ISC 开发者们,我向你们致敬 👑。
ISC 开发者们,我向你们致敬 👑。
FHIR是标准,是规范,使用FHIR使大家可以使用同一种语言、语义进行交流,名称、API都是统一的,只要符合FHIR标准,任何系统都可交互。对业务开发者来说,大部分接口交互的定义交给FHIR来处理,效率大大提高。
使用 ErrorList 查询 SYS.ApplicationError 类.
执行命令的例子如下.
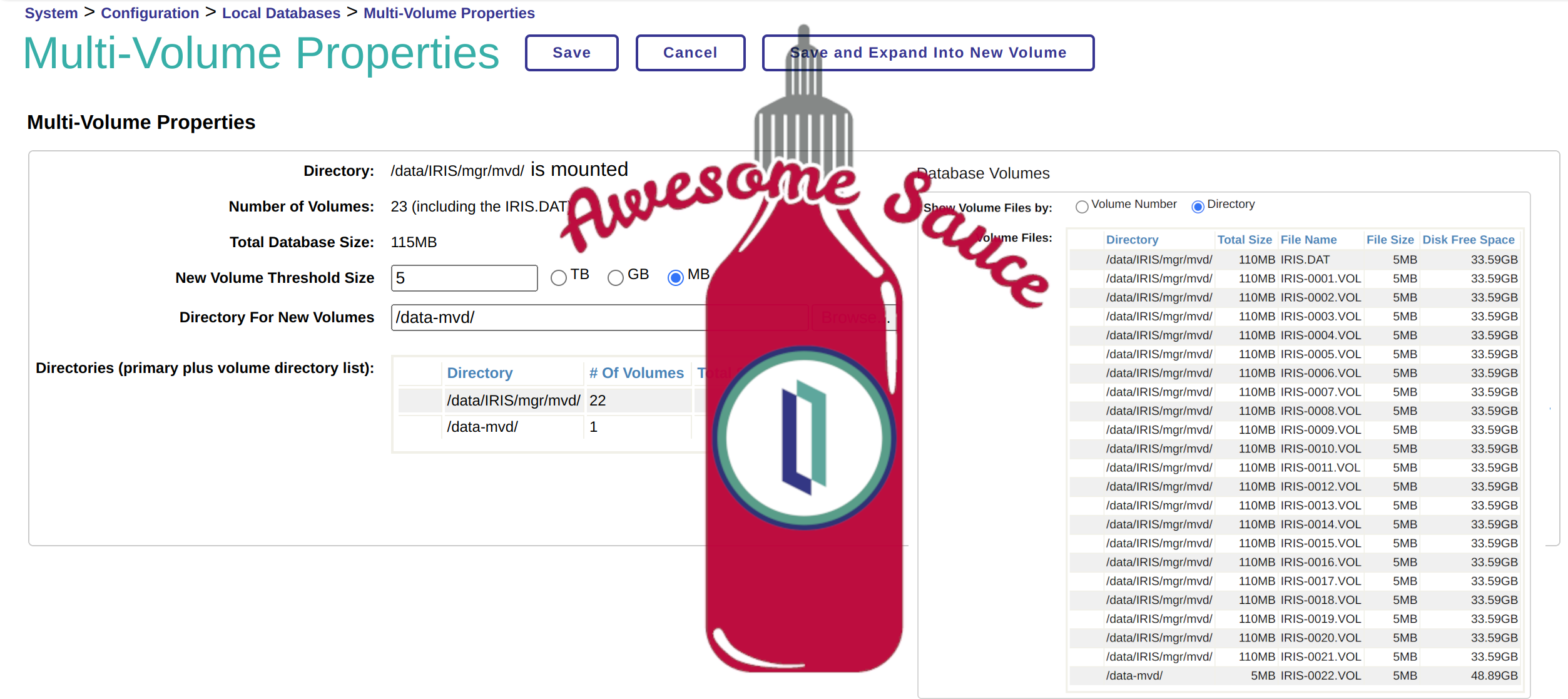
USER>set$namespace以下显示如何获得在浏览行时获取SELECT的列值The following shows how to get column values of a SELECT while navigating through rows.
使用Next()方法来移动到一行(如果行存在的话返回1)
获取一列的话使用 Get("column name"). 具体列名,请参考类文档里面的ErrorList 查询描述。
"USER"For terminal viewing, you can also use the ^%ER routine.
Execute the following while in the namespace you want to reference (the example is executed in the USER namespace).
可以通过 TRY-CATCH 来完成:
#dimAs如果用了 ^%ETN, 从BACK 接入点 (BACK^%ETN)处调用.
请参考另外一篇文章: 如何使用命令获得应用错误 (^ERRORS)
IRIS通过JDBC连接第三方数据库汉字查询乱码,第三方反馈需要设置字符集,不知字符集该如何设置
关键字:PyODBC,unixODBC,IRIS,IntegratedML,Jupyter Notebook,Python 3
几个月前,我简单谈到了关于“将 Python JDBC 连接到 IRIS”的话题。我后来频繁提起它, 因此决定再写一篇 5 分钟的笔记,说明如何“将 Python ODBC 连接到 IRIS”。
在 Windows 客户端中通常很容易设置 ODBC 和 PyODBC,不过我每次在 Linux/Unix 风格的服务器中设置 unixODBC 和 PyODBC 客户端时,都会遇到一些麻烦。
有没有一种简单连贯的方法,可以不安装任何 IRIS,在原版 Linux 客户端中让 PyODBC/unixODBC 针对远程 IRIS 服务器运行?
最近,我花了点时间研究如何在 Linux Docker 环境的 Jupyter Notebook 中从头开始让一个 PyODBC 演示运行起来, 记录下这篇稍微有些繁琐的笔记,以供日后快速参考。
这篇笔记将涉及以下组件:
InterSystems IRIS 允许从任何符合DB-API的Python应用程序对InterSystems IRIS 进行快速、无缝地访问。Python DB-API驱动是对PEP 249 v2.0(Python数据库API规范 v2.0)的完整兼容。
# Embedded Python examples from summer 2022
import iris as dbapi
mytable = "mypydbapi.test_things"
conn = dbapi.connect(hostname='localhost', port=1972, namespace='IRISAPP', username='superuser', password='iris')
# Create table
cursor = conn.cursor()
try:
cursor.execute(f"CREATE TABLE {mytable} (myvarchar VARCHAR(255), myint INTEGER, myfloat FLOAT)")
except Exception as inst:
pass
cursor.close()
conn.commit()
# Create some data to fill in
chunks = []
paramSequence = []
for row in range(10):
paramSequence.append(["This is a non-selective string every row is the same data", row%10, row * 4.57292])
if (row>0 and ((row % 10) == 0)):
chunks.append(paramSequence)
paramSequence = []
chunks.append(paramSequence)
query = f"INSERT INTO {mytable} (myvarchar, myint, myfloat) VALUES (?, ?, ?)"
for chunk in chunks:
cursor = conn.cursor()
cursor.executemany(query, chunk)
cursor.close()
conn.commit()
# conn.close()
sql = f"select * from {mytable}"
rowsRead = 0
cursor = conn.cursor()
cursor.arraysize = 20
cursor.execute(sql)
rc = cursor.rowcount
rows = cursor.fetchall()
for row in rows:
print(row)
rowsRead += len(rows)
cursor.close()
conn.close()ubuntu系统中,查询到的数据都是空字符串
python3 httpTest2.py
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
('', '', '', '', None, '')
代码如下
import pyodbc
import requests
driver = '/usr/irisodbc/bin/libirisodbc35.so'
server = 'xx'
database = 'xx'
username = 'xx'
password = 'xx'
port = 'xx'
cnxn = pyodbc.connect(driver=driver, server=server,port='51773', database=database, uid=username, pwd=password,charset='UTF-8')
cursor = cnxn.
DBServer |
ECPApp |
| 10.1.30.231 | 10.1.30.232 |
CA根服务器 |
DBServer |
ECPApp |
| 10.1.30.231 | 10.1.30.231 | 10.1.30.232 |
| CARoot.cer | DataSever.cer | ECPApp.cer |
| CARoot.key | DataSever.key | ECPApp. |
问题:锁管理里边包含很多WorkQueueMgr的锁,我想批量去移除,比较多,一个一个移除比较慢
.png)
解决:查询所有的进程,过滤routine不包含某个routine的进程,进行终止
代码:
ClassMethod BatchTerminalProcessQuery()
{ Set Rset = ##class(%ResultSet).%New("%SYS.ProcessQuery:ListPids")
d Rset.Execute()
While Rset.Next() {
s CurrentLineAndRoutine=""
&sql(SELECT CurrentLineAndRoutine INTO :CurrentLineAndRoutine FROM %SYS.ProcessQuery WHERE Pid = :Rset.GetData(1))
continue:CurrentLineAndRoutine'[".WorkQueueMgr"
w CurrentLineAndRoutine,!
s pid=Rset.GetData(1)
s sc= $System.Process.Terminate(pid)
w sc,!
;w $ZU(4,pid,1)
}
d Rset.Close()
}
在当今充满活力的医疗保健行业,获取全面、精简的医疗记录对于做出明智的决策至关重要。人工智能驱动的健康图表应用程序是一个开创性的解决方案,旨在为医生提供一种获取和理解健康数据的有效方式。
主要功能
- 全面的数据检索: 健康图表应用程序通过提取各种健康数据,包括过敏症、病情、手术、免疫接种、药物、家族史、社会史、生命体征和化验结果,超越了传统记录。这种全面的视角可以让人们深入了解患者的健康历程。
.png)
- 通过人工智能增强洞察力:通过利用人工智能的力量,Health Chart 应用程序可以智能处理数据。人工智能引擎将原始信息转化为可操作的洞察,生成健康摘要和风险评估。这不仅节省了医生的宝贵时间,还提高了患者护理质量。
公司介绍:https://www.prairiebyte.com
目标使用者--临床医生
类别--护理协调, 数据可视化, 疾病管理/基层医疗
应用程序类型--SMART ON FHIR应用程序
FHIR 版本--R4
支持的电子病历系统--Cerner、Epic等支持FHIR API的软件系统
Abstractive Health是一款医生人工智能助手,可帮助医生创建最佳病历。我们直接与国家 HIE 和 EHR 集成。我们的医疗摘要可用于门诊、住院和急诊护理,实现临床笔记的自动化,如 SOAP 笔记、进展笔记、护理过渡、ED Provider 笔记和出院摘要。我们使用生成式人工智能和 LLM 来压缩数百页的医疗笔记,从而节省您的时间,让您可以专注于病人护理。
公司介绍:https://www.abstractivehealth.com
目标使用者--临床医生
类别--护理协调, 数据可视化, 人口健康
应用程序类型--SMART ON FHIR应用程序
FHIR 版本--R4
支持的电子病历系统--Allscripts、Athena Health、Cerner、Epic等支持FHIR API的软件系统
安全和隐私政策: https://www.abstractivehealth.com/security-and-privacy
.png)
csp.log日志是这个
嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
🏆 InterSystems 2024 Python 编程大赛 🏆
时间: 2024年7月15日-8月4日(美国东部时间)
奖金池: 14,000美元
.jpg)
如果要让超时功能失效, 在DSN设置查询超时为disabled:
Windows Control Panel > Administrative Tools > Data Sources (ODBC) > System DSN configuration
如果勾选了Disable query timeout , 超时就会失效.
如果想在应用侧修改,你可以在ODBC API 层设置:在连接数据源之前,调用ODBC SQLSetStmtAttr功能设置SQL_ATTR_QUERY_TIMEOUT 属性
如果您想在InterSystems 产品启动时执行一个操作系统可执行文件,命令或者程序,可以在SYSTEM^%ZSTART routine里面写明流程 ( %ZSTART routine在 %SYS 命名空间里面创建).
在 SYSTEM^%ZSTART 里面写代码之前, 请确保他可以在任何情况下能正常工作
如果 ^%ZSTART routine 写的不对,或者没有响应或者发生错误,InterSystems 产品可能会无法启动。
更多信息,请参考一下文档。
About writing %ZSTART and %ZSTOP routines [IRIS]
About writing %ZSTART and %ZSTOP routines
InterSystems 产品里数据 (表、对象、实例数据) 是存在global 变量里的。
每个global 的数据大小可以从管理门户中中点击属性查看Management Portal > System > Configuration > Local Database > Globals page, 然后在global 属性页点击计算大小Calculate Size 按钮。
你可以在终端上调用^%GSIZE 来在命名空间里显示数据大小,方法如下.
流程如下
1. 上传到 FTP server
set tmpfile="c:\temp\test.jpg"
set ftp=##class(%Net.FtpSession).%New()
// connect to FTP server
do ftp.Connect("","<username>","<password>")
// set transfer mode to BINARY
do ftp.Binary()
// Move to the directory to upload
do ftp.SetDirectory("/temp/upload")
// Prepare a stream of files to upload
set file=##class(%File).%New(tmpfile)
do file.Open("UK\BIN\")
// upload file
// 1st argument: File name to create at upload destination
// 2nd argument: File stream to upload
do ftp.Store("test.jpg",file)
// Logout from ftp server
do ftp.👉即日起积极参与社区互动,就有机会获得赠书《AI医疗革命》(中文版)!
✓ 六月有 38 位新成员加入
✓ 截至目前共发布了 2,123 篇帖子
✓ 截至目前共有 1,877 位成员加入
在 OEX 最近一次编程竞赛之后,我有一些令人惊讶的发现。
几乎所有的应用程序都是基于人工智能与预制 Python 模块的结合。
但深入研究后发现,所有示例都使用了 IRIS 的相同技术组件。
从 IRIS 的角度来看,无论是搜索文本还是搜索图像或其他模式都是一样的。 其底层基本都是一样的。
这让我想起了我家里的情况。我的妻子和女儿对家里的大量裙子、衬衫和其他衣服的信息进行了整理。
但无论如何进行整理、分类、归档,我依然通过和我的妻子和女儿说话,来确定我的穿着。
无论怎样包装,其结果都是如此。
回到这次竞赛比赛:
同样的 IRIS 技术内容,却有很多花哨的包装。
每个人都在同一条高速公路上奔跑。没有人提到它有什么限制。
于是我试着深入挖掘,找出新数据类型 VECTOR 的使用限制。
所有向量都有两个基本参数
- 静态 DATATYPE:"整型integer"(或 "int")、"double"、"十进制decimal"、"字符串 "和 "时间戳"。
- 半动态 LEN(gth): > 0 通常也称为 POSITION;纯整数。
这个 LEN/POSITION 参数就相当于vector的数学维度。
当然,在爱因斯坦的宇宙中,根据他的相对论,你可能只需要 4 个维度或更少。
即使是 60 年代提出的宇宙弦理论也没有超过 11.
迄今为止,我看到的大多数使用向量vector的示例,将它只作为 SQL 中的一种功能,尤其是围绕 VECTOR_Search 的 3 个函数。
* TO_VECTOR()
* vector_dot_product ()
* vector_cosine ()
在 iris-vector-search 演示包中隐藏着一个非常有用的摘要。
从那里,你可以通过多个链接找到所需的一切。
我还缺少更多的 VECTOR 方法,于是在 Idea Portal 上提出了相关请求。
接着,我想起每个 SQL 方法或存储过程都有一堆 ObjectScript 代码。
于是我开始搜索,下面就是我的研究的一些总结:
%Library.Vector 是对新数据类型的核心描述
这是一种复杂的结构,就像对象或 %DynamicObjects 或 $Bit Expressions 一样,需要特定的方式去访问。
我们还可以看到 2 个必备参数:
* DATATTYPE - 一旦设置就不能更改。 可接受的类型: "整数integer"(或 "int")、"双精度浮点double"、"十进制decimal"、"字符串 "和 "时间戳"。
* LEN >0 时,可以增长,但绝对不能缩小
$vector() / $ve() 是矢量访问的基本方法
* 设置矢量数据 >>> SET $VE(. . .
你可以使用List query 对 %SYS.Audit 查询审计日志,代码如下:
Set##class有两篇很棒的有关删除消息关联的孤儿记录的内容以及如何处理孤儿的问题的WRC议最佳实践文章Ensemble Orphaned Messages | InterSystems Developer Community | Best DeleteHelper - A Class to Help with Deleting Referenced Persistent Classes (intersystems.com)
本文并不是要取代 Intersystems 专业人员撰写的这些文章,而是要在此基础上介绍我们如何利用这些信息和其他讨论(包括我们实际清理这些数据的方法)来帮助我们的数据库变得更加紧凑。
我们的备份越来越多。年初的时候,我们遇到过一台服务器被强制故障的情况,需要进行还原。由于数据库庞大,即使复制这个数据库也需要很长时间,更不用说还原重建shadow服务器了。因此,我们不得不决定最终解决这一增长问题。最初的原因已经确定
理解你的数据您在数据库中存储了哪些数据?您是否有必须保存在记录表中的数据?
通过 REST API 将前端 React 应用程序与 IRIS 数据库等后端服务集成,是构建健壮网络应用程序的强大方法。但是,开发人员经常遇到的一个障碍是跨源资源共享(CORS)问题,由于网络浏览器强制执行的安全限制,该问题可能会阻止前端访问后端的资源。在本文中,我们将探讨在将 React Web 应用程序与 IRIS 后端服务集成时如何解决 CORS 问题。
我们首先定义一个名为 Patients 的简单Schema:
Class Prototype.DB.Patients Extends %Persistent [ DdlAllowed ]
{
Property Name As %String;
Property Title As %String;
Property Gender As %String;
Property DOB As %String;
Property Ethnicity As %String;
}
您可以在表中插入一些虚假数据进行测试。我个人认为 Mockaroo 在创建假数据时非常方便。它可以让你把虚拟数据下载为 .csv 文件,直接导入管理门户。
然后,我们定义几个 REST 服务
Class Prototype.DB.RESTServices Extends %CSP.REST
{
Parameter CONTENTTYPE = "application/json";
XData UrlMap [ XMLNamespace = "http://www/intersystems.com/urlmap" ]
{
想象一下那个场景。您正在 Widgets Direct 愉快地工作,这是互联网上首屈一指的小部件和小部件配件零售商。您的老板有一些毁灭性的消息,一些客户可能对他们的小部件不太满意,我们需要一个帮助台应用程序来跟踪这些投诉。为了让事情变得有趣,他希望代码占用非常小,并挑战您使用 InterSystems IRIS 以少于 150 行代码交付应用程序。这可能吗?
免责声明:本文记录了一个非常基本的应用程序的构建,为了简洁起见,省略了安全性和错误处理等细节。该应用程序仅供参考,不得用于任何生产应用。本文使用IRIS 2023.1作为数据平台,并非所描述的所有功能在早期版本中都可用
我们首先定义一个新的干净的命名空间 - 带有代码和数据数据库。虽然所有内容都可以位于 1 个数据库中,但将它们拆分以便于数据刷新。
.png)
我们的帮助台系统需要 3 个基本类:一个 Ticket 对象,它可以包含用于记录员工顾问 UserAccount 和客户联系人 UserAccount 之间交互的操作。让我们用一些基本属性来定义它们:
19 行代码,我们就有了完整的数据模型!我们将 2 个类设置为 Persistent,以便将它们保存到数据库中,并且还继承自 %JSON.Adapter,这使我们能够非常轻松地以 JSON 格式导入和导出对象。
要求:
熟练掌握:InterSystems Cache, PHP, API开发. 熟练英语沟通,工作时间能够适应美国时区
工作时间--即刻开始,兼职,-20-30 小时/周,持续1-2个月;
关于我们: 加州IT咨询公司Redline Coders
感兴趣直接联系英文社区:https://community.intersystems.com/node/568846
“一根筷子易折断,十根筷子抱成团”,这句话在青岛大学附属医院(以下简称“青大附院”)的医院信息系统升级换代中得到了淋漓尽致的体现。
.png) 是需要vpn吗
是需要vpn吗
