第三章 执行测试
示例:执行测试
现在使用%UnitTest.Manager.RunTest执行单元测试。以下是方法:
- 在包含单元测试的名称空间中打开终端;在本例中为用户。如果终端未在正确的命名空间中打开,请使用ZN更改命名空间。
- 将
^UnitTestRoot全局值设置为包含导出的测试类的目录的父级。
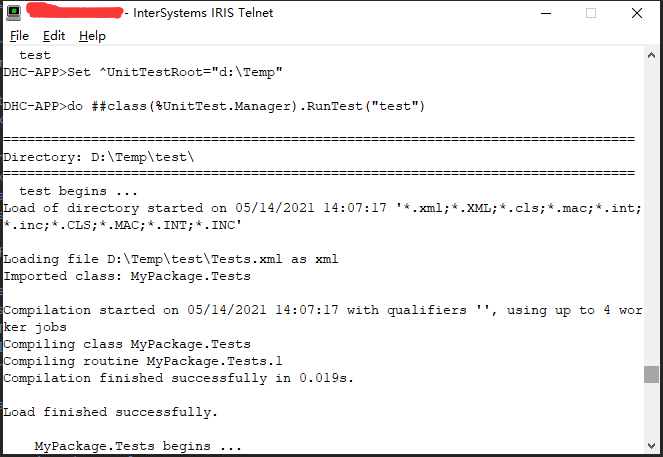
DHC-APP>Set ^UnitTestRoot="d:\Temp"
- 使用方法
%UnitTest.Manager.RunTest执行测试。
DHC-APP>do ##class(%UnitTest.Manager).RunTest("test")
- IRIS从
XML文件加载测试类,编译类,执行测试,从服务器删除测试代码,并向终端发送报告。
HC-APP>do ##class(%UnitTest.Manager).RunTest("test")
===============================================================================
Directory: D:\Temp\test\
===============================================================================
test begins ...
Load of directory started on 05/14/2021 14:07:17 '*.xml;*.XML;*.cls;*.mac;*.int;*.inc;*.CLS;*.MAC;*.INT;*.INC'
Loading file D:\Temp\test\Tests.xml as xml
Imported class: MyPackage.Tests
Compilation started on 05/14/2021 14:07:17 with qualifiers '', using up to 4 worker jobs
Compiling class MyPackage.Tests
Compiling routine MyPackage.Tests.1
Compilation finished successfully in 0.019s.
Load finished successfully.
MyPackage.Tests begins ...
TestAdd() begins ...
AssertEquals:Test Add(2,2)=4 (passed)
AssertNotEquals:Test Add(2,2)'=5 (passed)
LogMessage:Duration of execution: .000061 sec.
TestAdd passed
MyPackage.Tests passed
test passed
Use the following URL to view the result:
http://172.18.18.159:52773/csp/sys/%25UnitTest.Portal.Indices.cls?Index=3&$NAMESPACE=DHC-APP
All PASSED