.png)
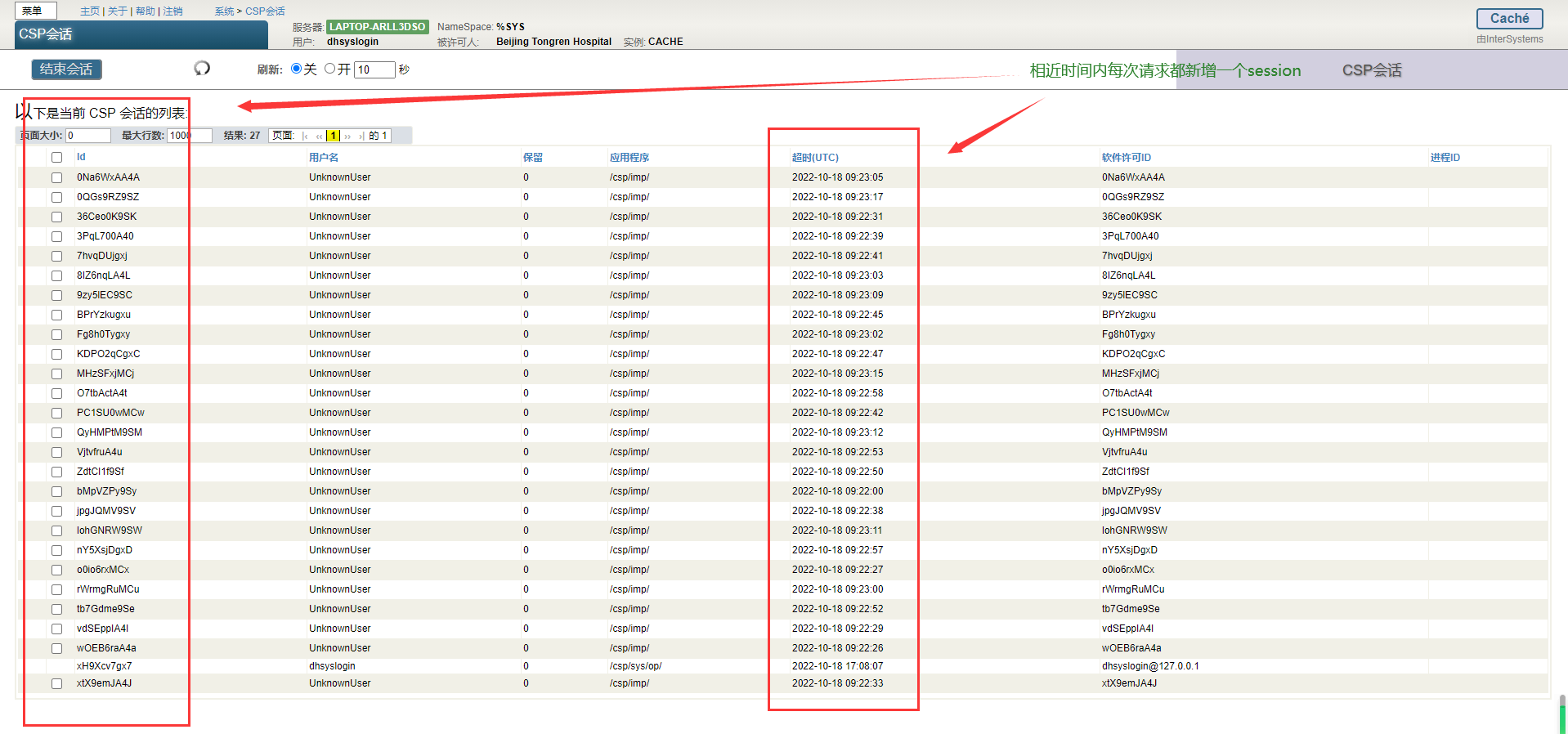
 按查看数
按查看数 第十一章 发送和接收IBM WebSphere MQ消息
InterSystems IRIS为IBM WebSphere MQ提供了一个接口,可以使用该接口在InterSystems IRIS和IBM WebSphere MQ的消息队列之间交换消息。要使用此接口,必须能够访问IBM WebSphere MQ服务器,并且IBM WebSphere MQ客户端必须与InterSystems IRIS在同一台计算机上运行。
该接口由%Net.MQSend和%Net.MQRecv类组成,这两个类都是%Net.abstractMQ的子类。这些类使用由InterSystems IRIS在所有合适的平台上自动安装的动态链接库。(这是Windows上的MQInterface.dll;其他平台的文件扩展名不同。)。反过来,InterSystems IRIS动态链接库需要IBM WebSphere MQ动态链接库。
该界面仅支持发送和接收文本数据,不支持二进制数据。
.png)
 Open Exchange app
Open Exchange app
.png)