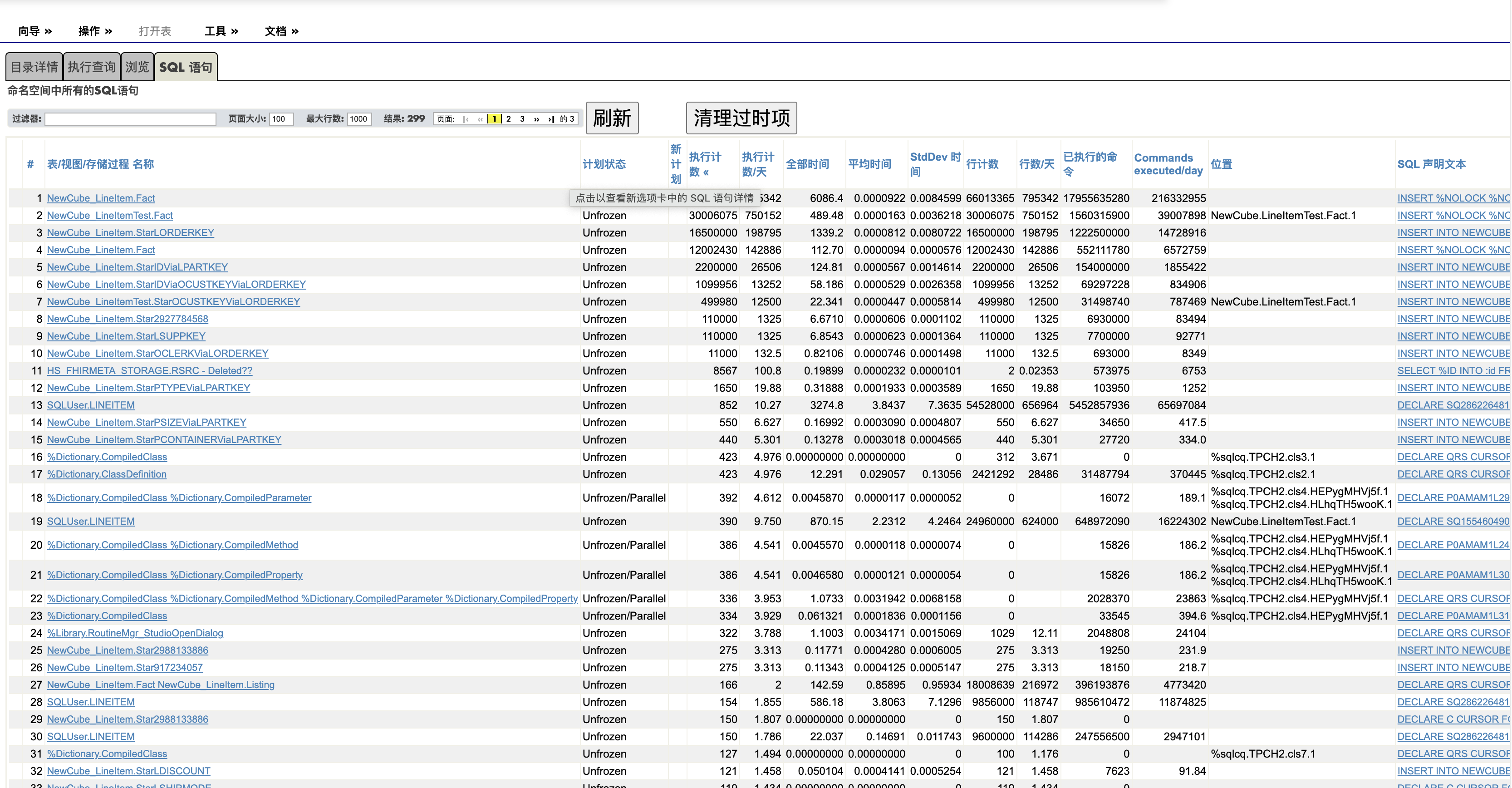
索引分析器工具用来分析索引的使用情况,对DBA和开发者非常有用。 他们需要知道那些查询进行了全表扫描,那些查询缺失了索引, 而那些索引从来又从来没有被用过。多余的索引降低系统性能,浪费了磁盘空间。
索引使用情况
到“管理门户”的" 系统 > SQL 性能工具 > SQL 索引分析器", 点击**“索引使用情况”**, 您将看到这样的图
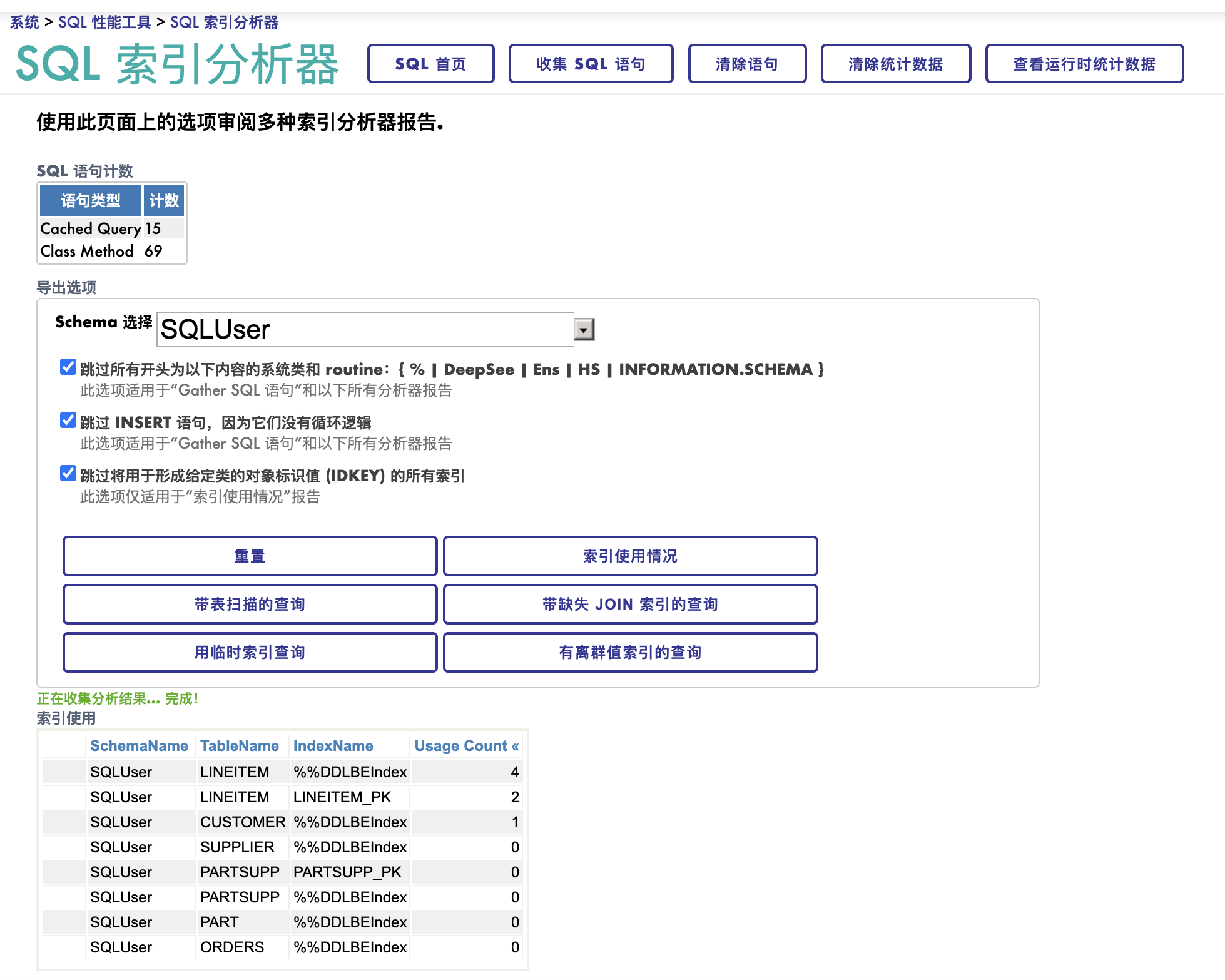
执行SQL语句查询会带来更多的灵活性。上面的查询可以写成下面这个SQL,
SELECT TableName, indexname, UsageCount
FROM %SYS_PTools.UtilSQLAnalysisDB order by usagecount desc
2016年以后的Caché版本就已经有了'索引使用情况'的查询。使用管理门户没有区别, 但SQL语句不同,使用的是比较老的类和表名,各位请参考文档。
注意上图中另外几个按钮,它们的介绍在文档的这个链接, 简单的做个翻译:
全表扫描的查询:
可识别当前命名空间中进行全表扫描的所有查询。应尽可能避免全表扫描。全表扫描并非总能避免,但如果某个表有大量全表扫描,则应检查为该表定义的索引。通常情况下,表扫描列表和临时索引列表会重叠;修复一个会移除另一个。结果集列出了从最大块计数到最小块计数的表。显示计划链接可显示语句文本和查询计划。

.png)
.png)
.png)
.jpg)