InterSystems IRIS 数据平台是所有 InterSystems 应用程序以及医疗保健、金融服务、供应链和其他生态系统中数以千计的客户和合作伙伴应用程序的基础。它是一个融合平台,提供交易分析数据管理、集成互操作性和数据集成,以及集成分析和人工智能。它支持 InterSystems Smart Data Fabric 方法,用于管理多样化的分布式数据。
.png)

InterSystems IRIS 是一个完整的数据平台
InterSystems IRIS 为您提供了捕获、共享、理解组织最宝贵的资产(数据)并采取相应行动所需的一切。
作为一个完整的平台,InterSystems IRIS 不需要集成多种开发技术。应用程序需要更少的代码、更少的系统资源和更少的维护。
InterSystems IRIS 数据平台是所有 InterSystems 应用程序以及医疗保健、金融服务、供应链和其他生态系统中数以千计的客户和合作伙伴应用程序的基础。它是一个融合平台,提供交易分析数据管理、集成互操作性和数据集成,以及集成分析和人工智能。它支持 InterSystems Smart Data Fabric 方法,用于管理多样化的分布式数据。
IPM 0.10.5 版已于 2026 年 1 月 15 日发布。新版本包含大量改进和错误修复,请务必直接从GitHub 页面或社区注册中心查看!
主要变化如下
<Invoke> 将更直观地表现为始终检查 %Status 返回值,前提是且仅当方法签名声明返回 %Status。这意味着如果没有返回任何值、返回值不是 %Status 或不是 $$$OK,就会产生错误。以下是完整的变更列表:
已添加
- #938:为软件包命令添加了 -export-python-deps 标志
- #462:用于版本库配置的
repo命令现在支持使用-password-stdin标志的密码秘密输入终端模式。- #935:添加通用的 JFrog Artifactory tarball 资源处理器,用于将工件与软件包捆绑,并在安装时部署到最终位置。
InterSystems IRIS 提供广泛的可配置安全选项,但许多开发人员主要使用角色和资源来保护整个表或例程。今天,我们将深入探讨。我们也可以分别确保单个列和行的安全,但这两种机制的操作方式截然不同。让我们从列开始。
列安全
为便于测试和演示,我们将保持表结构简洁明了。我们在 USER 名称空间中有一个名为 "Person "的表,其中包含 ID 列、出生日期列 (DOB)、名和姓。
在上一篇文章中,我们谈到了 ODBC 和 C# 连接,现在让我们看看 JDBC 和 Java。InterSystems JDBC 驱动程序是集成 Java 应用程序的高性能推荐方式。
以下是使用 JDBC 驱动程序将 Java 应用程序连接到 IRIS 实例的分步指南。
JDBC 驱动程序与 ODBC 驱动程序不同,后者通常安装在整个系统中,而 JDBC 驱动程序通常以JAR 文件的形式发布,必须包含在 Java 项目的类路径中。
如果 InterSystems IRIS 安装在本地计算机或您可以访问的其他计算机上,您可以在 install-dir/dev/java/lib/ 或类似位置找到该文件,其中 install-dir 是实例的安装目录。反之,您也可以从驱动程序软件包页面下载 jar 文件。
或者按照 @Dmitry Maslennikov 在评论中的建议 ,使用 Maven 的maven 中央仓库:
<dependency>
<groupId>com.intersystems</groupId>
<artifactId>intersystems-jdbc</artifactId>
<version>3.10.5</version>
</dependency>或 Gradle:
implementation("com.intersystems:intersystems-jdbc:3.10.5")在项目中包含 jar 文件:
pom.xml 或 build.gradle 文件中。这会自动下载并管理 JAR。/lib)中,并在编译和运行时将其明确添加到 classpath 中。对于构建外部应用程序的开发人员,尤其是使用C# 等熟悉技术的开发人员来说,ODBC(开放数据库连接)是连接任何关系数据库(包括 InterSystems IRIS)的重要标准化桥梁。虽然 InterSystems 提供了自己的本地 ADO.NET 提供商,但 ODBC 驱动程序通常是与通用数据库工具和框架集成的最直接途径。
以下是使用 ODBC 驱动程序将 C# 应用程序连接到 IRIS 实例的分步指南,重点是无 DSN 连接字符串。
在 Windows 机器上安装 InterSystems IRIS 时,默认会安装 InterSystems ODBC 驱动程序。
安装完成后,可在 Windows 的ODBC 数据源管理员(ODBC Data Source Administrator)工具中验证其是否存在(查找 InterSystems IRIS ODBC35 驱动程序)。
.png)
Hi开发者们!
我们很高兴地宣布今年首次举办 InterSystems 在线编程竞赛:
比赛时间:2026年2月2日至3月1日(美国东部时间)
奖金:12,000 美元
.jpg)
不可避免的是,您最终需要将您的代码从一个版本的 IRIS 或 Cache 升级到最新版本的 IRIS。在这一过程中,您可以采取一些好的步骤来为自己的成功做好准备。
仔细阅读文档
在迁移任何代码之前,你应该先查看IRIS 文档页面,其中包含许多关于IRIS不同版本变更的有用资源。如果你需要跨多个版本升级,请查阅所有相关版本的文档,而不仅仅是目标升级版本。对于每个版本,点击“维护版本变更”(Maintenance Release Changes)链接,你将看到一份开发人员升级清单,对指导你需要进行的修改非常有帮助。你还应查看“发布说明”(Release Notes),其中列出了可能对你有用的新功能,以及已被弃用的功能。此外,建议访问“产品新闻与警报”(Product News and Alerts)页面,以获取最新的紧急事项。事实上,即使不进行升级,定期查看该页面或订阅警报通知也是个好主意,以便及时了解变更。
了解你的替代方案
根据你在文档中阅读到的内容,你可能会看到一堆问题。不过,在开始处理这些问题之前,您应该花些时间了解一下有哪些替代方案。如果您喜欢使用的特定 ObjectScript 类已被弃用或移除,那么如果您打算使用集成的 Python,就不要只寻找 ObjectScript 的替代品。如果您是 Zen 报表的用户,InterSystems Reports 就是该工具的替代品。
互操作性用户界面项目从 2025.1 版继续 进行,并纳入了许多我们的客户和合作伙伴建议和观察到的项目。 我们将继续投资于反馈和更新这一重要的用户体验。在最新发布的 2025.3 版(适用于 IRIS、 IRIS for Health、 HealthConnect 和 Health Connect Cloud) 中 , DTL 编辑器 和 生产配置 应用程序可选择
NOTE:
大家好,社区成员们:
对于刚接触InterSystems IRIS的开发者而言,这有个好消息!我们现已在Instruqt平台上推出了实操互动教程!这些教程非常适合希望快速上手、在真实环境中演练,并建立对基于IRIS的开发信心的开发者。(译者注:国内需要🪜)
.png)
概述
25.24.1 版对 DNS 功能、平台可靠性、升级工作流和开发人员体验进行了重大增强。该版本还包括关键修复和平台限制的增加,以更好地支持现代工作负载。
新功能和增强功能
|
类别 |
功能/改进 |
详细信息 |
| 网络 - DNS | DNS 映射(静态 DNS 支持) | DNS 支持从仅转发扩展到完整的 DNS 映射,允许创建和管理静态 DNS 条目,以提高服务发现和配置的灵活性。 |
| 可靠性和恢复能力 | 增强的自愈检查 | 改进了内部自愈验证例程,能够更快地恢复和更精确地检测运行异常。 |
| 高级安全性 | 改进的子网计算 | 增强了子网验证和计算逻辑,减少了配置错误,确保在不同部署中实现一致的网络分段。 |
| 升级和更新流程 | 改进 HCC 和 IRIS 托管服务 | 简化和强化了 Health Connect Cloud 和 IRIS 托管服务的升级/更新工作流,提高了可靠性和自动化准确性。 |
| DNS 修复 | DNS 别名错误修复 | 修复了 DNS 别名在特定配置中无法正确应用或传播的问题。 |
| 网络服务器 | 最大有效负载增至 200 MB | 允许的最大有效载荷大小从 10 MB 增加到 200 MB,支持更大的上传和更复杂的 API 交互。 |
| 开发人员工具 | InterSystems Data Studio 默认版本 1. |
概述
25.23.2 版对高级安全用户界面进行了有针对性的改进,并进一步简化了 InterSystems 云产品的升级和更新工作流程。这些更改重点关注清晰度、效率和卓越运营。
新功能和增强功能
| 类别 | 功能/改进 | 详细信息 |
|---|---|---|
| 高级安全性 | 增强应用程序可见性的用户界面 | 更新后的界面提供了更清晰、更直观的应用程序映射,提高了对安全边界、相关策略和受保护资源的理解。 |
| 升级和更新 | 优化的升级/更新流程 | 增强的升级/更新管道缩短了执行时间,最大限度地减少了维护窗口,提高了计划运行期间的整体系统可用性。 |
有关此版本的更多信息或帮助,请通过 iService 或云服务门户联系 InterSystems 云服务支持。
概述
本版本对存储的可扩展性和性能进行了重大改进,对所有产品的操作系统进行了重大升级,并推出了新的 FHIR 服务器默认版本。这些更新共同增强了系统的可靠性、灵活性和安全性,同时确保了平台的长期可支持性。
新功能和增强功能
|
类别 |
功能/改进 |
详细信息 |
| 存储 | 增强的 LVM 支持(条带或线性) | 增加了对 LVM 配置的支持,允许使用条带式或线性卷布局进行部署,以提高性能和灵活性。 |
| 选择使用 LVM 配置 | 客户现在可以在配置过程中选择使用基于 LVM 的存储,从而更好地控制卷管理和数据布局。 | |
| 扩大最大存储限制 | 每个部署支持的最大存储容量增至8 PB,可支持大规模数据工作负载和长期增长。 | |
| 操作系统 | Red Hat Enterprise Linux 9.6 升级 | 所有 InterSystems 云产品都从 RHEL 9.0 升级到了RHEL 9.6,提供了更好的内核性能、更强的安全性和更长的生命周期支持。 |
| FHIR 服务器 | 默认版本 2025.11.0 |
FHIR Server2025.11.0 现在是所有新部署的默认版本,在可扩展性、互操作性和数据管理方面都有改进。 有关详细信息,请参阅 FHIR Server 2025.11.0 发行说明。 |
概述
25.20.2 版扩展了全球可用性,提高了高级安全灵活性,并扩大了网络连接集成。该版本引入了对更多地区的支持、新的应用程序感知安全规则,以及针对关键 InterSystems 服务的更多连接选项。
新功能和增强功能
|
类别 |
功能/改进 |
详细信息 |
| 高级安全性 | 支持消息库规则 | 高级安全功能现在可以应用专门针对消息库的策略和规则,从而为消息存档和分析管道提供更精细的保护。 |
| 多应用规则支持 | 现在可以对规则进行配置,使其同时适用于多个应用,从而减少重复配置,简化策略管理。 | |
| 网络连接 | 支持 TGW 对等互联 | 现在支持中转网关 (TGW) 对等互联,实现了可扩展的多区域和多 VPC 连接,降低了复杂性并改进了流量控制。 |
| 支持 FHIR 服务器 | 针对 FHIR Server 的本机 Network Connect 集成,改进了路由管理、网络可见性和集成工作流。 | |
| 支持数据工作室(供应链模块) | 供应链模块增加了对 InterSystems Data Fabric Studio 的支持,实现了与客户网络拓扑的无缝集成。 |
.png)
InterSystems Ideas 门户网站上得票最多的想法-——获得 74 票——要求提供一个轻量级版本的 IRIS。虽然该平台已发展成为一个强大的数据引擎,但许多项目只需要其 SQL 数据库功能。本文演示了如何构建一个非官方的、紧凑的 IRIS 社区版镜像,该镜像只关注核心数据库功能,将镜像大小缩小了 80% 以上。
本项目生成的是 InterSystems IRIS Community Edition 的非官方实验镜像。
虽然 IRIS 目前包含丰富的互操作性、分析、机器学习、系统管理等功能,但许多项目只需要其核心 SQL 功能。官方社区版 Docker 镜像约为
IRIS Light 可将其减少到
因此适用于
使用 %Library.Global 类的 Export() 方法导出时,如果导出格式(第四个参数:OutputFormat)设置为 7,即 "块格式(Block format)/Caché 块格式 (%GOF)",则无法导出映射的Global项(只能导出命名空间默认Global数据库中的Global项)。要导出 "块格式/Caché 块格式 (%GOF) "的映射Global项,请在 %Library.Global.Export() 的第一个参数中指定要映射Global项的数据库目录。
执行示例如下。
如果将导出格式指定为 5(默认),即 "ISM/ObjectScript 格式(ISM/缓存格式)(*)",则也可以导出映射Global,但输出文件会比将导出格式(第四个参数:OutputFormat)设置为 7(即 "块格式/Caché 块格式(%GOF)")时大。
此外,如果在Global中记录了二进制数据,也无法正确输出。
更多信息,请参阅以下文档。
当我开始使用 InterSystems IRIS,尤其是在互操作性方面时,我最初遇到的一个常见问题是:如何在间隔时间或计划内运行某项功能?在本专题中,我想分享两个简单的类来解决这个问题。我很惊讶在 EnsLib 的某个地方没有找到类似的类。也许是我搜索得不好?总之,这个主题并不意味着是复杂的工作,只是为初学者提供了几个片段。
什么是 JWT?
JWT (JSON Web Token,JSON 网络令牌)是一种开放标准(RFC 7519),它提供了一种轻量级、紧凑、自足的方法,用于在双方之间安全地传输信息。它常用于网络应用程序中的身份验证、授权和信息交换。
JWT 通常由三部分组成:
1.JOSE(JSON Object Signing and Encryption,JSON 对象签名和加密)标头
2.有效载荷
3.签名
这些部分以 Base64Url 格式编码,并用点(.)分隔。
JWT 的结构
标题
{ "alg""HS256"有效载荷
{"1234567890"签名:
签名用于验证 JWT 的发件人是否为其本人,并确保信息未被篡改。
创建签名
1. base64 编码报头和有效载荷。
2.使用秘钥(对于对称算法,如 HMAC)或私钥(对于非对称算法,如 RSA)应用签名算法(如 HMAC SHA256 或 RSA)。
3.对结果进行 Base64Url 编码,以获得签名。
JWT 样本。查看JWT 内容
InterSystems 在《ISG/Ventana 买家指南》(ISG/Ventana Buyers Guide)中综合排名第二——领先于微软、亚马逊云服务(AWS)、谷歌和IBM。
什么是 XML?
XML(可扩展标记语言)是一种灵活的、基于文本的、独立于平台的格式,用于以结构合理 、人机可读的方式存储和传输数据 。XML 允许用户定义自定义标签来描述数据的含义和组织结构。例如:<book><title>The Hitchhiker's Guide</title></book>.
XML 文档具有自描述性,其结构是一棵分层的元素树。每个文档都有一个封装所有其他内容的根元素。元素可以包含文本、子元素和属性(提供补充信息的名-值对)。这些文档通常用 .xml 文件存储
这种结构的完整性可以通过以下方式实现:
这部分内容介绍如下:
在这些实施过程中,两种格式都会首先转换为 InterSystems IRIS SDA(标准化数据架构)格式。这被认为是一种标准、高效、不易出错的方法,因为它有效地利用了平台的 预置类。数据采用 SDA 格式后,可无缝转换为任何目标标准,如 HL7 v2、 FHIR 或 CCDA。
大家好!
我很高兴地宣布,自今年年初以来,我们已将 InterSystems IRIS、InterSystems IRIS for Health 和 Health Connect 的许多客户端 SDK 发布到相应的外部存储库(Maven、NuGet、npm 和 PyPI)中。这将为您带来许多好处,例如:
以下是我们目前已发布的客户端 SDK 的列表,以及最新版本的相应版本号和查找位置:
Java
我们非常高兴地宣布, IntegratedML Custom Models(集成式机器学习自定义模型)抢先体验计划即将开启,这是 IRIS 2026.1 版本中即将推出的一项强大新功能!
IntegratedML Custom Model扩展了现有的IntegratedML/AutoML(集成式机器学习/自动化机器学习)功能,支持您直接在 SQL 查询中部署自己的自定义 Python 机器学习模型。IntegratedML AutoML功能提供自动化机器学习服务,而Custom Model(自定义模型)则赋予您完全的控制权——自定义预处理、任意与 scikit-learn 兼容的模型,以及 Prophet 或 LightGBM 等第三方库——所有操作均在数据库内执行,无需数据移动。
您检查了服务器,发现IRISTEMP 增长过快。不必惊慌。让我们在存储空间耗尽之前调查一下这个问题。
在假设 IRISTEMP 是问题所在之前,让我们先检查一下它的实际大小。
在IRIS 终端运行以下命令:
%SYS>do ^%FREECNT出现提示时,输入
Database directory to show free space for (*=All)? /<your_iris_directory>/mgr/iristemp/如果输出结果显示可用空间非常小,则IRISTEMP 正在像拥挤的壁橱一样占满您的存储空间。但是,如果可用空间没有问题,但 IRISTEMP 数据库文件 (IRIS.DAT) 仍然很大(这可能就是你来这里的原因),这意味着临时数据已经被清理。在这种情况下,你的任务就是密切关注,按照下面的步骤在下一次行动中抓住它,并恢复宝贵的空间。
Directory name: /<your_iris_dir>/mgr/iristemp/
All Globals? No => yes
33 items selected from
33 available globals
1) Get exact packing details
2) Get block counts only
3) Use fast stochastic estimate
Please select an option: 3 => 3回顾上一季度,报告中着重强调了几项对本季度报告仍具现实意义的重要进展。
对于初次接触这些资讯的人而言,本次更新将基于当前信息,详细介绍近期所做的改进以及预期的变更;不过,未来预测仍存在不确定性,因此内容不应被解读为确定性的产品路线图。
2024 年,InterSystems 为所有基于英特尔和 AMD 的服务器引入了最低支持的 CPU 架构,使我们能够利用新的 CPU 指令创建速度更快的 IRIS 版本。IRIS 2025.3将更新该列表,要求采用 x86-64-v3 微架构级别,这需要 AVX、AVX2、BMI 和 BMI2 指令。
您是否想知道您的 CPU 是否仍受支持?
InterSystems IRIS® 数据平台、InterSystems IRIS® data platform, InterSystems IRIS® for HealthTM和HealthShare® Health Connect 2025.3 版本现已全面发布 (GA)。这是一个持续交付 (CD) 版本。
版本亮点:
请通过开发者社区分享您的反馈意见,以便我们共同打造更好的产品。
文档
有关所有重点功能的详细信息,请访问以下链接:
现代数据架构利用实时数据捕获、转换、移动和加载解决方案来构建数据湖、分析仓库和大数据存储库。它能够分析来自不同来源的数据,而不会影响使用这些数据的操作。要实现这一目标,必须建立连续、可扩展、弹性和稳健的数据流。最常用的方法是 CDC(变更数据捕获)技术。CDC 监控小型数据集的生产,自动捕获这些数据,并将其传送到一个或多个接收方,包括分析数据存储库。这样做的主要好处是消除了分析中的 D+1 延迟,因为数据一产生就会在源端被检测到,随后被复制到目的地。
本文将展示 CDC 场景中最常见的两种数据源,既可以是源数据源,也可以是目的地数据源。对于数据源(origin),我们将探讨 SQL 数据库和 CSV 文件中的 CDC。对于数据目的地,我们将使用列式数据库(典型的高性能分析数据库场景)和 Kafka 主题(将数据流传输到云和/或多个实时数据消费者的标准方法)。
本文将为以下互操作场景提供一个示例:

InterSystems IRIS中的窗口函数(Window Functions)可让您直接在SQL中执行强大的分析操作,例如累计总和、排名和移动平均值等。
这些函数针对与当前行相关的一组行(即“窗口”)进行操作,且不会像 GROUP BY那样合并结果。
这意味着您可以编写更简洁、更快速且更易于维护的查询——无需循环、无需连接、无需临时表。
在本文中,我们将通过处理一些常见的数据分析任务来了解窗口函数的作用机制。
SQL窗口函数(SQL window functions)是数据分析的强大工具。 它们允许你在保留各行列可见性的同时,跨行计算聚合值和排名。 无论你是在构建仪表盘、报表还是进行复杂分析,窗口函数都能简化你的逻辑并提升性能。
注:我并非窗口函数领域的专家,但我愿意分享助我理解窗口函数的心得体会和相关资源。非常欢迎大家提出建议或进行指正!
你是否曾为了计算累计总和、排名或行间差值,而编写过多条SQL查询语句,甚至使用过程化循环?
窗口函数能让你仅通过一条SQL查询语句就实现所有这些操作。
它们将强大的分析功能直接融入SQL——无需额外连接操作、无需临时表,也无需过程化循环。
窗口函数会针对一组与当前行存在某种关联的行进行计算——这组行被称为窗口(window)。
本文第一部分提供了所有背景信息。其中还包括DATATYPE_SAMPLE数据库的链接,您可以使用该链接来跟进示例。
在该部分中,我们探讨了一种易于检测的错误类型(""Access Failure【访问失败】") ,因为当尝试通过数据库驱动程序读取数据时,它会立即触发一条明确的错误消息。
本节讨论的错误更为隐蔽,也更难发现。我将它们称为"静默损坏(Silent Corruption)"和"未检测到的数据变异(Undetected Mutation)"。
让我们从"静默损坏(Silent Corruption)"开始:
在DATATYPE_SAMPLE数据库的 "雇员(Employee) "表中,有一条被故意篡改的记录可以证明这种行为--它就是ID = 110 的记录。 乍一看,甚至再看一眼,都看不出任何问题。无论是数据库驱动程序还是查询工具,都没有显示读取该记录有问题。
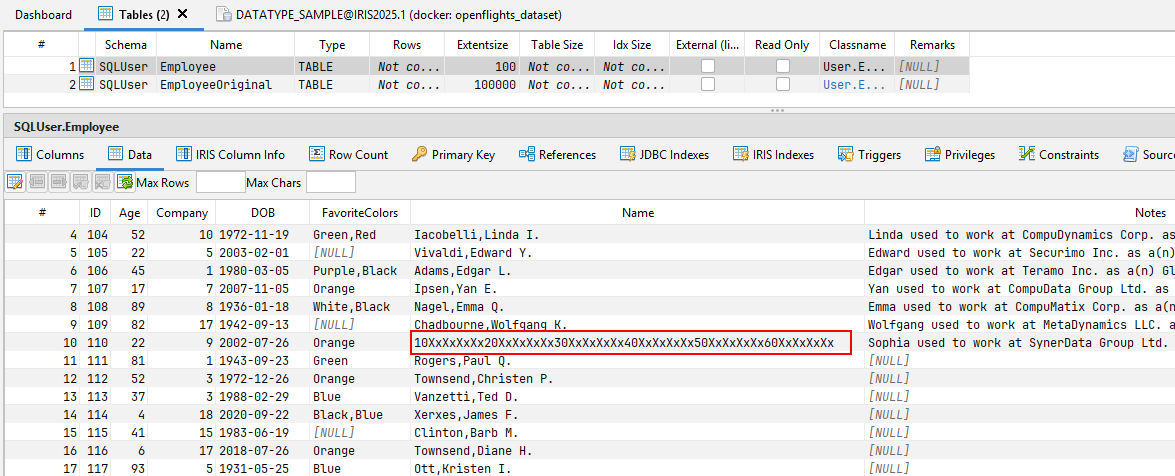
只有仔细观察才会发现,红色标记单元格中的值与传输(和定义)的元数据不符。
"名称(Name)"列被定义为VARCHAR(50),但实际值为60 个字符!
在某些情况下,这种行为不会造成任何问题——例如,当驱动程序宽松地处理这种不一致时。
但是,当下游系统依赖于所提供的元数据时,问题就会出现。如果根据这些元数据定义进行进一步处理,当实际内容与约定的接口不一致时,就可能出现错误。
概述
该版本引入了FHIR Server 2025.10.0,该版本遵循最新标准并实现了性能提升。它还增强了Health Connect Cloud(HCC)升级流程,提高了其可靠性,并通过在 VPN 配置中支持前缀列表为Network Connect增加了新的灵活性。
新功能和增强功能
|
类别 |
功能/改进 |
详细信息 |
|
FHIR Server |
发布 FHIR 服务器 2025.10.0 |
推出 InterSystems FHIR Server 的最新版本,具有更高的可扩展性、更强的 FHIR R5 一致性以及对批量数据交换的优化。 |
| Health Connect Cloud |
升级流程改进 |
简化和强化了 HCC 部署的升级工作流程,缩短了维护窗口持续时间,提高了回滚安全性和自动化准确性。 |
| Network Connect |
静态 VPN 导入支持前缀列表 |
静态 VPN 导入任务现在支持 AWS 前缀列表,简化了路由管理,使客户环境中的网络配置更加动态和一致。 |
推荐操作
此版本无建议操作。
支持
如需帮助或了解有关这些更新的更多信息,请通过 iService 或 InterSystems 云服务门户(InterSystems Cloud Service Portal)提交支持请求。
InterSystems IRIS Adaptive Analytics(自适应分析)2025.4.1 版本现已通过InterSystems 软件分发页面发布。 该版本集成 AtScale 2025.4.1,并兼容现有自适应分析用户自定义聚合函数(User-Defined Aggregate Function,UDAF)文件(2024.1 版本)。
AtSCale 2025 版本包含的新功能包括:
如需了解 AtScale 2025.4.1 的更多详细信息,请参阅版本发布说明。
如需了解 Adaptive Analytics 的更多信息,请参阅 InterSystems 官方文档和 Learning Service 中的内容。
在使用标准 SQL 或 InterSystems IRIS 中的对象层时,元数据的一致性通常通过内置验证和类型执行来保持。但是,绕过这些层直接访问global的传统系统会带来微妙而严重的不一致性。
了解驱动程序在这些边缘情况下的行为,对于诊断遗留数据问题和确保应用可靠性至关重要。DATATYPE_SAMPLE数据库旨在帮助分析列值不符合元数据中定义的数据类型或约束的错误情形。我们的目标是评估 InterSystems IRIS 及其驱动程序(JDBC、ODBC、.NET)和不同工具在发生此类不一致时的表现。 在本篇文章中,我将重点介绍JDBC 驱动程序。
一些传统应用程序会直接写入globals。如果使用关系模型(通过 CREATE TABLE 创建或使用全局映射手动定义)来公开这些数据,那么映射定义 的底层值就会与每列的声明元数据一致。
当这一假设被打破时,可能会出现不同类型的问题: