那些已经与ECP合作过的人可能知道它不仅在操作系统,处理器技术(big-little-endian),但在C / E的各个版本中也有限制。
此交叉版本功能还包括IRIS(针对2020.1进行了验证)和C / E(2018.3)
第四章 使用Setup和tear Down方法执行测试
示例:使用Setup和tear Down方法执行测试
以通常的方式执行新的单元测试。
- 在一直在使用的命名空间中打开终端。
- 将
^UnitTestRoot的值设置为包含测试类的目录的父级:
USER> Set ^UnitTestRoot="c:\unittests"
- 使用
%UnitTest.Manager执行测试:
USER> Do ##class(%UnitTest.Manager).RunTest("mytests")
- IRIS加载测试类、编译类、执行测试并向终端发送报告。
===============================================================================
Directory: C:\unittests\mytests\cls\MyPackage\
===============================================================================
mytests\cls\MyPackage begins .
Load of directory started on 01/09/2018 14:36:57 '*.xml;*.XML;*.cls;*.mac;*.int;*.webservice服务,在浏览器中调用成功,在soapui工具中调用失败“wsse:FailedAuthentication”
我创建了 iris-fhir-portal 来参加当前竞赛 **InterSystems IRIS for Health FHIR,**本篇快速概述旨在介绍我的应用程序提供的功能。
iris-fhir-portal 的目标是说明使用 IRIS for Health 中的 FHIR 功能创建患者图表并让用户拥有自己的数据有多么简单。
第三章 执行测试
示例:执行测试
现在使用%UnitTest.Manager.RunTest执行单元测试。以下是方法:
- 在包含单元测试的名称空间中打开终端;在本例中为用户。如果终端未在正确的命名空间中打开,请使用ZN更改命名空间。
- 将
^UnitTestRoot全局值设置为包含导出的测试类的目录的父级。
DHC-APP>Set ^UnitTestRoot="d:\Temp"
- 使用方法
%UnitTest.Manager.RunTest执行测试。
DHC-APP>do ##class(%UnitTest.Manager).RunTest("test")
- IRIS从
XML文件加载测试类,编译类,执行测试,从服务器删除测试代码,并向终端发送报告。
HC-APP>do ##class(%UnitTest.Manager).RunTest("test")
===============================================================================
Directory: D:\Temp\test\
===============================================================================
test begins .FHIR 术语服务规范描述了一组对 CodeSystem、ValueSet 和 ConceptMap 资源的操作。 在这些操作中,以下四种操作似乎是最为广泛采用的:
| CodeSystem | ValueSet |
|---|---|
| $lookup $validate-code |
$expand $validate-code |
开发该规范的部分实现一直是探索 IRIS for Health 2020.1 中引入的全新 FHIR 框架的有效途径。 本实现包括上述四种操作,并支持与 CodeSystem 和 ValueSet 资源的读取和搜索交互。
需要注意的是,本实现使用普通 ObjectScript 持久化类作为源术语表。
第二章 使用%UnitTest进行单元测试
本教程的第二部分介绍了如何使用%UnitTest包对InterSystems IRIS代码进行单元测试。完成本教程的这一部分后,将能够:
- 解释
%UnitTest包中三个主要类的角色。 - 列出基于
%UnitTest包的单元测试类和方法的要求。 - 创建并执行方法的单元测试。
- 浏览
%UnitTest.Manager创建的测试报告。 - 执行单元测试时,使用
%UnitTest.TestCase方法初始化和还原数据库数据。
什么是%UnitTest?
%UnitTest包是一组为IRIS提供测试框架的类。在结构上,它类似于xUnit测试框架。%UnitTest为创建和执行以下各项的单元测试提供类和工具:
- 类和方法
- ObjectScript例程(routines)
- InterSystems SQL脚本
- Productions
创建和执行单元测试套件
以下是创建和执行一套单元测试的基本步骤:
- 创建一个(或多个)包含要测试的方法的类。
- 创建扩展
%UnitTest.TestCase的测试类(或多个测试类)。 - 将方法添加到将测试方法输出的测试类。在每个方法中至少使用一个断言(
AssertX宏)。每个测试方法名称都以Test开头。 - 将测试类导出到文件。
- 打开终端并切换到包含要测试的类的名称空间。
第一章 单元测试概述
本教程的第一部分概述了单元测试。完成本教程的这一部分后,将能够:
- 定义单元测试并区分单元测试和集成测试
- 列出单元测试的几个好处
- 描述InterSystems IRIS
%UnitTest包和xUnit测试框架之间的相似性。 - 列出软件开发中测试优先方法经常声称的几个好处。
什么是单元测试?
单元测试是对单个代码模块的正确性的测试,例如,方法或类的测试。通常,开发人员在开发代码时为其代码创建单元测试。典型的单元测试是一种执行方法的方法,该方法测试并验证该方法是否为给定的一组输入生成了正确的输出。
单元测试不同于集成测试。集成测试验证了一组代码模块交互的正确性。单元测试仅单独验证代码模块的正确性。一组代码模块的集成测试可能会失败,即使每个模块都通过了单元测试。
为什么要进行单元测试?
单元测试提供了许多好处,包括:
- 提供代码模块是否正确的验证。这是单元测试的主要原因。
- 提供自动回归测试。更改代码模块后,应重新运行单元测试,以确保代码模块仍然正确。也就是说,应该使用单元测试来确保更改没有破坏代码模块。理想情况下,所有代码模块的单元测试都应该在更改任何一个模块之后运行。
- 提供文档。通常,代码模块的单元测试与代码模块一起交付。检查单元测试提供了大量有关代码模块如何工作的信息。
XUnit测试框架
单元测试框架是为开发和执行单元测试提供支持的类包。
Caché Global
第一章 简介global☆☆☆☆☆
第二章 全局变量结构(一)☆☆☆☆☆
第二章 全局变量结构(二)☆☆☆☆☆
第三章 使用多维存储(全局变量)(一)☆☆☆☆☆
第三章 使用多维存储(全局变量)(二)☆☆☆☆☆
第三章 使用多维存储(全局变量)(三)☆☆☆☆☆
第三章 使用多维存储(全局变量)(四)☆☆☆☆☆
第四章 多维存储的SQL和对象使用(一)☆☆☆☆☆
第四章 多维存储的SQL和对象使用(二)☆☆☆☆☆
第五章 管理全局变量(一)☆☆☆☆☆
第五章 管理全局变量(二)☆☆☆☆☆
第六章 临时全局变量和IRISTEMP数据库☆☆☆☆☆
前言
经过快一个月的连载 《Caché Global》 共12篇。对于刚接触M的语言的同学,由浅入深帮助你快速进步,对于老手,丰富更多的细节
涵盖以下主题:
- “简介”概述了全局变量的功能和用途。
- “全局变量结构”描述了全局变量是如何存储在磁盘上的,它们是如何命名和引用的,以及它们的结构。
- “使用多维存储(全局)”介绍如何以编程方式使用全局变量。
- “多维存储的SQL和对象使用”描述了对象和SQL引擎如何使用全局变量存储数据。
- “管理全局变量”介绍了主要从管理门户管理全局的工具。
- “临时全局变量和TEMP数据库”描述了如何使用临时全局变量来帮助进行复杂的处理。
第六章 临时全局变量和IRISTEMP数据库
对于某些操作,可能需要全局变量的功能,而不需要无限期保存数据。例如,可能希望使用全局对某些不需要存储到磁盘的数据进行排序。对于这些操作,InterSystems IRIS提供了临时全局机制。该机制的工作方式如下:
- 对于应用程序名称空间,可以定义一个全局映射,以便将具有特定命名约定的全局变量映射到
IRISTEMP数据库,该数据库是一个特殊的数据库,如下所述。
例如,可以定义一个全局映射,以便将名称为^AcmeTemp*的所有全局变量映射到IRISTEMP数据库。
- 当代码需要临时存储数据并再次读取它时,代码将向使用该命名约定的全局变量写入数据,并从全局变量读取数据。
例如,要保存值,代码可能会执行以下操作:
set ^AcmeTempOrderApp("sortedarray")=some value
然后,稍后代码可能会执行以下操作:
set somevariable = ^AcmeTempOrderApp("sortedarray")
通过使用临时全局变量,可以利用IRISTEMP数据库没有日志记录这一事实。因为数据库没有日记记录,所以使用该数据库的操作不会产生日记文件。日志文件可能会变得很大,并可能导致空间问题。但是,请注意以下几点:
不能回滚修改IRISTEMP数据库中的全局变量的任何事务;此行为特定于IRISTEMP。
Intersystems RIS 机器学习工具包, 包括Python/R/Julia, 支持协调管理基于云的高级分析服务,如微软Azure数据工厂和机器学习。
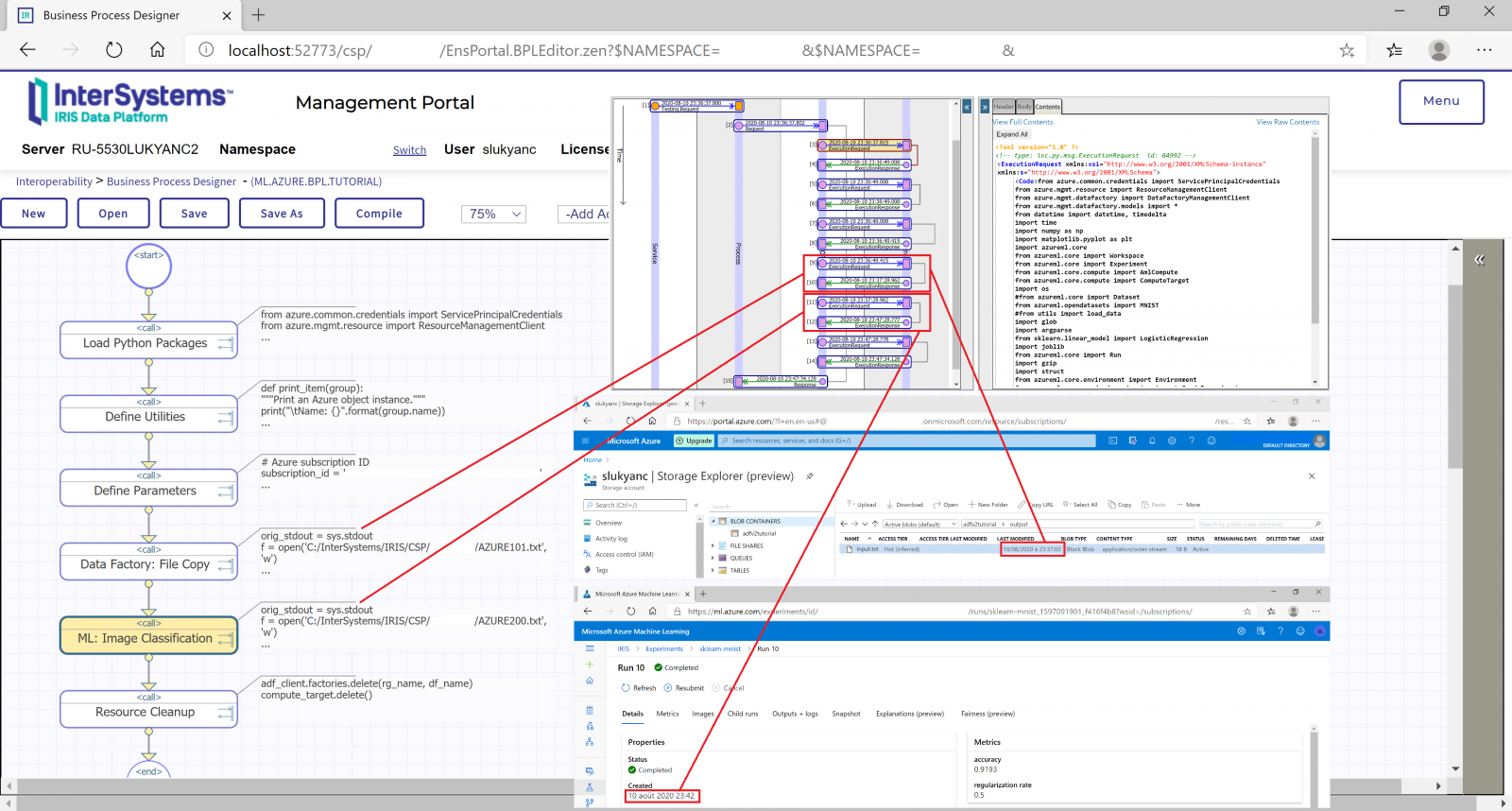
我找不到在Internet上连接到InterSystems Iris的spark或Kafka的情况。是否可以共享任何相关资源?
2020 年席卷全球的新冠疫情使每个人都在关注与 COVID-19 有关的新闻和数字。
为什么不趁这个机会去创造一些简单直观的东西,来帮助关注全球的疫苗接种数量呢?
为了应对这一挑战,我使用了 Our World in Data 提供的数据,他们的使命是提供解决全球最大问题所需的研究和数据。
他们在 Github 上有一个专门的 COVID-19 数据仓库,我采用了疫苗接种数据来完善我的跟踪器。
如果你不了解他们,去调查一下吧,这值得你花上一些时间。 Github 仓库
应用程序 iris-vaccine-tracker 有三个不同页面。
- 主仪表板
- 数据表,其中包含仪表板中呈现的数据的详细信息。
- 热图
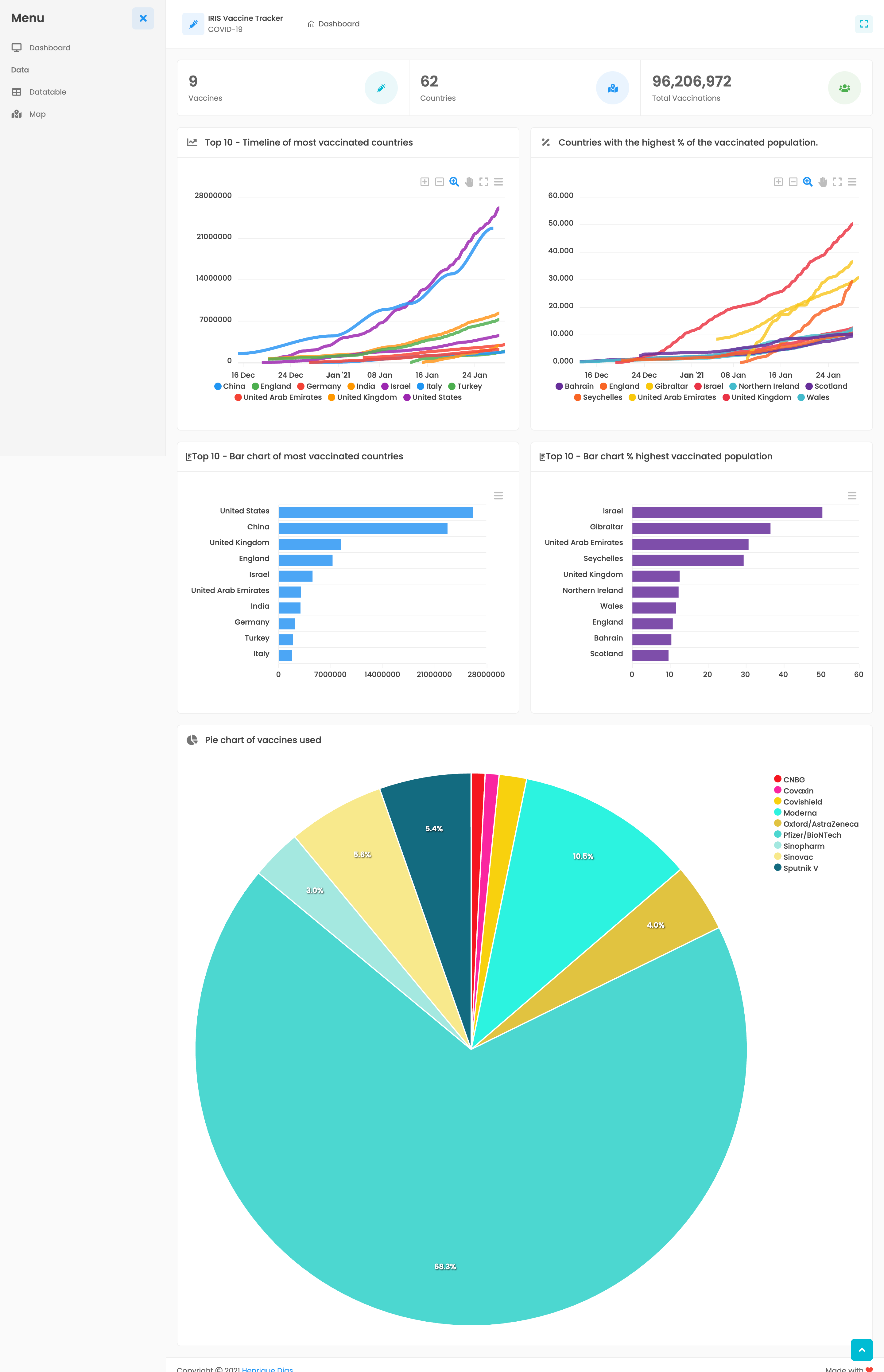
仪表板
主仪表板提供全球疫苗接种情况的快速概览。
第一个小组件提供以下信息:
- 用于接种人群的疫苗数量
- 提供疫苗接种信息的国家/地区数量
- 迄今已接种的疫苗总数。
第二个小组件提供了一个疫苗接种时间线视图,其中包括疫苗接种数量最多的前 10 个国家/地区。
第三个小组件提供了排名靠前的国家/地区的条形图,显示迄今为止的疫苗接种总数。
最后一个小组件展示疫苗的分布情况,哪些疫苗正在被使用以及所占的百分比。
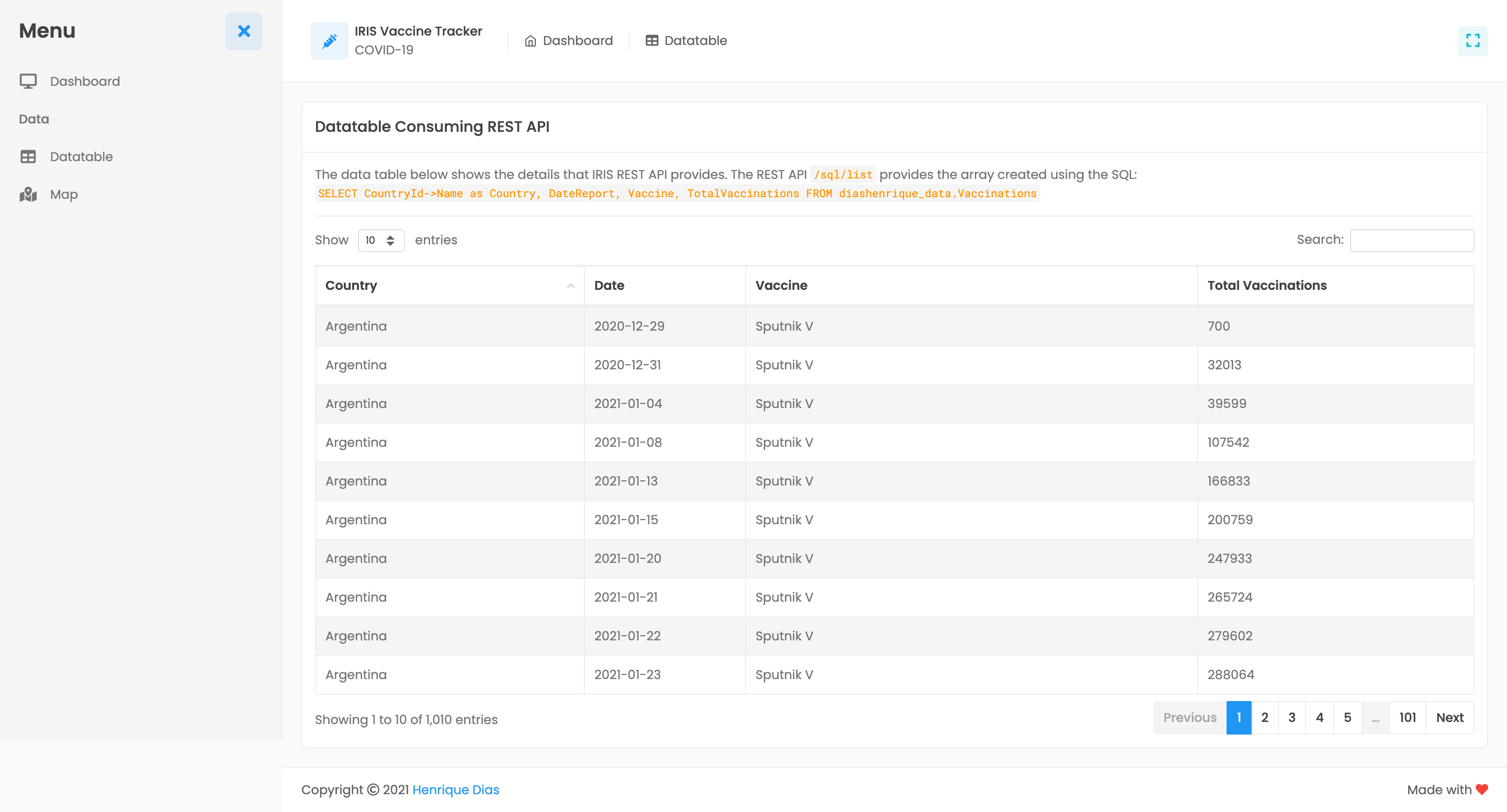
数据表
数据表显示主仪表板汇总数据的详细信息。
热图
热图是一种不同的视图,它使用我们已经在主仪表板和数据表中使用的信息,但现在使用 Country 持久化表提供的详细信息。
第五章 管理全局变量(二)
在全局变量中查找值
“查找全局变量字符串”页使可以在下标或选定全局变量的值中查找给定的字符串。
要访问和使用此页,请执行以下操作:
- 显示“全局变量”页。
- 选择要使用的全局变量。为此,请参阅“全局页简介”一节中的步骤2和3。
- 单击查找按钮。
- 对于查找内容,输入要搜索的字符串。
- (可选)清除大小写匹配。默认情况下,搜索区分大小写。
- 单击Find First或Find All。
然后,页面显示选定全局变量中下标或值包含给定字符串的第一个节点或所有节点。该表左侧显示了节点下标,右侧显示了相应的值。
- 如果使用的是Find First,请根据需要单击Find Next以查看下一个节点。
- 完成后,单击关闭窗口。
执行批量更换
注意:在进行任何编辑之前,请确保知道IRIS使用哪个全局系统,以及应用程序使用哪个全局系统;参见“一般建议”此选项会永久更改数据。不建议在生产系统中使用。
出于开发目的,“查找全局字符串”页面还提供了对全局节点中的值进行整体更改的选项。要使用此选项:
- 显示“全局”页面。
- 选择要使用的全局。为此,请参见“全球页面简介”一节中的步骤2和3
- 单击替换按钮。
- 使用此页面查找上一节中描述的值。
- 为“替换为”指定一个值。
- 单击全部替换。
- 单击确定确认此操作。然后,页面会显示变更的预览。
- 如果结果可以接受,请单击保存。
- 单击确定确认此操作。
第五章 管理全局变量(二)
在全局变量中查找值
“查找全局变量字符串”页使可以在下标或选定全局变量的值中查找给定的字符串。
要访问和使用此页,请执行以下操作:
- 显示“全局变量”页。
- 选择要使用的全局变量。为此,请参阅“全局页简介”一节中的步骤2和3。
- 单击查找按钮。
- 对于查找内容,输入要搜索的字符串。
- (可选)清除大小写匹配。默认情况下,搜索区分大小写。
- 单击Find First或Find All。
然后,页面显示选定全局变量中下标或值包含给定字符串的第一个节点或所有节点。该表左侧显示了节点下标,右侧显示了相应的值。
- 如果使用的是Find First,请根据需要单击Find Next以查看下一个节点。
- 完成后,单击关闭窗口。
执行批量更换
注意:在进行任何编辑之前,请确保知道IRIS使用哪个全局系统,以及应用程序使用哪个全局系统;参见“一般建议”此选项会永久更改数据。不建议在生产系统中使用。
出于开发目的,“查找全局字符串”页面还提供了对全局节点中的值进行整体更改的选项。要使用此选项:
- 显示“全局”页面。
- 选择要使用的全局。为此,请参见“全球页面简介”一节中的步骤2和3
- 单击替换按钮。
- 使用此页面查找上一节中描述的值。
- 为“替换为”指定一个值。
- 单击全部替换。
- 单击确定确认此操作。然后,页面会显示变更的预览。
- 如果结果可以接受,请单击保存。
- 单击确定确认此操作。
亲爱的社区开发者们,
我很高兴地向大家介绍一位我们的新版主@刘文艺。
大家好!
目前产品应用MIRROR来保证医院业务正常运行,但是其中MIRROR同步信息不包含(web应用配置信息、任务计划、sql网关等等),关于这些信息同步我们有没有更好的处理解决这个问题?其中,如果想要将代码等关键信息(可以作为业务恢复)进行跨服务器备份,比如:突发状况双机服务器无法恢复并提供服务,需要恢复生产业务,可利用这些备份信息可以快速恢复业务,应对这一类场景有没有好的解决方案?
期待解惑.
关键字:IRIS, IntegratedML, 机器学习, Covid-19, Kaggle
目的
最近,我注意到一个用于预测 Covid-19 患者是否将转入 ICU 的 Kaggle 数据集。 它是一个包含 1925 条病患记录的电子表格,其中有 231 列生命体征和观察结果,最后一列“ICU”为 1(表示是)或 0(表示否)。 任务是根据已知数据预测患者是否将转入 ICU。
这个数据集看起来是所谓的“传统 ML”任务的一个好例子。数据看上去数量合适,质量也相对合适。它可能更适合在 IntegratedML 演示套件上直接应用,那么,基于普通 ML 管道与可能的 IntegratedML 方法进行快速测试,最简单的方法是什么?
本贴提供了在 VMware ESXi 5.5 及更高版本的环境中部署 Caché 2015 及更高版本时,关于配置、系统规模调整和容量规划等方面的指南。
我假定您已经了解 VMware vSphere 虚拟化平台,所以直接给出推荐。 本指南中的推荐不特定于任何具体硬件或站点特定的实现,也不应作为规划和配置 vSphere 部署的全面指南,而是一份您可以做出选择的最佳实践配置清单。 我希望您的 VMware 专家实施团队能针对具体站点对这些推荐进行评估。
这里是 InterSystems 数据平台和性能系列的其他帖子的列表。
_注:_本帖更新于 2017 年 1 月 3 日,强调必须为生产数据库实例设置虚拟机内存预留,以保证 Caché 有足够内存可用,并且不会出现内存交换或膨胀而对数据库性能产生负面影响。 更多详细信息,请参见下面的内存部分。
在本帖中,我将展示使用_外部备份_来备份 Caché 的策略,以及与基于快照的解决方案集成的示例。 如今,大多数解决方案部署在基于 VMware 的 Linux 上,因此许多帖子都以展示解决方案如何集成 VMware 快照技术为例。
Caché 备份 - 包括电池?
Caché 安装后即包含 Caché 在线备份,可提供不间断的 Caché 数据库备份。 但随着系统规模的扩大,您应该考虑更高效的备份解决方案。 集成了快照技术的_外部备份_是推荐的系统(包括 Caché 数据库)备份解决方案。
外部备份有特殊注意事项吗?
外部备份的在线文档包含了全部详细信息。 一个关键考虑事项是:
“为确保快照的完整性,Caché 提供了在创建快照时冻结数据库写操作的方法。 在创建快照期间,只冻结对数据库文件的物理写入,从而允许用户进程继续在内存中不间断地执行更新。”
还需要注意的是,虚拟化系统上的部分快照过程会导致正在备份的虚拟机短暂暂停,这段时间通常称为关闭时间。 该时间通常不到一秒,因此不会被用户注意到,也不会影响系统运行,但在某些情况下,关闭时间可能较长。 如果关闭时间长于 Caché 数据库镜像的 QoS 超时时间,那么备份节点将认为主节点出现故障,并将进行故障转移。 在本帖的后面部分,我将说明在需要对镜像 QoS 超时时间进行更改时如何查看关闭时间。
部分 在上个帖子中,我们安排了使用 pButtons 进行 24 小时的性能指标收集。 在本帖中,我们将研究几个收集到的关键指标,以及它们与底层系统硬件的关系。 我们还将开始探索 Caché(或任一 InterSystems 数据平台)指标与系统指标之间的关系。 以及如何使用这些指标来了解系统的每日节拍率并诊断性能问题。
本周,我将关注 CPU - 主要硬件食物群之一 :) 一位客户请我就以下情况提供建议:他们的生产服务器已接近使用寿命终止,是时候更新硬件了。 他们还考虑通过虚拟化来整合服务器,并希望适当调整裸机或虚拟机的容量规模。 今天我们将关注 CPU,在后面的帖子中,我将介绍适当调整其他主要食物群(内存和 IO)规模的方法。
所以问题是:
- 如何将五年多以前对处理器的应用要求转换成针对当今的处理器?
- 目前的处理器有哪些是合适的?
- 虚拟化如何影响 CPU 容量计划?
本帖将展示为 InterSystems 数据平台上运行的数据库应用调整共享内存需求(包括 global 和例程缓冲区、gmheap 以及 locksize)的方法,以及在配置服务器和虚拟化 Caché 应用程序时应考虑的一些性能提示。 和以往一样,当我谈到 Caché 时,我指的是所有数据平台(Ensemble、HealthShare、iKnow 和 Caché)。
[本系列其他帖子的列表](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)
当我最初开始使用 Caché 时,大多数客户的操作系统是 32 位的,Caché 应用程序的内存有限且昂贵。 通常部署的英特尔服务器只有几个核心,唯一的扩展方式是选择大型服务器,或者使用 ECP 横向扩展。 现在,即使是基本的生产级服务器也具有多个处理器、几十个核心,并且最小内存为 128 或 256 GB,可能达到 TB。 对于大多数数据库安装,ECP 已被遗忘,我们现在可以在单台服务器上大幅提高应用事务处理速率。
关键字:深度学习,Grad-CAM,X 射线,Covid-19,HealthShare,IRIS
目的
在复活节周末,我谈到了一些针对 Covid-19 肺的深度学习分类器。 演示结果还算不错,似乎与当时有关该主题的一些学术研究刊物相吻合。 但它真的足够“好”吗?
最近,我偶然收听了一个关于“机器学习中的可解释性”的在线午餐网络讲座,Don 在演讲的最后谈到了这个分类结果:

上图也出现在 “Why Should I Trust You?” Explaining the Predictions of Any Classifier 这篇研究论文中。 我们可以看到,分类器实际上经过训练,以背景像素(如雪等野生环境)作为主要输入,对宠物狗和野狼进行分类。
这关乎我过去的兴趣,现在也激起一些好奇:
- 我们如何“观察”这些通常以“黑盒”形式表示的 Covid-19 分类器,了解哪些像素实际上促成了“Covid-19 肺”结果?
- 在这种情况下,我们可以利用的最简单的形式或工具是什么?
这也是篇简单的 10 分钟笔记。 最后,我会谈到为什么它也与我们即将推出的全新 IRIS 和 HealthShare 功能有关。
范围
幸运的是,过去几年中,各种 CNN 衍生分类器都有了方便的工具:
第四章 多维存储的SQL和对象使用(二)
索引
持久化类可以定义一个或多个索引;其他数据结构用于提高操作(如排序或条件搜索)的效率。InterSystems SQL在执行查询时使用这些索引。InterSystems IRIS对象和SQL在执行INSERT、UPDATE和DELETE操作时自动维护索引内的正确值。
标准索引的存储结构
标准索引将一个或多个属性值的有序集与包含属性的对象的对象ID值相关联。
例如,假设我们定义了一个简单的持久化MyApp.Person类,该类具有两个文本属性和一个关于其Name属性的索引:
Class MyApp.Person Extends %Persistent
{
Index NameIdx On Name;
Property Name As %String;
Property Age As %Integer;
}
如果我们创建并保存此Person类的多个实例,则生成的数据和索引全局变量类似于:
// data global
^MyApp.PersonD = 3 // counter node
^MyApp.PersonD(1) = $LB("",34,"Jones")
^MyApp.PersonD(2) = $LB("",22,"Smith")
^MyApp.提到临床医生与信息系统的交互,除外“病历书写”,恐怕最常见的临床场景就是“医嘱开具”了。医嘱是临床医生根据患者病史、体征、检验检查结果下达的医学指令,是医疗过程的重要环节和医疗质量的决定因素。在传统纸质医嘱时代,医生每天花费在医嘱开具、修改和确认等环节上的时间甚至接近于其与患者沟通的时间;且尽管上级医生、药剂师、护士等角色都会在不同阶段参与医嘱审核,依然难以避免医嘱差错的发生。因此,医学信息系统被广泛应用后,提升医嘱开具的便捷性和准确性成为其首当其冲的职责。那么,哪些系统功能是临床医生眼中的医嘱“助力神器”呢?
第四章 多维存储的SQL和对象使用(一)
本章介绍InterSystems IRIS®对象和SQL引擎如何利用多维存储(全局变量)来存储持久对象、关系表和索引。
尽管InterSystems IRIS对象和SQL引擎会自动提供和管理数据存储结构,但了解其工作原理的详细信息还是很有用的。
数据的对象视图和关系视图使用的存储结构是相同的。为简单起见,本章仅从对象角度介绍存储。
数据
每个使用%Storage.Persistent存储类(默认)的持久化类都可以使用多维存储(全局变量)的一个或多个节点在InterSystems IRIS数据库中存储其自身的实例。
每个持久化类都有一个存储定义,用于定义其属性如何存储在全局变量节点中。这个存储定义(称为“默认结构”)由类编译器自动管理。
默认结构
用于存储持久对象的默认结构非常简单:
- 数据存储在名称以完整类名(包括包名)开头的全局变量中。附加
“D”以形成全局数据的名称,而附加“I”作为全局索引。 - 每个实例的数据都存储在全局数据的单个节点中,所有非瞬态属性都放在
$list结构中。 - 数据全局变量中的每个节点都以对象
ID值作为下标。默认情况下,对象ID值是通过调用存储在全局变量数据根(没有下标)的计数器节点上的$Increment函数提供的整数。
例如,假设我们定义了一个简单的持久化类MyApp.Person,它有两个文本属性:
Class MyApp. 第三章 使用多维存储(全局变量)(四)
管理事务
InterSystems IRIS提供了使用全局变量实现完整事务处理所需的基本操作。 InterSystems IRIS对象和SQL自动利用这些特性。 如果直接将事务性数据写入全局变量,则可以使用这些操作。
事务命令是TSTART,它定义事务的开始;
TCOMMIT,它提交当前事务;
和TROLLBACK,它将中止当前事务,并撤消自事务开始以来对全局变量所做的任何更改。
例如,下面的ObjectScript代码定义了事务的开始,设置了一些全局变量节点,然后根据ok的值提交或回滚事务:
/// w ##class(PHA.TEST.Global).GlobalTro(0)
ClassMethod GlobalTro(ok)
{
TSTART
Set ^Data(1) = "Apple1"
Set ^Data(2) = "Berry1"
If (ok) {
TCOMMIT
}
Else {
TROLLBACK
}
zw ^Data
q ""
}
TSTART在InterSystems IRIS日志文件中写入事务开始标记。
这定义了事务的起始边界。
在上面的示例中,如果变量ok为true(非零),则TCOMMIT命令标记事务成功结束,并将事务完成标记写入日志文件。
InterSystems中国正在招聘SE,具体职位需求以英文发布,详情如下,欢迎将简历砸过来 (claire.zheng@intersystems.com)or 私信联系 :)
亲爱的社区开发者们,大家好!
欢迎积极参与新一轮InterSystems开发者竞赛!
🏆 InterSystems 编程大赛:FHIR 加速器 🏆
提交在AWS上使用InterSystems的IRIS FHIR-as-a-service的应用程序,或帮助使用InterSystems IRIS FHIR加速器开发的解决方案。点击这篇文章,了解如何在AWS上申请应用InterSystems IRIS FHIR 加速器服务 (FHIRaaS) 。
时间:2021年5月10日-6月6日
奖金总额: $8,750
👉 点击登录活动页面 👈



