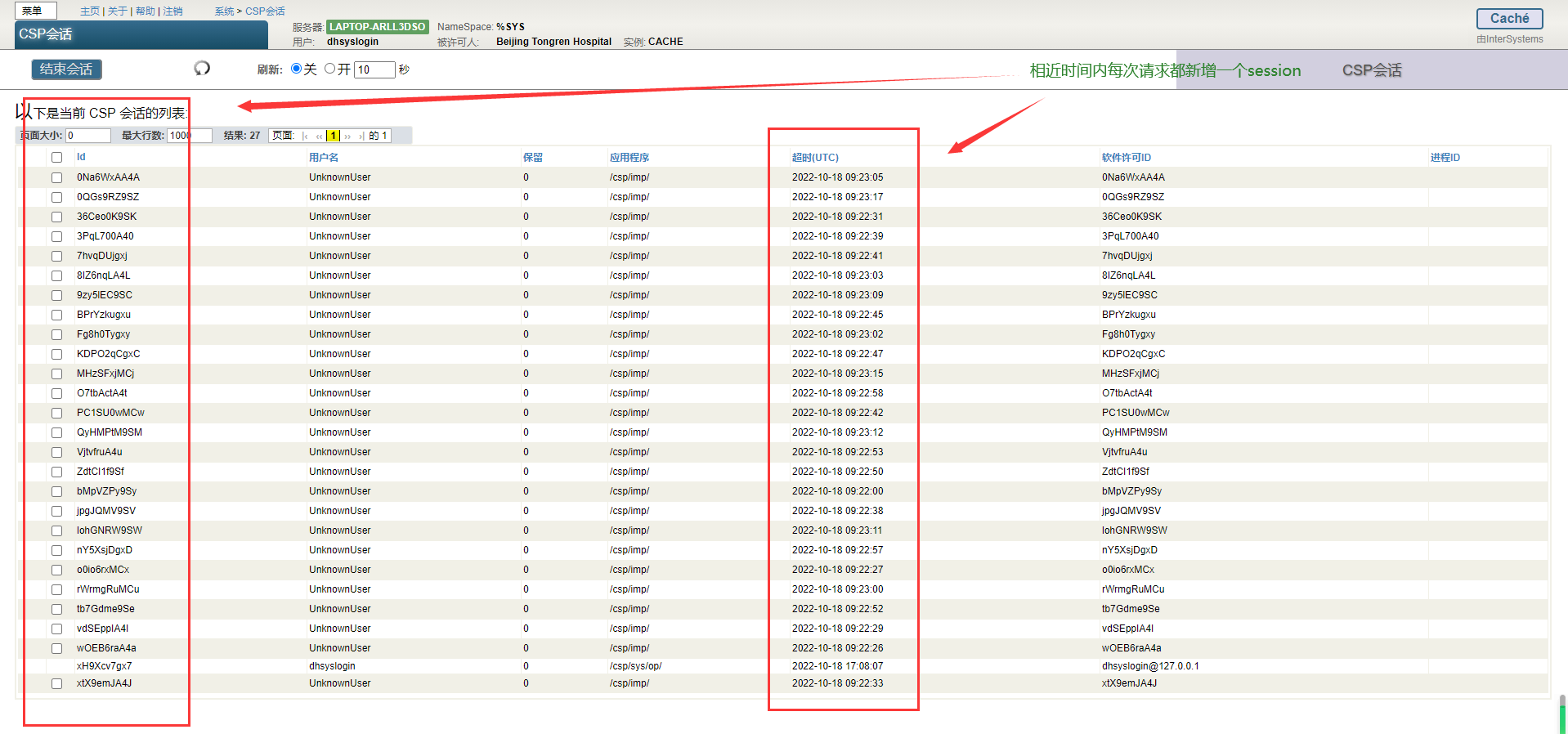
我们客户的一个共同需求是配置 HealthShare HealthConnect 和 IRIS的高可用性模式。
市场上的其他集成引擎通常被宣传为具有“高可用性”配置,但事实并非如此。通常,这些解决方案与外部数据库一起使用,因此,如果这些数据库未配置为高可用性,当发生数据库崩溃或与它的连接丢失时,整个集成工具将变得不可用。
对于 InterSystems 解决方案,这个问题不存在,因为数据库是工具本身的一部分和核心。 InterSystems 如何解决高可用性问题?深奥的配置会把我们拖入异化和疯狂的漩涡?不!在 InterSystems,我们倾听并处理了您的投诉(正如我们一直努力做的那样 ;)),并且我们已将镜像功能提供给所有用户和开发人员。
镜像
镜像如何工作?这个概念本身非常简单。如您所知,IRIS 和 HealthShare 都使用一个日志系统,该系统记录每个实例的数据库上的所有更新操作。这个日志系统是后来帮助我们在崩溃后恢复实例而不会丢失数据的系统。好吧,这些日志文件在镜像中配置的实例之间发送,允许并保持镜像中配置的实例永久更新。
架构
让我们简要解释一下在 Mirror 中配置的系统架构是什么样的:
.png)
 按查看数
按查看数.png)
 Open Exchange app
Open Exchange app
.png)