
 按查看数
按查看数.jpg)
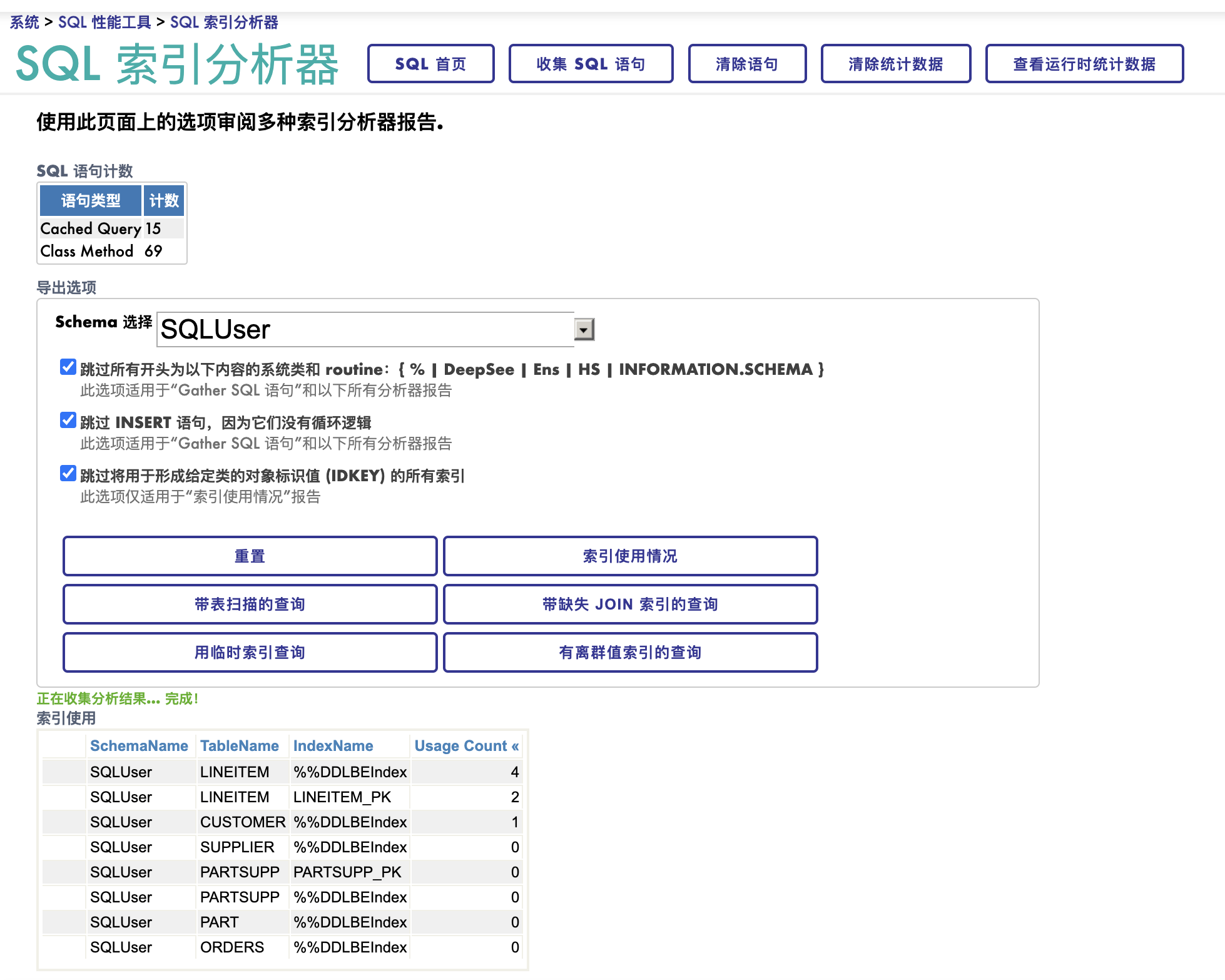
上个帖子写了TuneTable的执行, 提到了SQL优化器使用的那些统计数据, 这里逐一的介绍一下这些统计项。了解它们看懂和分析SQL执行计划的基础。 如果您不需要做单个查询的优化工作,可以调过这部分内容。
表的统计项
- Extent Size: 表的大小,也就是记录数。在执行多表关联(JOIN)的查询时,SQL优化器会根据Extent Size值,从数据量最小的表来开始执行查询。
您还需要了解:表创建的时候Extent Size会获得一个初始值,而之后的插入修改数据并不自动修改这个值。而只有执行TuneTable才会修改这个。 这也就是为什么没有执行过TuneTable的数据库SQL性能好不了的原因。下图中的Patient表,可以看出有1,000,000记录
 Open Exchange app
Open Exchange app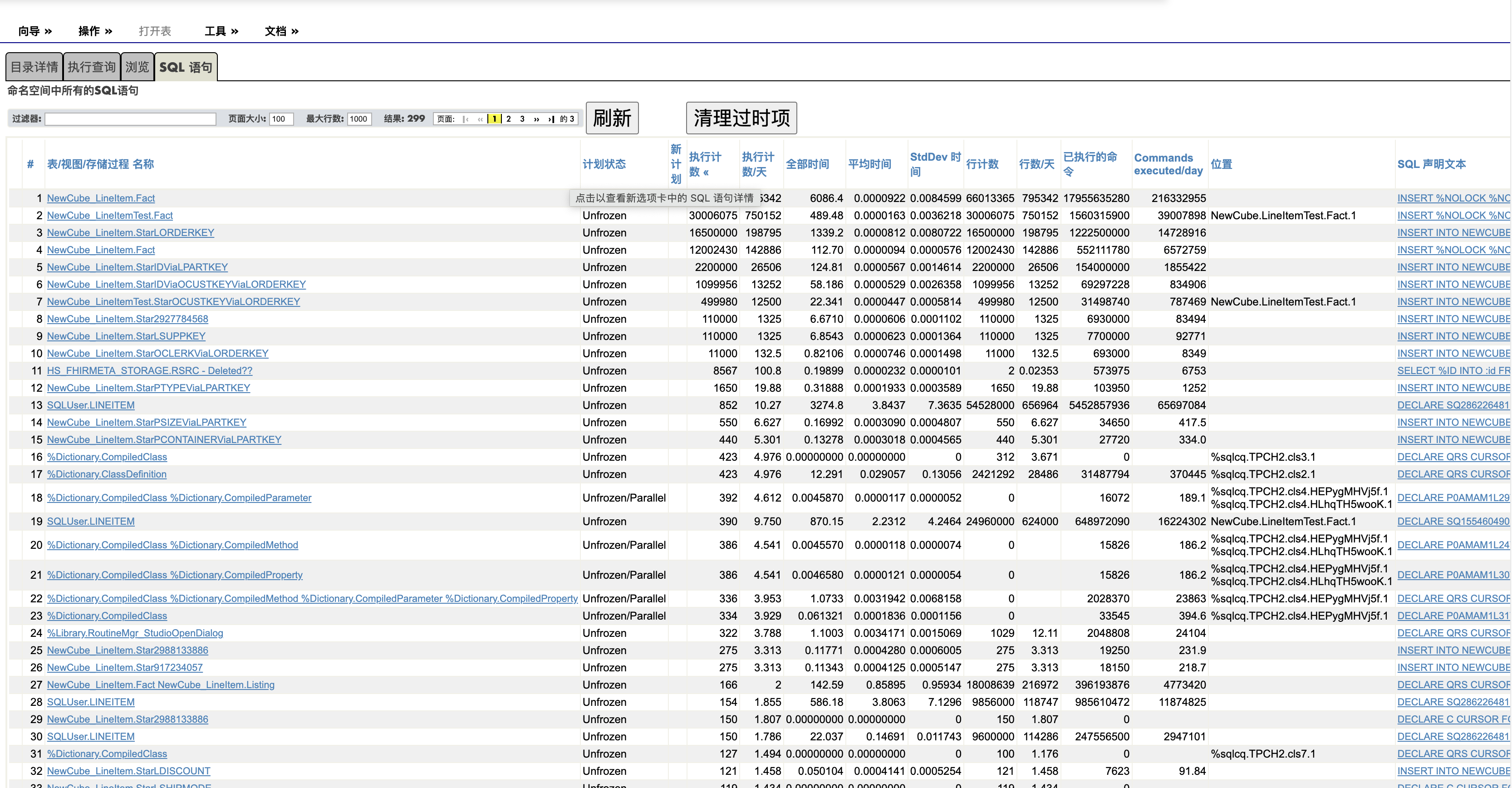
.png)