我现在在使用object script。如果把代码从 objectscript转成 Java 我需要做些什么?
你好。
我想访问一个远程SQL Server数据库中的存储过程。我对Object Script很陌生。
该存储过程有3个参数:2个日期时间参数和1个整数。
哪种方法最好呢?我想知道我是否可以在object script中使用链接存储过程的功能或一些SQL语句。
这个存储过程返回一组行,我想读取、转换并保存在一个持久化类中。
先谢谢了。
Hi,
I want to access a Stored Procedure in a remote SQL Server Database. I am quite new to Object script.
The stored procedure has 3 parameters: 2 datetime parameters and 1 integer.
Which is the best way to do that? I'm wondering if I can use the link stored procedure feature inside object script or some SQL statement in Object Script.
This SP returns a set of rows which I want to read, transform and save in a persistent class.
亲爱的女士们和先生们,在上个月,我改进了我的工具Caché监视器......但首先:名字
选择Caché Monitor这个名字是为了反映该工具与Caché数据库的紧密结合。我想,在可预见的未来,Intersystems Caché这个既定名称很可能会被InterSystems IRIS数据平台完全取代。因此,重塑品牌的步骤成为必要。为了在未来不那么紧密地与一个产品名称联系在一起,我们选择了一个更加中立的新名字: SQL Data Lens
不管叫什么名字,实现与Intersystems产品最紧密的整合仍然是我们的目标。持续的发展也反映在版本号的延续上。上一个版本是Caché Monitor 2.96,下一个版本是SQL Data Lens 3.0。
但这不仅仅是重新命名,而且还集成了许多新的功能,例如
- 一个很大的进步是,SQL Data Lens现在是基于Java Runtime Environment 11的,有了它,就可以改善对HiDPI的支持。在操作系统层面上配置了系统规模因素,支持每台显示器的DPI!
- 但也集成了一个新的现代的Flat 外观和Feel 集成,在亮Light和暗Dark两种模式下。
第二十一章 使用工作队列管理器(四)
分离和附加工作队列
通常,初始化一组工作程序,将工作项排队,然后等待工作程序完成工作项。但是,可能会遇到工作人员作业完成工作项所需的时间比预期更长的情况,或者无法将单个进程专门用于等待。因此,工作队列管理器使能够将工作队列与进程分离,然后将工作队列附加到同一进程或不同的进程。
例如,假设队列引用了初始化的工作队列。还假设向工作队列中添加了几个工作项。在调用 Wait() 或 WaitForComplete() 来确定正在处理的工作的状态之前,可以使用以下方法:
Detach()
method Detach(ByRef token As %String, timeout As %Integer=86400) as Status 从初始化工作队列时创建的对象引用中分离工作队列对象。 Detach() 方法使任何正在进行的工作能够继续并保留工作队列的当前状态。
token 参数表示一个安全令牌,可以使用它随后将工作队列附加到另一个进程。 timeout 参数是可选的,它指示系统保留分离的工作队列对象的时间量(以秒为单位)。超时期限过后,系统会删除与工作队列关联的所有工作人员作业和信息。超时的默认值为 1 天。
调用 Detach() 方法后,对分离对象引用的大多数调用都会返回错误。
如题:
.png)
第二十章 使用工作队列管理器(三)
管理类别
一个类别是一个独立的worker jobs池。当初始化一组worker jobs时,可以指定提供worker的类别。如果集合中的任何worker jobs在执行work项时请求额外的worker jobs,则新的worker jobs来自同一类别。
例如,假设系统提供的 SQL 类别分配了最多 8 个worker。然后,假设与BusinessIntelligence相关的流程创建了一个类别,并将最多四个worker分配给该类别。如果 SQL 池中的所有worker在给定时间都参与了工作,则 BusinessIntelligence 类别中的worker可能仍然可以立即处理工作项。
系统包括两个不能删除的类别:SQL 和 Default。 SQL 类别适用于系统执行的任何 SQL 处理,包括查询的并行处理。当在未指定类别的情况下初始化一组worker jobs时,默认类别提worker jobs。
每个类别都具有影响该类别中每个工作队列的行为的属性。这些属性是:
DefaultWorkers
当创建此类别中的工作队列且未指定worker job 计数时,这将成为工作队列中worker job 的数量。此属性的默认值是核心数。
MaxActiveWorkers
在此类别的job服务请求池中保留的活动worker job的最大数量。
第十九章 使用工作队列管理器(二)
基本工作流程
可以通过执行以下步骤来使用工作队列管理器:
- 将
ObjectScript代码划分为工作单元,这些工作单元是满足特定要求的类方法或子例程。 - 创建一个工作队列,它是
%SYSTEM.WorkMgr类的一个实例。为此,请调用%SYSTEM.WorkMgr类的%New()方法。该方法返回一个工作队列。
可以指定要使用的并行worker jobs的数量,也可以使用默认值,这取决于机器和操作系统。此外,如果已创建类别,则可以指定应从中获取job的类别。
创建工作队列时,工作队列管理器会创建以下工件:
- 包含有关工作队列的信息的全局变量,例如工作队列在哪个命名空间中运行
- 工作队列必须处理的序列化工作单元的位置和事件队列
- 在工作队列完成处理工作单元时创建的完成事件的位置和事件队列
- 将工作单元(也称为工作项)添加到工作队列。为此,可以调用
Queue()或QueueCallback()方法。作为参数,传递类方法(或子例程)的名称和任何相应的参数。
对添加到队列的项目立即开始处理。
如果队列中的项目多于队列可用的worker jobs,则job会竞争清空队列。例如,如果有 100 个项目和四个job,则每个job从队列的头部移除一个项目,处理它,然后返回到队列的头部以移除并处理另一个项目。这种模式一直持续到队列为空。
大家好!
一周前,在西雅图举办的InterSystems 2022年全球峰会刚刚结束,但对于那些错过会议现场的人,或者由于种种原因无法亲自参加会议的人(或者只是希望重新回忆并再次聆听会议的人)来说,线上主题演讲刚刚开始!
话不多说,请查收全球峰会上来自社区的问候:
欢迎通过YouTube播放列表观看2022年全球峰会三天所有主题演讲:
第十八章 使用工作队列管理器(一)
工作队列管理器是的一项功能,使能够通过以编程方式将工作分配给多个并发进程来提高性能。在引入工作队列管理器之前,可能已经使用 JOB 命令在应用程序中启动多个进程并使用自定义代码管理这些进程(以及任何导致的故障)。工作队列管理器提供了一个高效且直接的 API,使能够卸载流程管理。
代码在多个地方内部使用工作队列管理器。可以将它用于自己的需求,如以下部分中的高级描述。
背景
计算机硬件开发的最新创新趋向于高性能、多处理器或多核架构。与此同时,内存和网络设备的速度也只是慢慢地提高了。 开发了工作队列管理器以响应这些趋势并根据以下原则:
- 硬件资源,包括 CPU 和 I/O、内存和网络设备,都是固定的。
- 必须尽可能高效地使用硬件资源,以最大限度地提高其执行业务任务的速度。
- 为了实现最大效率,工作队列管理器必须改善在执行ObjectScript 代码时可能出现的 CPU 利用率不足的问题。
- 解决 CPU 利用率不足的方法包括排队和优先级划分。
尽管整个数据平台旨在尽可能高效地利用系统中的硬件资源,但该平台的工作队列管理器功能专门设计用于利用现代硬件配置中可用的额外 CPU 资源。工作队列管理器有两个关键用途:
- 提供一个框架,使能够将大型编程任务分解成更小的块,以便在多个并发进程中执行。通过一次使用多个 CPU,工作队列管理器显着减少了处理大型工作负载所需的时间。
高可用性(HA)指的是使系统或应用程序在很高比例的时间内保持运行,最大限度地减少计划内和计划外的停机时间。
维持系统高可用性的主要机制被称为故障转移。在这种方法下,一个故障的主系统被一个备份系统所取代;也就是说,生产系统故障转移到备份系统上。许多HA配置还提供了灾难恢复(DR)的机制,即在HA机制无法保持系统的可用性时,也能及时恢复系统的可用性。
本文简要讨论了可用于基于InterSystems IRIS的应用程序的HA策略机制,提供了HA解决方案的功能比较,并讨论了使用分布式缓存的故障转移策略。
操作系统级别的集群HA
在操作系统层面上提供的一个常见的HA解决方案是故障转移集群,其中主要的生产系统由一个(通常是相同的)备用系统补充,共享存储和一个跟随活动成员的集群IP地址。在生产系统发生故障的情况下,备用系统承担生产工作量,接管以前在故障主系统上运行的程序和服务。备用机必须能够处理正常的生产工作负载,只要恢复故障主机所需的时间就可以了。也可以选择让备用机成为主机,一旦主机恢复,故障主机将成为备用机。
InterSystems IRIS的设计可以轻松地与所支持的平台的故障转移集群技术相结合(如InterSystems支持的平台中所述)。
Hi 亲爱的开发者们,你是否精通多门语言并希望与世界各地的非英语用户分享你的知识?
我们为你提供了闪光的机会! 🤩
第十七章 进程内存
介绍
进程使用许多不同的资源来实现其目标。其中包括部分或全部 CPU 周期、内存、外部存储、网络带宽等。这篇文章是关于内存使用的。具体来说,它处理为数据存储分配的内存,例如:
- 公共和私有变量
当第一次为它们分配值时,它们被分配了内存空间。在局部数组的情况下,局部变量名称加上所有下标的值的组合引用单个变量值。
除了包含极长字符串的变量外,变量会占用与 $STORAGE 相关的空间。包含极长字符串的变量以不同方式存储,并且不占用 $STORAGE 中的空间。
- 对象实例
每当实例化一个对象时,都会分配空间来保存对象的当前内容以及它所引用的对象。删除最后一个对象引用时返回该空间。
- 本地
I/O缓冲区
将与该进程正在使用的设备相关联的 I/O 缓冲区存储在进程空间中。
管理进程空间
进程从用于上述实体的初始内存池开始。当应用程序创建它们时,它们会消耗池中的内存;当应用程序删除它们时,它们的内存将返回到池中。例如,当一个例程开始执行时,总是会创建消耗一些内存的局部变量;当例程返回并且这些变量超出范围时,这些变量使用的内存将被返回并可供重用。
当应用程序需要内存,并且进程在其内存池中没有足够大(连续)的可用内存区域来满足需求时,该进程会从底层操作系统请求额外的内存块以添加到其池中。稍后,如果该内存块完全未使用,它将返回给操作系统。
第十六章 字符串本地化和消息字典(二)
XML 消息文件
XML 消息文件是消息字典的导出。这也是希望导入的任何消息的必需格式。
只要有可能,XML 消息文件应该使用 UTF-8 编码。但是,在某些情况下,开发人员或翻译人员可能会使用本地平台编码,例如 shift-jis,以便于编辑 XML 消息文件。无论 XML 文件使用何种编码,应用程序的语言环境都必须支持它,并且它必须能够表达该语言的消息。
XML 消息文件可能包含一种语言和多个域的消息。
Element
Language。 Language 属性的值是一个全小写的 RFC1766 代码,用于标识文件的语言。它由一个或多个部分组成:主要语言标签(例如 en 或 ja)可选地后跟连字符 (-) 和次要语言标签(en-gb 或 ja-jp)。
在以下示例中,此语言为“en”(英语)。
<?xml version="1.0" encoding="utf-8" ?Hi 社区,
在这篇文章中,我将解释如何通过使用嵌入式python访问管理门户系统的仪表盘信息和表数据。.png)

第十五章 字符串本地化和消息字典(一)
本文概述了字符串本地化,并描述了如何导出、导入和管理消息字典。
字符串本地化
当本地化应用程序的文本时,会创建一种语言的文本字符串清单,然后当应用程序区域设置不同时,建立约定以另一种语言替换这些消息的翻译版本。
支持以下本地化字符串的过程:
- 开发人员在他们的代码中包含可本地化的字符串(在
REST应用程序或商业智能模型中)。
这种机制各不相同,但最常见的机制是 $$$Text 宏。代替硬编码的文字字符串,开发人员包含 $$$Text 宏的实例,为宏参数提供如下值:
- 默认字符串
- 此字符串所属的域(将字符串分组为域时,本地化更易于管理)
- 默认字符串的语言代码
write "Hello world"
替换为
write $$$TEXT("Hello world","sampledomain","en-us")
- 编译代码时,编译器会在消息字典中为
$$$Text宏的每个唯一实例生成条目。
消息字典是全局的,因此可以在管理门户中轻松查看(例如)。有一些类方法可以帮助完成常见任务。
- 开发完成后,发布工程师导出该域或所有域的消息字典。
结果是一个或多个 XML 消息文件,其中包含原始语言的文本字符串。
-
发布工程师将这些文件发送给翻译人员,请求翻译版本。
-
翻译人员使用他们喜欢的任何
XML创作工具来处理XML消息文件。
各位领导、老师大家好。非常荣幸有机会参加这次由中国数字医学杂志社组织的陕西省医院数字化转型研讨会。
IT这个行业很有意思,就是大家都很喜欢造词。这几年有一个词特别火,叫做数智化底座,很多厂商都先后推出了自己的数智化底座解决方案。结合最近对整个行业的一些观察,今天借这个机会,跟各位领导和老师探讨一下,医疗行业的数字化有什么特点,到底什么样的底座或者平台比较符合我们医疗行业,以及我们在建设数智化底座的时候需要考虑哪些问题。结合我们最近的一些观察和思考,有不当之处,欢迎各位老师批评、指正。
首先一点就是我们做任何工作,首先要解决“为什么”的问题?第一个核心思路,我想数字化转型是为智慧医院服务的,归根结底,还是要通过数字化的手段,来实现医院的高质量发展。针对这一目标,国家卫健委制定了智慧医院发展的三大目标,就是智慧医疗、智慧管理和智慧服务,我想说白了,无非就是让医院、医护人员以及我们的患者过的更好,提高我们治疗和护理水平、降本增效,同时能够让我们的患者得到更好的服务。所有的数字化建设,不管是平台还是应用,都应该围绕这一核心目标。
.png)
第二个核心思路,我们认为软件要为人服务所谓的数字化转型,就是用软件来开展一切可以开展的业务,而软件是为人服务的,目的是提高我们的工作效率、认知水平和实现我们仅仅靠人力做不了的事情。
大家好!欢迎参加InterSystems第21届开发者大赛!
🏆 InterSystems 2022 Full Stack开发者大赛 🏆
时间: 2022年6月27日-7月17日(美东时间)
奖金:$10,000

%XML.XPATH.Document中CreateFromFile方法,
如:
第十四章 信号(四)- 多进程任务示例
可根据此思想进行多任务启动查询汇总数据。
原理
- 利用
job机制开启后台进程。 - 利用
loop循环减少进程的数量等于开启进程的数量,判断多进程任务是否完成。
-
创建表并插入
1000W条数据,统计Moeny字段总金额 -
创建
demo代码如下。
Class Demo.SemaphoreDemo Extends %RegisteredObject
{
/// Do ##class(Demo.SemaphoreDemo).Sample(5)
ClassMethod Sample(pJobCount = 3)
{
k ^yx("Amt"),^yxAmt
/* 1.启动信号 */
s mSem = ##class(Demo.Sem).%New()
If ('($isobject(mSem)))
{
q "启动失败"
}
/* 2. 初始化信号量为0 */
d mSem.Init(0)
s t1 = $zh
/* 3. 按指定数量,启动后台任务 */
for i = 1 : 1 : pJobCount
{
j .Cache数据库使用M语言如何调用第三方视图呢,有没有对应使用文档呢?
第十三章 信号(三)- 示例演示
运行示例
Main、Producer 和 Consumer 这三个类中的每一个都有自己的 Run 方法,最好在各自的终端窗口中运行它们。每次运行时,它都会显示它为日志生成的消息。一旦用户通过提供它正在等待的输入来响应 Main 类,Main 的 Run 方法将终止删除信号量。然后,用户可以通过键入命令查看所有进程的合并日志文件的显示
Do ##class(Semaphore.Util).ShowLog()
注意:以下所有示例都假定所有类都已在“USER”命名空间中编译。
示例 1 - 创建和删除信号量
最简单的例子演示了信号量的创建和销毁。它使用 Semaphore.Main 类。请执行下列操作:
- 打开一个终端窗口。
- 输入命令——
Do ##class(Semaphore.Main).Run()
- 该方法创建信号量。如果成功,将看到消息“输入任何字符以终止运行方法”。按下
Enter键。该方法显示信号量的初始化值,将其删除,然后退出。 - 通过发出命令显示日志文件
Do ##class(Semaphore.Util).ShowLog()
按照上述步骤在终端窗口中显示的消息示例如下
消息示例如下
DHC-APP>Do ##class(Semaphore.Main).第十二章 信号(二)- 生产者消费者示例
下面是一系列使用信号量实现生产者/消费者场景的类。 “主”进程初始化信号量并等待用户指示活动已全部完成。生产者在循环中随机增加一个信号量值,更新之间的延迟可变。消费者尝试在随机时间从信号量中删除随机数量,也是在循环中。该示例由 5 个类组成:
Main– 初始化环境并等待信号量上的活动完成的类。Counter– 实现信号量本身的类。它记录它的创建以及由于信号量在等待列表中而发生的任何回调。Producer– 一个类,其主要方法增加信号量值。增量是一个随机选择的小整数。完成增量后,该方法会在下一个增量之前延迟一小段随机数秒。Consumer消费者——这是对生产者的补充。此类的主要方法尝试将信号量减少一个随机选择的小整数。它将递减请求添加到其等待列表中,等待时间也是随机选择的秒数。- Util - 这个类有几个方法被示例的其他类使用。几种方法解决了为所有活动维护公共日志的问题;其他人解决了多个消费者和多个生产者的命名问题。
注意:组成这些类的代码特意写得简单。尽可能地,每个语句只完成一个动作。这应该使用户更容易和更直接地修改示例。
Class: Semaphore.Main
此类建立演示环境。它调用实用程序类来初始化日志和名称索引工具。
 Globals,这些存储数据的魔剑,已经存在了一段时间,但是没有多少人能够有效地使用它们,也没有多少人知道这个超级武器。
Globals,这些存储数据的魔剑,已经存在了一段时间,但是没有多少人能够有效地使用它们,也没有多少人知道这个超级武器。
如果你把Globals的东西用在它们真正能发挥作用的地方,其结果可能是惊人的,要么是性能的提高,要么是整体解决方案的大幅简化 (1, 2).
Globals提供了一种特殊的存储和处理数据的方式,它与SQL表完全不同。它们在1966年首次出现在 M(UMPS)编程语言中, 该语言最初用于医学数据库。现在它仍然以同样的方式被使用,但也被其他一些以可靠性和高性能为首要任务的行业所采用:金融、交易等。
后来M(UMPS)演变为 Caché ObjectScript (COS). COS是由InterSystems公司开发的,作为M的一个超集. 其原始语言仍然被开发者社区所接受,并在一些实现中保持活力。在网络上有几个活跃的网址,比如:MUMPS Google group, Mumps User's group), effective ISO Standard等等
现代基于Globals的数据库支持交易、日志、复制、分区等。这意味着它们可以被用来构建现代的、可靠的、快速的分布式系统。
Gloabls并不将你限制于关系模型的范围内。它们让你可以自由地创建为特定任务优化的数据结构。对于许多应用来说,合理地使用好的Globals就如一颗真正的银子弹头,它所提供的速度是传统关系型应用的开发者所梦寐以求的。
作为一种存储数据的方法,globals可以在许多现代编程语言中使用,包括高级和低级语言。因此,本文将特别关注Globals本身,而不是它们曾经来自的语言。
比较不同的商业智能技术是非常有趣的。我很好奇它们在功能、开发工具、速度和可用性方面有什么不同。
在这个应用程序中,我选择了一个有欧洲各国水状况的数据集。这是一个开源的数据集,包含1991年到2017年的观测数据。
团队和我决定使用IRIS BI、Tableau、PowerBI和InterSystems Reports(由Logi Reports驱动)在这个BI数据集的基础上制作一个模型
对于前端,我们通过Embedded Python在PythonFlask中制作了一个网页界面。
顺便说一下,其结果可以在这个网页上看到:http://atscale.teccod.com:8080/
你可以看看demo stand (演示台),因为从资源库部署一个容器可能需要多至20分钟的时间。大量的python包,后面会有更多的原因。
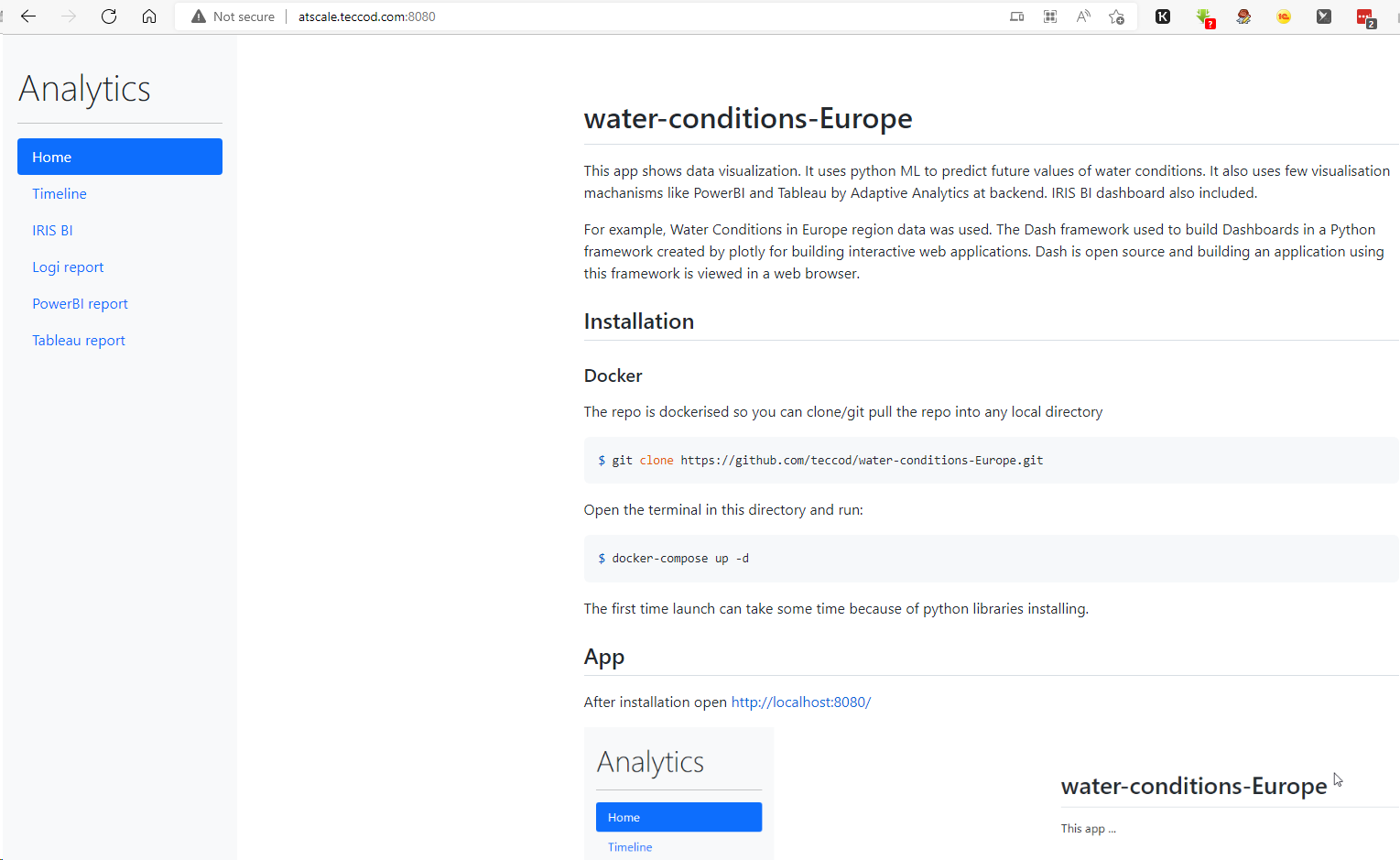
主页面
数据
事实上,数据似乎很小,期间只有17年 :)
因此,在现有的基础上,我想延续数据集,为此使用了一个神经网络。使用同样的嵌入式Python,使用了Tensorflow,这个包下载后占据了511MB,不要惊讶
实际上,这也是容器部署时间长的原因--为神经网络下载了很多包,相当多的相关包,安装时间很长。不过会有一篇关于神经网络和Integrated ML(一体化机器学习)的单独文章,我很快会发表。
我还要说的是,预测的结果被输入到同一个数据库,所以你可以通过BI工具看到数据集。
第十一章 信号(一) - 概念
背景
维基百科对信号量有这样的定义:“在计算机科学中,特别是在操作系统中,信号量是一种变量或抽象数据类型,用于控制多个进程在并行编程或多用户环境中对公共资源的访问。”信号量不同于互斥体(或锁)。互斥锁最常用于管理竞争进程对单个资源的访问。当一个资源有多个相同的副本并且这些副本中的每一个都可以由单独的进程同时使用时,就会使用信号量。
考虑一个办公用品商店。它可能有几台复印机供其客户使用,但每台复印机一次只能由一个客户使用。为了控制这一点,有一组键可以启用机器并记录使用情况。当客户想要复印文件时,他们向职员索取钥匙,使用机器,然后归还钥匙,并支付使用费。如果所有机器都在使用,客户必须等到钥匙归还。保存键的位置用作信号量。
该示例可以进一步推广到包括不同类型的复印机,也许可以通过它们可以制作的副本的大小来区分。在这种情况下,将有多个信号量,如果复制者在复制的大小上有任何重叠,那么希望复制共同大小的客户将有两个资源可供提取。
介绍
信号量是共享对象,用于在进程之间提供快速、高效的通信。每个信号量都是类 %SYSTEM.Semaphore 的一个实例。信号量可以建模为一个共享变量,它包含一个 64 位非负整数。信号量上的操作在共享它的所有进程中以同步的方式更改变量的值。按照惯例,值的变化会在共享信号量的进程之间传递信息。
在前一篇文章中,我已经演示了一种简单的方法来记录数据的变化。在这个时候,我改变了负责记录审计数据的 "审计抽象类 "和记录审计日志的数据结构。
我已经将数据结构改为父子结构,其中将有两个表来记录 "交易 "和在该交易中改变的 "字段的值"。
看一下新的数据模型:
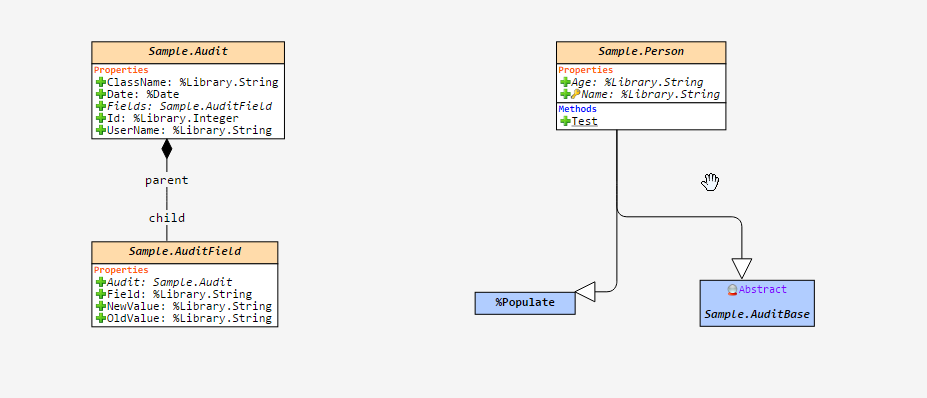
看看从 "审计类 "改变的代码吧:
{ Trigger SaveAuditAfter [ CodeMode = objectgenerator, Event = INSERT/UPDATE, Foreach = row/object, Order = 99999, Time = AFTER ]
{
#dim %compiledclass As %Dictionary.CompiledClass
#dim tProperty As %Dictionary.CompiledProperty
#dim tAudit As Sample.Audit Do %code.WriteLine($Char(9)_"; get username and ip adress")
Do %code.
下面的代码允许用户查看其实例的审计设置。通过运行类方法 "test "来运行该代码。:
class objectscript.checkAudit Extends %RegisteredObject
{
classmethod test() {
w "Checking for Auditing...",!
Set SYSOBJ = ##class(Security.System).%OpenId("SYSTEM")
If +SYSOBJ = 0 Set SYSOBJ = ##class(Security.System).%New()
i SYSOBJ.AuditEnabled {
w "Security Auditing is enabled for the following services",!
s rs=##class(%ResultSet).%New("Security.Events:ListAllSystem")
s sc=rs.Execute() If $$$ISERR(sc) Do DisplayError^%apiOBJ(sc) Quit
while rs.%Next() {
d:rs.Data("Enabled")="Yes" rs.%Print()
}
d rs.Close()
在这篇文章中,我将解释如何通过使用CSP Web应用程序以及启用/禁用和认证/取消认证任何Web应用程序的代码来进行认证、授权和审计。
- 在线 Demo -- https://dappsecurity.demo.community.intersystems.com/csp/user/index.csp (SuperUser | SYS)
- 推荐大家看下这个视频: https://www.youtube.com/watch?v=qFRa3njqDcA
应用层
第十章 设置结构化日志记录(二)
注:IRIS有,Cache无。
启用结构化日志记录
^LOGDMN 例程允许管理结构化日志记录;还有一个基于类的 API,将在下一节中介绍。
要使用 ^LOGDMN 启用结构化日志记录:
- 打开终端并输入以下命令:
set $namespace="%sys"
do ^LOGDMN
这将启动一个带有以下提示的例程:
1) Enable logging
2) Disable logging
3) Display configuration
4) Edit configuration
5) Set default configuration
6) Display logging status
7) Start logging
8) Stop logging
9) Restart logging
LOGDMN option?
- 按
4以便可以指定配置详细信息。然后,该例程会提示输入以下项目:
a. 最低日志级别,以下之一:
-2— 详细的调试消息(例如十六进制转储)。-1— 不太详细的调试消息。0— 信息性消息,包括所有审计事件。1(默认值)— 警告,表示可能需要注意但未中断操作的问题。2— 严重错误,表明问题已中断操作。3— 致命错误,表示问题导致系统无法运行。
b. 管道命令,它指定系统将结构化日志发送到哪里。


