSystems IRIS for Health (Container)_2019.4.0_Docker(Ubuntu)_12-31-2019.ISCkey irishealth-2019.4.0.379.0-docker.2020 年席卷全球的新冠疫情使每个人都在关注与 COVID-19 有关的新闻和数字。
为什么不趁这个机会去创造一些简单直观的东西,来帮助关注全球的疫苗接种数量呢?
为了应对这一挑战,我使用了 Our World in Data 提供的数据,他们的使命是提供解决全球最大问题所需的研究和数据。
他们在 Github 上有一个专门的 COVID-19 数据仓库,我采用了疫苗接种数据来完善我的跟踪器。
如果你不了解他们,去调查一下吧,这值得你花上一些时间。 Github 仓库
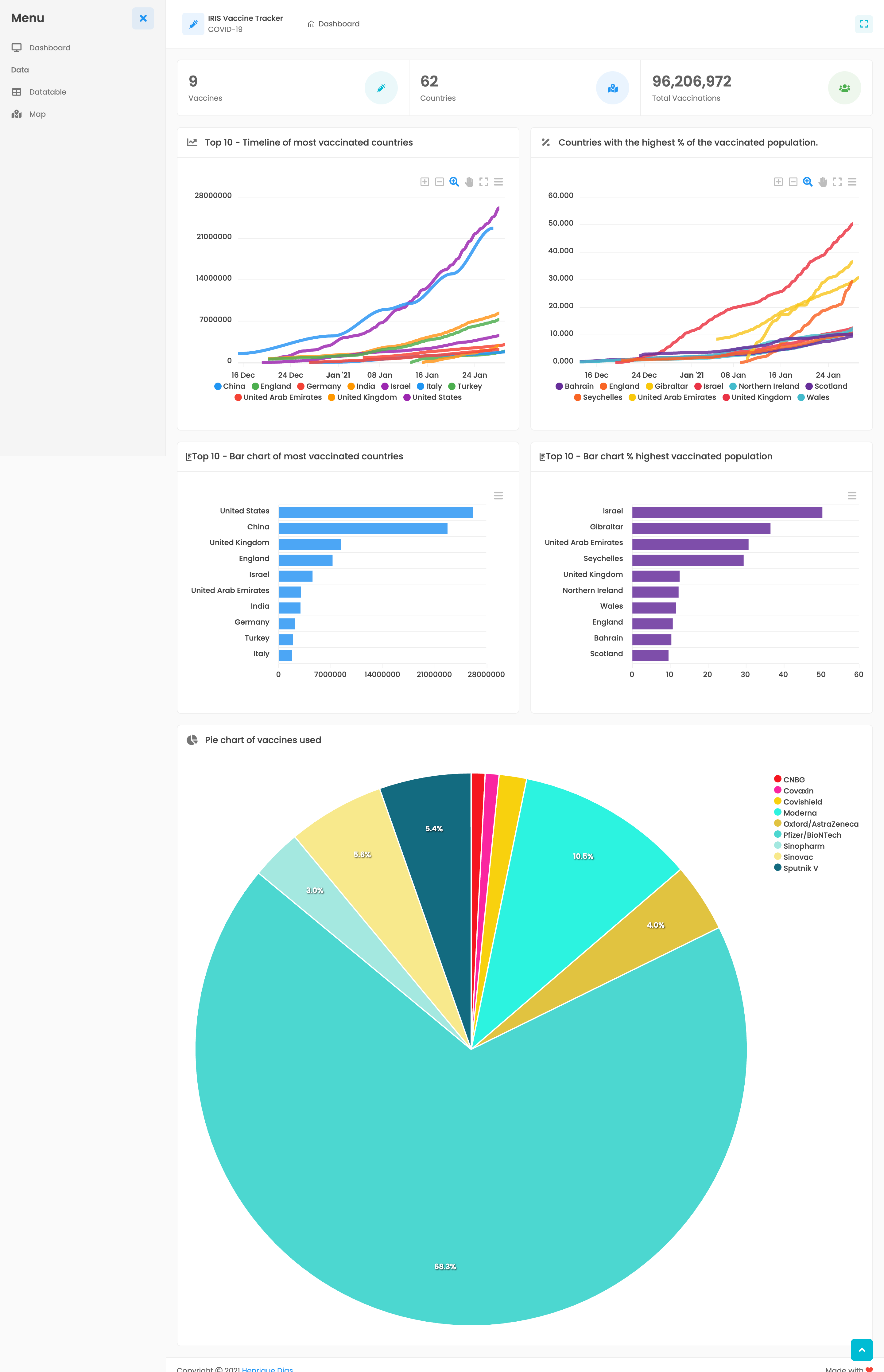
应用程序 iris-vaccine-tracker 有三个不同页面。
主仪表板提供全球疫苗接种情况的快速概览。
第一个小组件提供以下信息:
第二个小组件提供了一个疫苗接种时间线视图,其中包括疫苗接种数量最多的前 10 个国家/地区。
第三个小组件提供了排名靠前的国家/地区的条形图,显示迄今为止的疫苗接种总数。
最后一个小组件展示疫苗的分布情况,哪些疫苗正在被使用以及所占的百分比。
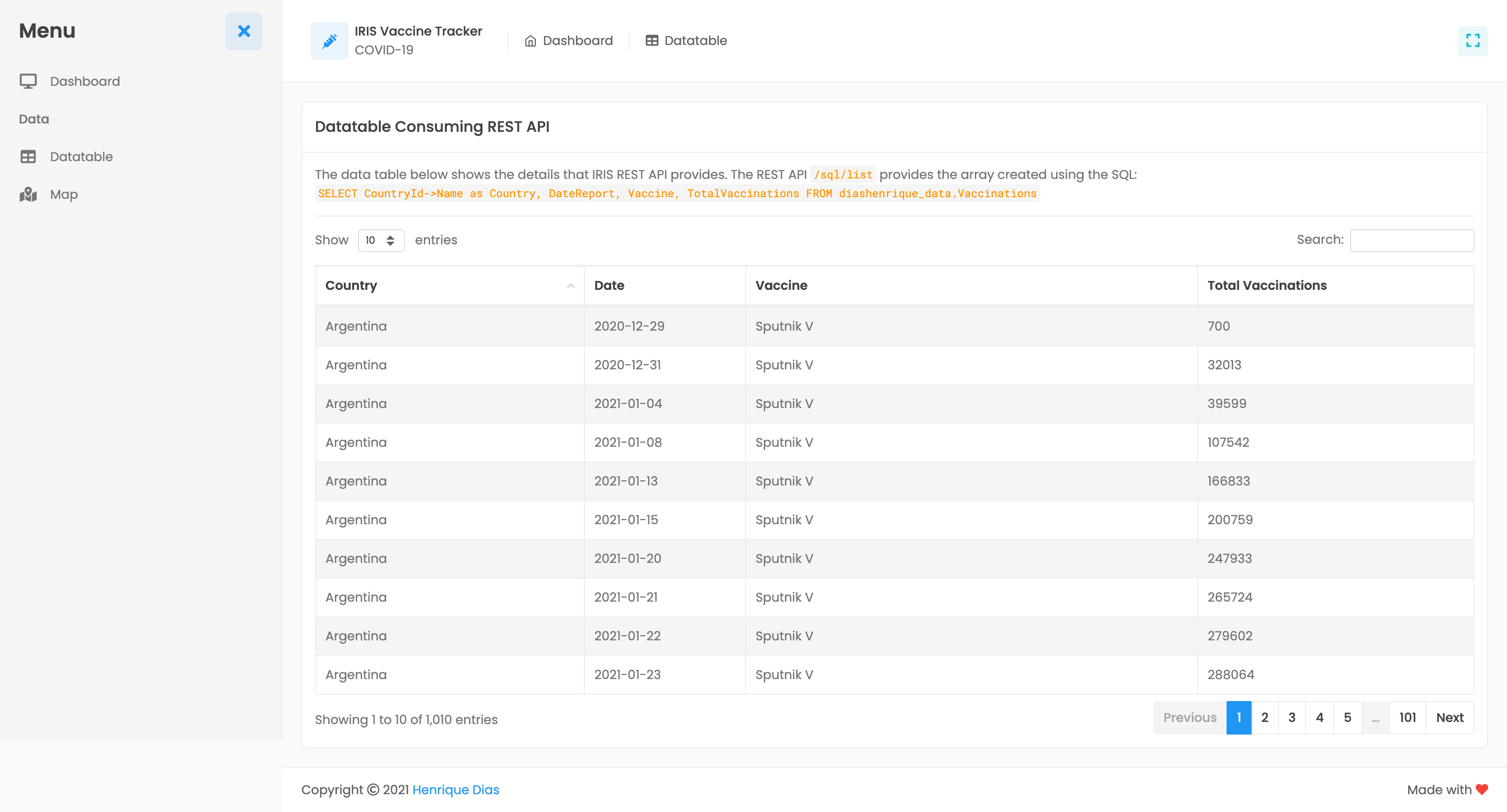
数据表显示主仪表板汇总数据的详细信息。
热图是一种不同的视图,它使用我们已经在主仪表板和数据表中使用的信息,但现在使用 Country 持久化表提供的详细信息。
大家好, 现在是九局下半,但在我们的技术世界大赛还留了几手
大家好!
我想跟大家分享一个个人项目,该项目始于工作中的一个简单需求:“能否知道我们使用了多少个Caché许可证?”
在阅读社区的其他文章时,我发现了一篇David Loveluck写的非常棒的文章:APM——使用Caché History Monitor。
我根据David的这篇文章,开始使用Caché History Monitor并显示所有这些信息。
在面临“选择哪种很酷的技术”这个问题时,我决定使用简单而强大的CSP,这样我的客户可以认识到Caché不仅仅是MUMPS/终端。
在创建了页面以显示许可、数据库增长和CSP会话的历史记录后,我决定为System Dashboard和进程页面创建一个新设计。
我的Caché实例运行得良好。
但是,如果使用IRIS呢?
我们不必等待SAM发布才开始规划和试用该API来监控IRIS实例。在以后的文章中,我将更深入地探讨可用的指标及其意义,并提供一些交互式仪表板的示例。首先,我将介绍一下相关背景和一些问题及答案。
IRIS(和Caché)一直在收集自身及其运行平台的数十个指标。收集这些指标来监控Caché和IRIS的方法向来有很多。我发现,很少有安装软件使用IRIS和Caché的内置解决方案。譬如,History Monitor作为性能和系统使用指标的历史数据库,已经推出很长时间了,但它没有简便方法可实时显示这些指标和仪表系统。
IRIS平台解决方案(以及整个业界)正在从仅在一些本地实例上运行的单体式应用程序过渡到“随处”部署的分布式解决方案。在许多用例中,原有的IRIS监控方案并不适用于这些新的模式。InterSystems没有做重复工作,而是将目光投向当前流行的、经过验证的监控和告警开源解决方案。
{kind=link}