双击安装文件
.png)
选择同意协议,下一步
.png)
实例名称默认IRISHEALTH,不需要修改,直接下一步
.png)
安装路径,可修改,但不可使用中文路径
.png)
安装类型选择Development,点击下一步
.png)
选择Unicode,下一步
.png)
选择Normal,下一步
.png)
默认选项,不做修改,下一步
输入IRIS管理账户密码
输入CSP服务管理密码,和上一步密码保持一致。
.png)
点击安装,等待安装成功
.png)
.png)
InterSystems IRIS for Health™ 是全球第一个也是唯一一个专门为医疗应用程序的快速开发而设计的数据平台,用于管理全世界最重要的数据。它包括强大的开箱即用的功能:事务处理和分析、可扩展的医疗保健数据模型、基于 FHIR 的解决方案开发、对医疗保健互操作性标准的支持等等。所有这些将使开发者能够快速实现价值并构建具有突破性的应用程序。了解更多信息。
双击安装文件
选择同意协议,下一步
实例名称默认IRISHEALTH,不需要修改,直接下一步
安装路径,可修改,但不可使用中文路径
安装类型选择Development,点击下一步
选择Unicode,下一步
选择Normal,下一步
默认选项,不做修改,下一步
输入IRIS管理账户密码
输入CSP服务管理密码,和上一步密码保持一致。
点击安装,等待安装成功
大家好!
在这里跟大家分享一下我在大奖赛上的项目 :)
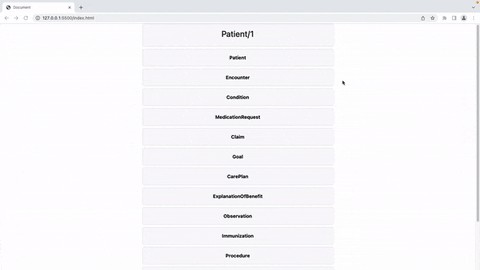
FHIR病人查看器是一个建立在Vue.js上的单页、反应式渲染工具,它以对人友好的方式显示从对InterSystems FHIR服务器的/Patient/{id}/$everything调用返回的数据。在自述文件中,包括3个主要内容:
谢谢大家! 本次大赛的参赛作品质量很好!
Dan
你好,我很高兴地宣布向OpenExchange和目前的比赛提交的一个作品,即FHIR匿名化代理。FHIR匿名化代理为任何现有的FHIR服务器增加了一个透明的匿名化层,使客户能够在FHIR服务器上进行查询--其中可能包含个人识别信息--并收到一个即时的匿名化数据版本。
代理机制是通过互操作性Production、BPLs和DTLs以及FHIR互操作性适配器在IRIS for Health平台上实现的。匿名化包括所有身份ID和个人数据,并可通过DTLs进行配置。
OpenExchange的演示应用程序带有一个内置的FHIR endpoint,并以会填充一些示例数据。试一下,或者将你自己的FHIR服务器配置为代理目标亲自测试一下 ![]()
Hi,大家好!
您曾经实施过DICOM集成吗?也许您已经百度了一些样例,甚至是模拟器。希望本文的例子能给您带来帮助。
DICOM 是一个广泛用于医疗诊断影像的消息标准。您可以使用IRIS For Health或者Health Connect在互操作性Production中使用DICOM标准,在这里您可以找到文档.
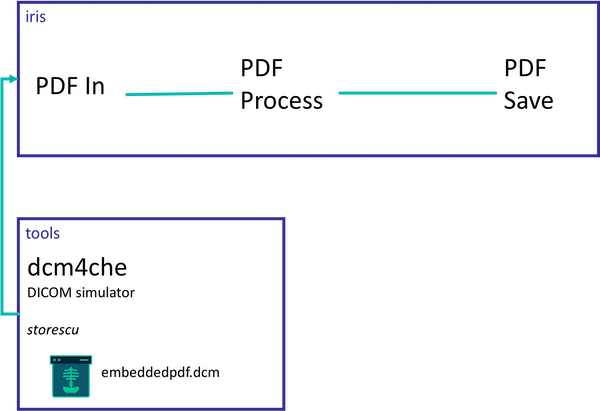
在很多情况下,当您开发一个DICOM集成时,您可以运行一个模拟器来扮演一些外部系统(如PACS),可以在连接到一个真正的系统之前充分测试您想要实现的流程,这一点真的很有用。
在这里您可以找到一个使用IRIS For Health的DICOM整合例子,还有一个叫做dcm4che的模拟器
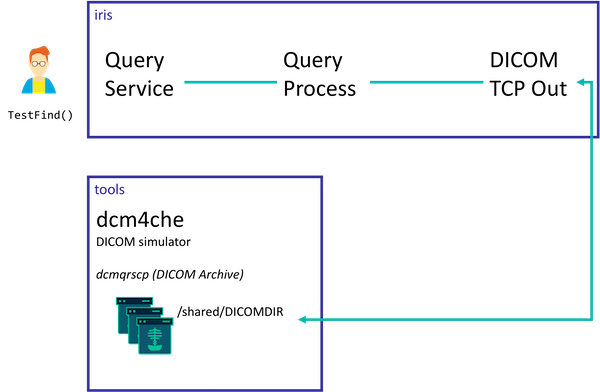
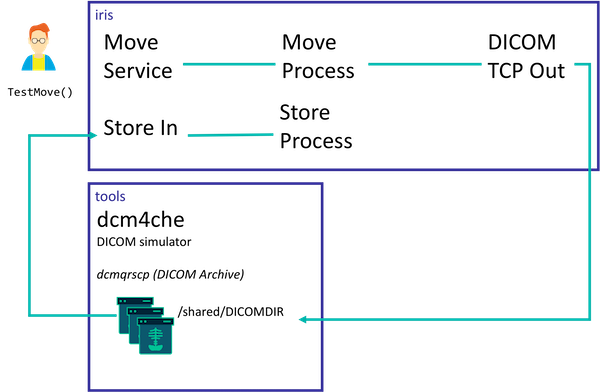
在这个例子里, 实现了两个不同的场景:
查询流程:
检索流程:
欢迎多提宝贵意见,谢谢!:)
#Open Exchange
您可能已经看到邀请分享您的 Open Exchange 应用程序的演示:Share a Demo of Your Open Exchange Application
它背后的服务——InterSystems Online Demo Server (ODS)——这不是什么新事物
作为奖励积分,我在 21 年 3 月的 InterSystems 开发者工具大赛:InterSystems Developer Tools Contest 中第一次看到它。
在后来的比赛中成为一个固定的奖励项目。实际是#24。
到今天,我们已经看到 OEX 中列出了 80 个可在 ODS 上使用的软件包:80 packages listed in OEX as available on ODS
对我来说,开发人员的优势是显而易见的:
在使用xDBC连接到字符集为US7ASCII的Oracle数据库时,大家可能遇到过中文的乱码问题,尤其是使用Oracle自己的xDBC驱动的时候。
字符集为US7ASCII的Oracle数据库虽然可以保存中文数据,但给客户端带来了很多麻烦,需要对获取和提交的数据进行转码。
在Ensemble/Health Connect/InterSystems IRIS 中使用SQL适配器连接到这样的Oracle数据库时,可以使用$ZCVT函数进行转码。
1. $ZCVT函数
$ZCVT函数是广泛使用的字符串转换函数,可以做大小写转换、编码转换、URL 和 URI 转换等。我们用其编码转换能力来解决字符集转码问题。
2. 获取的SQL结果集数据有中文时
这时,Oracle的驱动返回的中文数据通常是GB码,而不是Unicode或UTF码。可以通过$ZCVT函数对GB码的数据进行转码,转换为Unicode:
Set tCorrectData = $ZCVT(tOriginalData,"I","GB18030")其中$ZCVT函数的第一个参数tOriginalData是获取到到结果集字段值;第二个参数“I”说明tOriginalData是输入字符串;第三个参数“GB18030”是说明输入字符串的字符集编码是GB18030。
在集成平台建设如火如荼的今天,如何能最大程度发挥集成平台价值,让集成平台不再止步于业务系统接口的打通,而是真正作为医院的IT基础架构,释放出更大价值?5月27日,InterSystems技术总监乔鹏 ( @Qiao Peng )和InterSystems销售工程师王菁伟( @Jingwei Wang)将针对集成平台建成后的应用价值,围绕“业务流程再造”角度,探讨以低代码方式梳理并再造业务闭环流程、从而赋能业务创新并促进医院精细化管理和高质量发展。点击链接或扫描报名。
所有人现在可以在 https://evaluation.intersystems.com下载IRIS和IRIS for Health社区和企业版 。
客户以及潜在客户都可以尝试我们最新最强的功能,包括一些还没有发布的新特性。
对于潜在客户,只要选择名称中带有"(预览)"的选项,就可以下载预览软件。
.png)
对于客户和InterSystems员工--只需拨动预览复选框,这将包括可用版本菜单下拉中的预览软件:
.png)
https://community.intersystems.com/post/introducing-evaluation-service-community-edition-downloads
https://community.intersystems.com/post/intersystems-evaluation-service
有任何问题欢迎拨打 4006019890 或咨询您的ISC客户经理。
在软件开发和业务集成中,规则无处不在:会员折扣的计算规则、根据消息类型和内容将其路由到不同目标系统的路由规则。还有一个规则发挥重要作用的地方- 辅助决策规则,例如临床知识库和医疗质量指标规则。
规则经常需要随业务调整和知识积累进行调整,而规则的调整是业务和行业专家定的。如果规则是以代码硬编码的,这些调整需要程序员改动,一来不直观、需要业务专家与程序员大量的沟通成本,二来硬编码改动会对应用伤筋动骨,甚至带来风险,三来没法控制新规则生效的时间 – 总不能让程序员在新规则生效的那一刻去编译和部署吧。
InterSystems规则引擎可以帮助我们解决这些问题,于构建、执行和记录消息路由规则和普通的业务规则,带给应用和集成方案充分的灵活性和可用性。甚至业务专家和临床信息学家都可以通过低代码的、图形化的规则编辑器修改规则和指定规则生效和失效时间。
InterSystems规则引擎是InterSystems IRIS数据平台和Health Connect与Ensemble集成平台的组件。创建的规则可以被单独调用,也可以被业务流程调用。
本篇介绍规则的如何使用InterSystems规则编辑器创建规则和规则引擎执行规则的逻辑。
1. 规则基本概念
在设计规则前,先了解一下规则的基本概念。
上下文是用于规则定义的数据模型。
InterSystems Kubernetes Operation(IKO)3.3版现已通过WRC下载页面和InterSystems容器注册中心提供。
IKO通过提供一个易于使用的irisCluster资源定义,简化了在Kubernetes中使用InterSystems IRIS或InterSystems IRIS for Health的工作。完整的功能清单见IKO文档,包括轻松的分片、镜像和ECP的配置。
IKO 3.3 亮点:
irisCluster的一部分进行部署irisCluster的一部分进行部署和管理InterSystems IRIS 2021.1 的发布引入了自适应分析(Adaptive Analytics)的介绍。 为了开始使用和熟悉 InterSystems IRIS BI cube示例,我们创建了一个用于自适应分析的 HoleFoods 应用程序示例模版。 此示例应用程序可在 Open Exchange 上获得, 还有一个学习服务课程learning services course 可用于了解有关自适应分析的更多信息。
.png)
我们的一位客户五一期间向使用IRIS搭建的数据流推送一家三甲医院数年的历史数据,导致实施的同事们经历了一系列噩梦,包括但不限与:
1. 由于未通知实施团队有这样规模的数据推送,数据推送过程与全库备份任务重叠。尽管实例和数据流正常运行,但备份任务与数据流争抢IO,导致备份任务不能在预期时间内完成,实施童鞋五一加班处理问题。
2. 为了节省磁盘空间,服务器上部署了定期删除IRIS备份文件的任务,原本能够保持一周的全备+增量备份,但在本次数据暴增的情况下,新的备份尚未完成而旧的全备已被删除,导致问题发生时没有可用于恢复的备份。
3. 由于这次数据推送前未进行数据质量校验,推送的数据全部不合规,但已经历了较长的数据流进行处理全部入库;同时由于备份文件已被删除,无法通过恢复数据库的方法回滚,导致实施童鞋不得不逐条从生产环境三个库的数百张表中挑出问题数据逐一删除,从五一放假结束至今还未完成善后工作。大家可以设想一下,如果备份还在,那么恢复备份就可以了。
因此,我们希望再次提醒各位在前线奋斗的亲们:
1. 善待你的备份。尽管对于大型医院或医疗集团来说,两周的全备+增量备份策略下,备份文件会占据数个TB的存储空间。但在需要回滚时,这几个T的空间能救命。
2. 保持可用的测试环境。尤其是对于可能出现随机数据需求的客户,随机产生数据需求意味着随机出现测试需求。
3. 验证新数据的合规性,永远不要假设新数据一定合规。
所有源代码均在: https://github.com/antonum/ha-iris-k8s
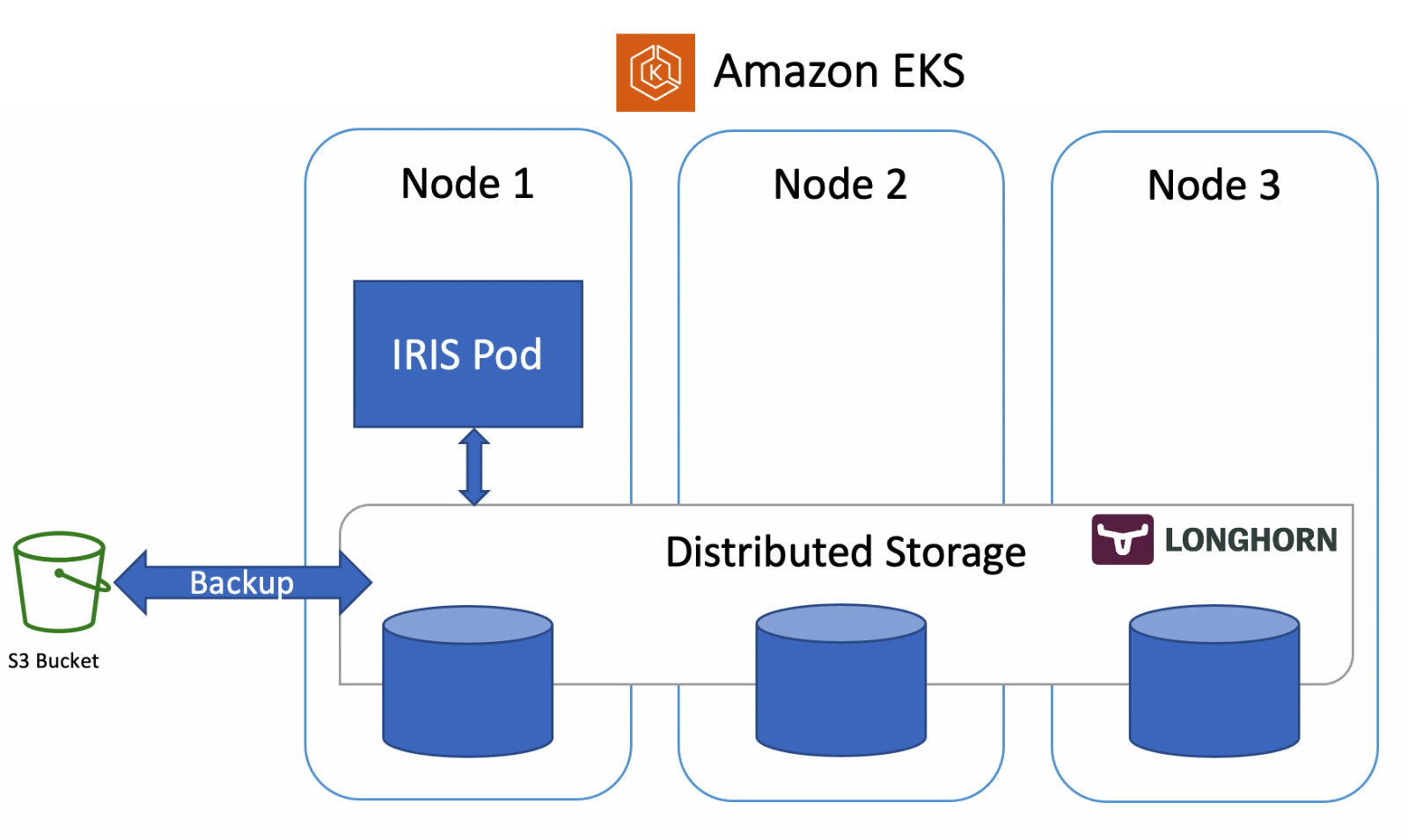
在上一篇文章中,我们讨论了如何在k8s集群上建立具有高可用性的IRIS,基于分布式存储,而不是传统的镜像。作为一个例子,那篇文章使用了Azure AKS集群。在这一篇中,我们将继续探讨k8s上的高可用配置。这一次,基于Amazon EKS(AWS管理的Kubernetes服务),并将包括一个基于Kubernetes 快照进行数据库备份和恢复的选项。
开始干活. 首先需要一个AWS账户,安装 AWS CLI, kubectl 和 eksctl 工具. 要创建新的集群,请运行以下命令:
eksctl create cluster \ --name my-cluster \ --node-type m5.2xlarge \ --nodes 3 \ --node-volume-size 500 \ --region us-east-1
这个命令需要大约15分钟,部署EKS集群并使其成为你的kubectl工具的默认集群。你可以通过运行以下代码来验证你的部署:
kubectl get nodes NAME STATUS ROLES AGE VERSION ip-192-168-19-7.
就在不久以前,临床科研人员还需要依靠三联的纸质NCR表格,手工收集从堆积如山的手写电子病历中提炼出来的病人数据。从又大又重的《医师案头参考》(PDR)撕下几页,通过传真机发送给FDA,用于药物安全报告。业内专业人士接受了大量的培训,以确保数据经过源文件验证、双键处理,并在经过看似无休止的查询以纠正错误之后,保证其符合目的。
值得庆幸的是,随着电子健康档案的广泛采用,健康数据的数字化,这一过程得到了极大的改善。但是,鉴于临床研究进展缓慢,特别是精美的Excel表格仍由人工数据摘要完成,该领域早该有更多的技术变革,特别是围绕释放医疗互操作性的全部好处。如果我们能做到这一点,生命科学公司将有机会利用宝贵的健康数据来确保病人的安全,优化新药的疗效,并使临床开发过程更加高效,减少错误。
我们可能会比你想象的更快地将临床研究与健康数据联系起来。为什么?火神计划(Project Vulcan)正在进行中。这个项目组是最近在HL7的FHIR加速器项目中创建的,它已经召集了来自医疗、技术和生命科学领域的30多个利益相关的组织个和机构,利用FHIR这个医疗专用互操作性标准来进行临床和转化研究。自从我们在去年年初加入后,我们高兴的看到火神计划成员制定的早期想法越来越接近于功能现实。
Kong提供了一个开源的配置管理工具(用Go语言编写),称为decK(代表声明式Kong)
deck ping Successfully connected to Kong! Kong version: 2.3.3.2-enterprise-edition
deck dump
deck diff
updating service alerts {
"connect_timeout": 60000,
- "host": "172.24.156.176",
+ "host": "192.10.10.在一次重大的版本升级中,建议重新编译你所有命名空间的类和例程。 (主要版本的安装后任务).
do $system.OBJ.CompileAllNamespaces("u")do ##Class(%Routine).CompileAllNamespaces()
为了自动完成这项管理任务并记录任何错误,下面是一个导入并编译到USER命名空间的类的例子,你可以在每次升级后使用它 : admin.utils.cls
InterSystems流程自动化与工作流引擎
集成平台除了集成业务系统,打通数据与业务流程外,另一个核心的功能就是流程自动化(BPA)。
流程自动化涉及几个重要的特性:
其中第4和5点都是和工作流程相关的。
什么是工作流程(Workflow)?它和业务流程(Business Process)有何区别?为何集成平台要涉及对工作流程的管理?
有很多方法可以使用Intersystems生成excel文件,其中一些是ZEN报告、IRIS报告(Logi报告或正式称为JReports),或者我们可以使用第三方Java库,可能性几乎是无限的。
但是,如果你想只用Caché ObjectScript创建一个简单的电子表格呢?(没有第三方应用程序)
在我的案例中,我需要生成包含大量原始数据的报告(财务人员喜欢这些数据),但是我的ZEN/IRIS失败了,给了我一个我想称之为 "零字节的文件",基本上说java的内存用完了,并导致报告服务器上的重载。
这可以用Office Open XML(OOXML)来完成。Office Open XML格式是由一个ZIP包内的一些XML文件组成的。因此,基本上我们需要生成这些XML文件,并将其压缩重命名为.xslx。就这么简单。
这些文件遵循一套简单的惯例,称为开放包装惯例。你需要声明各部分的内容类型,以及告诉消费应用程序应该从哪里开始。
为了创建一个简单的电子表格,我们至少需要5个文件。
workbook.xml
工作簿是各种工作表的容器。
在最近一次探索马里兰小镇的 "度假 "期间,我偶然发现了一家非常令人愉快的书店,在那里我愉快地消磨了一下午。我和我的家人都是读者,喜欢各种类型的书--新的、二手的、印刷的、电子的。我们尽量在当地购物,以帮助零售店保持运营。
这次访问促使我思考图书行业所发生的事情与我们的医疗保健系统所发生的事情之间的一些相似之处。
医疗保健行业与图书行业的趋势
数字化
我们阅读内容的格式已经发生了根本性的变化。在2020年,电子书几乎占美国市场的四分之一。音频书占美国图书收入的10亿美元。许多印刷书籍是按需出版的,而不是保存在库存中。同样,医疗保健早已不再是一个“伸出舌头说啊 ”的行业,基因组测试、由人工智能算法读取的X射线、可植入设备和远程医疗访问已经改变了医疗的面貌。
虚拟服务
书店现在有多种形式,医疗机构也是如此。订阅图书服务,从当地独立的小公司、大的连锁店、电子零售的网上订单。而与你的本地门诊竞争的是你手机上的一个应用程序。同样,你的治疗师可能是一个机器人,你的基层医疗服务可能由你社区附近药店的驻店医师提供,你可能在一个办公园区做手术。在所有这些竞争中,我们如何确保在我们需要时仍有健康的、提供全面服务的医院?
更智能的算法
分析和预测模型现在几乎和个人推荐一样重要。过去,当我想要一本书的建议,或者一个医生,我就会问朋友。虽然我仍然这样做,但我也同样有可能去看Goodreads,或查看在线医生评论。

InterSystems数据平台上可能运行着多种应用,例如Web网页应用、SOAP服务、REST API、HL7 接口、SQL服务等等。这些应用种类繁多,面临的安全风险也是巨大的,例如代码注入攻击和HTTP的跨站请求伪造攻击等。
这其中代码注入攻击和针对Web应用的攻击尤其需要重视。
代码注入攻击通常和我们编写的程序相关,需要在程序编写时注意避免。
SQL注入攻击是典型的代码注入攻击,通过从外部注入恶意SQL语句获得数据权限并获得敏感数据。关系型访问方式都是通过客户端SQL语句传入执行的,因此它是数据库重点需要防范的。
InterSystems数据平台并不支持以分号分割的多条SQL语句作为一个SQL命令执行,因此它本身免疫了主要的SQL注入攻击手段。
InterSystems数据平台支持动态SQL,即允许SQL命令作为方法的字符串参数传入,这会给SQL注入攻击留有隐患。在编程时,应避免开放服务用于接受完整的SQL语句作为参数,而是通过SQL动态传参来构建运行时SQL。
InterSystems数据平台支持行级安全,这有助于避免在SQL注入攻击时,将所有数据返回给攻击请求。
InterSystems数据平台提供了系统函数$ZF,用以调用外部命令。其中$ZF(-1)和$ZF(-2)用以调用服务器操作系统的命令。

这篇文章是对我的 iris-globals-graphDB 应用的介绍。
在这篇文章中,我将演示如何在Python Flask Web 框架和PYVIS交互式网络可视化库的帮助下,将图形数据保存和抽取到InterSystems Globals中。
#create and establish connection
if not self.iris_connection:
self.iris_connection = irisnative.createConnection("localhost", 1972, "USER", "superuser", "SYS")
# Create an iris object
self.iris_native = irisnative.createIris(self.iris_connection)
return self.iris_native
#import nodes data from csv file
isdefined = self.iris_native.isDefined("^g1nodes")
if isdefined == 0:
with open("/opt/irisapp/misc/g1nodes.csv", newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
self.iris_native.set(row["name"], "^g1nodes", row["id"])
#import edges data from csv file
isdefined = self.iris_native.isDefined("^g1edges")
if isdefined == 0:
with open("/opt/irisapp/misc/g1edges.csv", newline='') as csvfile:
reader = csv.DictReader(csvfile)
counter = 0
for row in reader:
counter = counter + 1
#Save data to globals
self.iris_native.set(row["source"]+'-'+row["target"], "^g1edges", counter)
#Get nodes data for basic graph
def get_g1nodes(self):
iris = self.get_iris_native()
leverl1_subscript_iter = iris.iterator("^g1nodes")
result = []
# Iterate over all nodes forwards
for level1_subscript, level1_value in leverl1_subscript_iter:
#Get data from globals
val = iris.get("^g1nodes",level1_subscript)
element = {"id": level1_subscript, "label": val, "shape":"circle"}
result.append(element)
return result
#Get edges data for basic graph
def get_g1edges(self):
iris = self.get_iris_native()
leverl1_subscript_iter = iris.iterator("^g1edges")
result = []
# Iterate over all nodes forwards
for level1_subscript, level1_value in leverl1_subscript_iter:
#Get data from globals
val = iris.get("^g1edges",level1_subscript)
element = {"from": int(val.rpartition('-')[0]), "to": int(val.rpartition('-')[2])}
result.append(element)
return result
<script type="text/javascript">
// initialize global variables.
var edges;
var nodes;
var network;
var container;
var options, data;
// This method is responsible for drawing the graph, returns the drawn network
function drawGraph() {
var container = document.getElementById('mynetwork');
let node = JSON.parse('{{ nodes | tojson }}');
let edge = JSON.parse('{{ edges | tojson }}');
// parsing and collecting nodes and edges from the python
nodes = new vis.DataSet(node);
edges = new vis.DataSet(edge);
// adding nodes and edges to the graph
data = {nodes: nodes, edges: edges};
var options = {
"configure": {
"enabled": true,
"filter": [
"physics","nodes"
]
},
"nodes": {
"color": {
"border": "rgba(233,180,56,1)",
"background": "rgba(252,175,41,1)",
"highlight": {
"border": "rgba(38,137,233,1)",
"background": "rgba(40,138,255,1)"
},
"hover": {
"border": "rgba(42,127,233,1)",
"background": "rgba(42,126,255,1)"
}
},
"font": {
"color": "rgba(255,255,255,1)"
}
},
"edges": {
"color": {
"inherit": true
},
"smooth": {
"enabled": false,
"type": "continuous"
}
},
"interaction": {
"dragNodes": true,
"hideEdgesOnDrag": false,
"hideNodesOnDrag": false,
"navigationButtons": true,
"hover": true
},
"physics": {
"barnesHut": {
"avoidOverlap": 0,
"centralGravity": 0.3,
"damping": 0.09,
"gravitationalConstant": -80000,
"springConstant": 0.001,
"springLength": 250
},
"enabled": true,
"stabilization": {
"enabled": true,
"fit": true,
"iterations": 1000,
"onlyDynamicEdges": false,
"updateInterval": 50
}
}
}
// if this network requires displaying the configure window,
// put it in its div
options.configure["container"] = document.getElementById("config");
network = new vis.Network(container, data, options);
return network;
}
drawGraph();
</script>
#Mian route. (index)
@app.route("/")
def index():
#Establish connection and import data to globals
irisglobal = IRISGLOBAL()
irisglobal.import_g1_nodes_edges()
irisglobal.import_g2_nodes_edges()
#getting nodes data from globals
nodes = irisglobal.get_g1nodes()
#getting edges data from globals
edges = irisglobal.get_g1edges()
#To display graph with configuration
pyvis = True
return render_template('index.html', nodes = nodes,edges=edges,pyvis=pyvis)
下面是关于此项目的 介绍视频:
要用程序编辑Production(界面),你可以使用互操作性API和SQL查询的组合。
从顶层了解你目前正在工作的命名空间和生产是很重要的。
// Object script
// The active namespace is stored in this variable
$$$NAMESPACE
// Print namespace
Write $$$NAMESPACE
# Python
import iris
# The active namespace is returned from this method
iris.utils._OriginalNamespace()
# Print namespace
print(iris.utils._OriginalNamespace())
>>> DEMONSTRATION
另外,知道你的Production名称是很重要的,你可以使用以下API获得名称空间中正在运行的Production。
// ObjectScript
USER>ZN "DEMONSTRATION"
// Get current or last run production
DEMONSTRATION>W ##class(Ens.InterSystems 数据平台对用户和角色提供全面的管理和安全配置功能。加强数据平台的安全,需要加强对于用户和角色的管理。
系统提供了一系列预置的用户账户,这些账户管理对应特殊的系统功能:
|
用户 |
说明 |
|
UnknownUser |
匿名用户,通过“未验证”方式登录到系统的用户 |
|
_SYSTEM |
SQL系统管理员 |
|
SuperUser |
超级用户 |
|
Administrator |
安装系统的用户 |
|
Admin |
系统管理员 |
|
CSPSystem |
Web网关管理员 |
|
IAM |
IAM用户 |
|
_PUBLIC |
内部使用 |
|
_Ensemble |
内部使用 |
InterSystems数据平台有一些系统级别的用户安全配置,例如密码模式、密码有效天数、无效登录限制(多少次登录失败后要禁用用户账户)、非活动限制(多少天未登录后禁用用户账户)等。这些系统级配置通过管理门户>系统>安全管理>系统范围的安全参数:
.png)
三级等保对于用户的密码强度是有要求的。弱密码只需要0.19毫秒就能被破解,而8位强密码破解需要上百年。
数据平台不仅要安全,还要合规,三级等保是我们要符合的主要安全规范。InterSystems的数据平台和集成平台产品都和三级等保有关。如果没有正确配置它们的安全选项,就会影响到整个系统的安全,影响到合规性。
在生产环境上,如何配置安全的InterSystems的数据平台,并达到三级等保的要求?
这个系列文章,针对InterSystems 数据平台的安全架构,围绕对三级等保的合规性展开,介绍如何配置出一个安全、合规的数据平台。
注:本文提到的InterSystems的数据平台,包括Caché数据库、Ensemble集成平台、HealthConnect医疗版集成平台和InterSystems IRIS数据平台。
|
三级等保要求
|
对数据平台的要求
|
|
身份鉴别
|
确保用户身份是真实、准确的
|
|
访问控制
|
控制:谁、以什么方式、从什么设备可以访问什么数据和功能? |
系统实用类:SYS.Database中的查询FreeSpace可以用来在任何时候检查磁盘上的自由空间。
下面是在IRIS终端中的尝试方法(进入%SYS命名空间,然后运行它)。
zn "%SYS"
set stmt=##class(%SQL.Statement).%New()
set st=stmt.%PrepareClassQuery("SYS.Database","FreeSpace")
set rset=stmt.%Execute()
// 一次性显示所有
do rset.%Display()输出结果示例如下。
*在命令执行的例子中,所有的数据库都放在同一个磁盘上,所以所有的磁盘空闲空间(DiskFreeSpace)返回相同的值。
注意:下面内存设置数值仅限参考,具体内存数值的设置是否合适,依赖于更多实际使用情况决定。
主要需要设置下面几个内存相关配置:
(下面比例适用于服务器仅运行单实例InterSystems IRIS)
数据库缓存Database cache:
建议小于64G内存设置总内存50%,大于等于64G内存设置70%总内存
程序缓存routine cache:
建议设置1023MB
gmheap:
建议设置1048576KB(1024MB)
LockSize:
建议最少设置134217728 Bytes (128MB),如果在系统日志中提示locksize相关错误或警报,应相应增加。
如果在一台服务器上安装了多个InterSystems IRIS 实例,那么要保证 所有InterSystems IRIS 运行实例的 Shared memory(database cache + routine cache + gmheap) 总值小于 Hugepage设定的值
hugePages :
建议设置值大于系统所有InterSystems IRIS 运行实例的 Shared memory(database cache + routine cache + gmheap) 总值再往上取整+1G。之后监控cache efficiency 调整设置大小。
此文章也是对问题 在不重建的情况下插入索引Inserting an index without reconstruction 的一种解释
在使用SQL语言对 InterSystems IRIS 中的表进行查询时,有时候会发现返回的结果与实际有出入,特别是使用count() 函数,或者select 查询时,返回的结果少于实际应返回的值。
这种情况往往是由于数据表格的索引值出了问题。
索引出问题的主要原因可能是:
要解决或者要检查是不是索引引发的问题,可以使用%ValidateIndices()函数,它有两种方式使用
$SYSTEM.OBJ.ValidateIndices(classname,idxList,autoCorrect,lockOption,multiProcess)
或者
##class(classname).%ValidateIndices(idxList,autoCorrect,lockOption,multiProcess)
两种使用方法最大的差别是:$SYSTEM.OBJ.
Docker 20.10.14(2022年3月23日发布)改变了赋予容器的Linux能力,其方式与InterSystems IRIS 2021.1(及以上)容器的Linux能力检查器不兼容。
在Linux上运行Docker 20.10.14的用户会发现,IRIS 2021.1+容器将无法启动,并且日志会错误地报告缺少所需的Linux能力。 比如说。
[ERROR] Required Linux capability cap_setuid is missing. [ERROR] Required Linux capability cap_dac_override is missing. [ERROR] Required Linux capability cap_fowner is missing. [ERROR] Required Linux capability cap_setgid is missing. [ERROR] Required Linux capability cap_kill is missing. [FATAL] Your IRIS container is missing one or more required Linux capabilities.
遇到这个问题的用户需要调整传递给容器入口的命令行,以禁用对Linux功能的检查。
我想介绍一下我参加Globals竞赛的新项目。一个非常新的Globals浏览器视图
.png)