
 按日期
按日期InterSystems 常见问题系列FAQ
InterSystems 产品里数据 (表、对象、实例数据) 是存在global 变量里的。
每个global 的数据大小可以从管理门户中中点击属性查看Management Portal > System > Configuration > Local Database > Globals page, 然后在global 属性页点击计算大小Calculate Size 按钮。
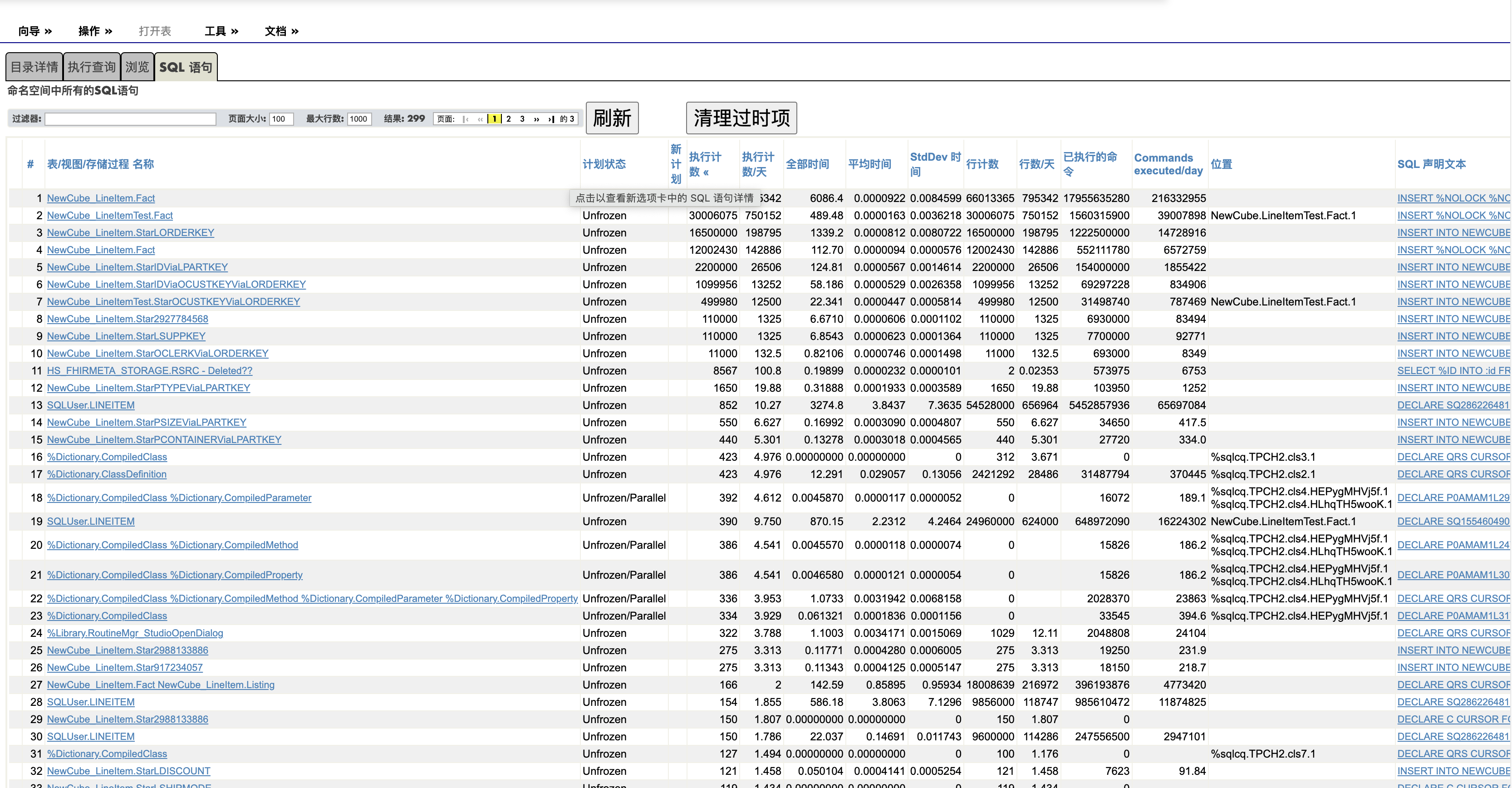
你可以在终端上调用^%GSIZE 来在命名空间里显示数据大小,方法如下.
.png)
.png)
.png)
.jpg)

 Open Exchange app
Open Exchange app.png)