在本文中,我们将使用基于分布式存储的 Kubernetes 部署来构建一个 IRIS 的高可用配置,而不使用“传统的”IRIS Mirror。 这种部署将能够容忍与基础架构相关的故障,如节点、存储和可用区故障。 所描述的方法可以大大降低部署的复杂性,代价是 RTO的略微延长。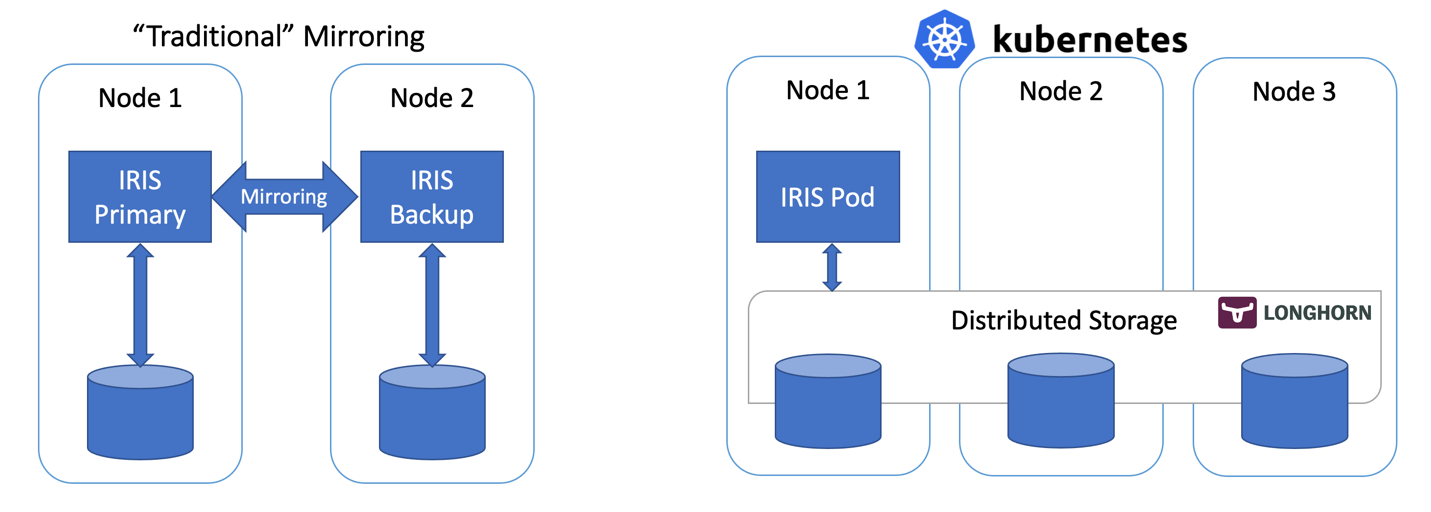

InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
.png)
.png)

.png)
.png)
.png)

.png)