新增
大家好,
你是否曾希望你的电子健康记录(EHR)能具备思考能力?不仅仅是显示数据,也不仅仅是触发警报。而是能够真正阅读病历、综合临床指南进行分析,并根据临床医生的单条信息,向系统生成结构化的转诊医嘱。
在本文中,我将向大家展示如何创建您自己的定制临床AI助手。
🏥 关于 iris-fhir-agents 应用
iris-fhir-agents是一个完全基于 InterSystems IRIS for Health 构建的多智能体临床 AI 平台
大家好,
你是否曾希望你的电子健康记录(EHR)能具备思考能力?不仅仅是显示数据,也不仅仅是触发警报。而是能够真正阅读病历、综合临床指南进行分析,并根据临床医生的单条信息,向系统生成结构化的转诊医嘱。
在本文中,我将向大家展示如何创建您自己的定制临床AI助手。
iris-fhir-agents是一个完全基于 InterSystems IRIS for Health 构建的多智能体临床 AI 平台

大家好,
在本文中,我将介绍我的应用程序iris-fhir-agents 这是一个由 InterSystems IRIS for Health 驱动的多智能体临床 AI 平台。该平台包含用于分诊、专科会诊、用药安全以及 FHIR 服务器探索的智能体——所有功能均基于 IRIS Vector Search RAG 构建。 平台包含一个无代码代理构建器,让您无需编写任何代码即可设计和部署自定义临床代理。
嗨,开发人员、
我们很高兴地宣布新一届 InterSystems 在线编程竞赛即将开始:
🏆InterSystems 开发者竞赛:面向 FHIR 的AI Agent🏆
持续时间: 2026 年 5 月 25 日至 6 月 14 日(美国东部时间)
奖金:12,000 美元

主题
开发一个可在互操作性 FHIR 解决方案中调用的AI Agent。
实施建议任务可获得 5 个额外积分 (!) - 每个应用程序一次
智能患者摘要生成器
功能:从 FHIR 数据中创建简洁、便于临床医生使用的患者摘要,包括病情、用药、过敏症、最近就诊情况、化验和护理计划。
FHIR 资源:Patient, Condition, MedicationRequest, AllergyIntolerance, Observation, Encounter, CarePlan.
平台功能:FHIR API、FHIR SQL Builder、AI Hub。
1-2 周 MVP: 挑选一名患者,调取最近的 FHIR 资源,生成:
加分项:为不同角色生成不同摘要:ED 医生、护理经理、患者或家庭护理人员。
在上一篇文章中, 我谈到了(iris-copilot),这是一种在不久的将来,任何人类语言都可以成为任何机器、系统或产品的编程语言的愿景。它的代理运行程序实际上就是在使用这种所谓的第三代Agent。为了自己的方便,我也想保留/分享一份关于它是什么的详细记录。我在最近的谈话中多次提到过这个问题,所以也许值得一记。
我们正在见证人工智能代理的世代飞跃,这几乎是巧合。
在过去的四年里,人工智能行业已经经历了三代不同的代理技术--每一代都不仅仅代表着渐进式的改进,而是我们对人工智能系统在实际工作中的思考模式的根本性转变。第一代为我们提供了信息(information)。第二代给了我们协调(orchestration)。第三代技术--我称之为 "线束工程"(Harness Engineering)--给我们带来了质的不同:信任。
这种转变最明显的证据是什么?这是在一个 npm 软件包中意外发布的。
2026 年 3 月 31 日,Anthropic 发布了 @anthropic-ai/claude-code v2.1.88 的例行 npm 更新。一个丢失的 .npmignore
持续训练(CT)流水线将基于特定时间点可用数据,通过数据科学实验开发出的机器学习(ML)模型规范化。它不仅为模型部署做好准备,还支持在新数据可用时进行自主更新,同时具备用于审计目的的稳健性能监控、日志记录和模型注册功能。
InterSystems IRIS 已经提供了支持此类流水线所需的几乎所有组件。然而,缺少一个关键要素:标准化的模型注册工具。在本文中,我将介绍一种结合 IRIS 优势与开源 AI 工程平台 MLflow 的方法。它们共同作为构建有效持续训练(CT)流水线的互补工具。
本仓库中的实现利用了 MLflow 的内置配置来存储 SHAP 解释器,以提供对相应模型预测结果的解释,包括随机森林(Random Forest)、XGBoost、神经网络等“黑盒”复杂模型。
**演示视频**:https://youtu.be/qLdc4jhn83c
---
该 CT 流水线模块背后的理论基于 Google 在相关文章中定义的 MLOps 1 级行业标准。每个组件的实现都利用了 IRIS 和 MLflow 的最佳特性(如下图所示,红色部分突出显示):
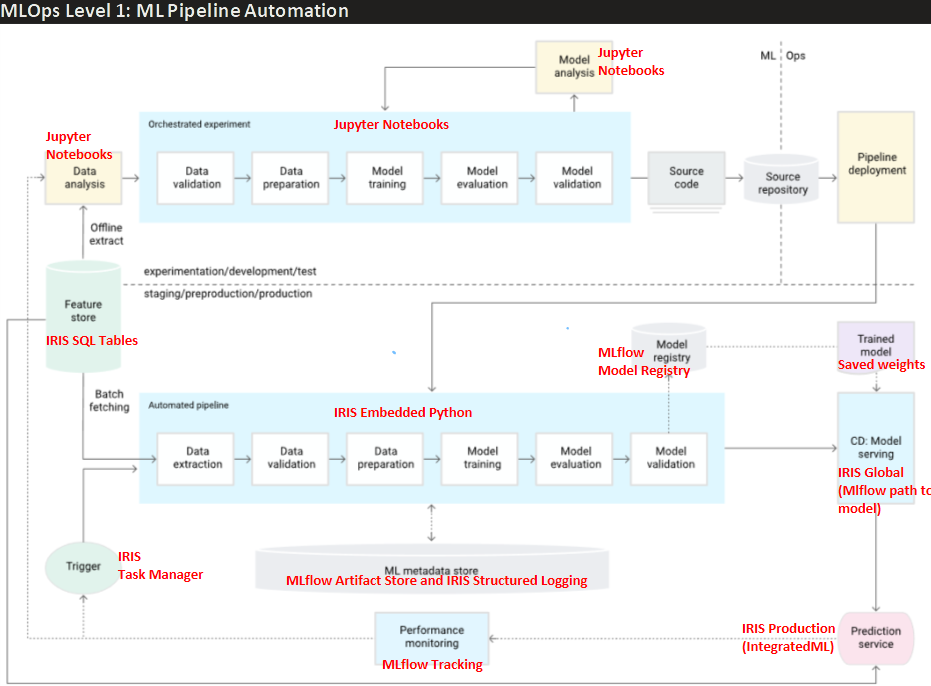
对于那些刚接触 CT 流水线的人来说,上图描述了数据科学项目中传统的实验阶段(上半部分“实验/开发/测试”,通常在 Jupyter Notebook 中进行)如何转化为生产级模型部署。
我们一开始并没有大的人工智能战略。
我们有一个传统的 InterSystems Caché 2018 应用程序、大量老旧的业务逻辑和一个实际需求:构建一个新的用户界面并改进已运行多年的代码。起初,我认为人工智能编码代理只能帮助完成一小部分工作。也许是一些模板、系统周围的一些 REST 工作,以及帮助阅读旧的 ObjectScript。
但实际上,它的作用远不止这些。
当我们开始认真使用它时,我们意识到它可以跨越庞大的代码库,理解模式,提出重构建议,并帮助我们以比我预期快得多的速度实现 Caché 的现代化。但这只是在开始时经历了一段令人沮丧的时期之后才发生的。
真正的挑战不是获得代码建议。而是教会代理我们的 Caché 环境如何实际运行。
在进行任何技术工作之前,我们必须回答一个安全问题。
我们不能将企业资源规划代码和内部业务逻辑直接发送给公共人工智能服务,并寄希望于最好的结果。这样做永远无法通过严格的安全审查。
亚马逊 Bedrock 改变了我们的想法。我们的服务器、数据和开发环境已经在 AWS 中,因此 Bedrock 可以很自然地融入我们已经信任和管理的云环境。我们可以使用该模型,同时将流量、访问控制和周边安全控制保持在我们已经在使用的 AWS 框架内。
关键词 氛围编码(Vibe coding), Windsurf, IRIS, TIE
迄今为止,有人没有尝试过 "氛围编码(vibe coding) "吗?
即使仅仅在三年前,如果有人问
你可能会大笑一声,尽量不生气,找把椅子坐下来,开始计算光是这些分析/SoW/需求/设计/测试/服务文档就需要多少人*日或人*周,以及实际工程工作。
然而,随着基础模型的飞跃和进步,今天的情况肯定会变得更加现实。
我也希望了解其他人是如何使用它的。 以下只是我自己匆忙写下的随笔。
大家好
我将为大家提供一个快速小技巧,教大家如何实施一个 AI Agent来搜索集成到 Teams 中的 Intersystems 文档。
是的,我知道文档页面有自己的人工智能搜索引擎,而且相当有效,但这样我们就能更快地访问,尤其是如果 Teams 是贵公司的企业工具。
您还可以创建另一个 AI Agent来搜索在开发者社区中发布的文章(该社区也有自己的集成人工智能搜索引擎)。
社区朋友们好,
传统的基于关键词的搜索方式在处理具有细微差别的领域特定查询时往往力不从心。而向量搜索则通过语义理解能力,使AI智能体能够根据上下文(而非仅凭关键词)来检索信息并生成响应。
本文将通过逐步指导,带您创建一个具备代理能力的AI RAG(检索增强生成)应用程序。
1. Create Agent Tools 添加文档摄取功能
Implement Document Ingestion: Automated ingestion and indexing of documents
1.1 - 以下是实现文档摄取工具的代码:
def ingestDoc(self):
#Check if document is defined, by selecting from table
#If not defined then INGEST document, Otherwise back
embeddings = OpenAIEmbeddings()
#Load the document based on the fle type
loader = TextLoader("/irisdev/app/docs/IRIS2025-1-Release-Notes.txt", encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
#COLLECTION_NAME = "rag_document"
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
db = IRISVector.from_documents(embedding=embeddings,documents=texts, collection_name = self.COLLECTION_NAME, connection_string=self.CONNECTION_STRING,)向量搜索智能体(Vector Search Agent)能够自动完成文档的摄取(ingest)与索引构建(index), 该新功能在InterSystems IRIS 2025.1的数据资源文件夹里) 至 IRIS 向量存储, 只有当数据尚未存在时,才执行该操作。.png)
运行以下查询以从向量存储中获取所需数据:
SELECT
id, embedding, document, metadata
FROM SQLUser.AgenticAIRAG
1.2 - 实现向量搜索功能
以下代码为智能体提供了搜索能力:
def ragSearch(self,prompt):
#Check if collections are defined or ingested done.
# if not then call ingest method
embeddings = OpenAIEmbeddings()
db2 = IRISVector (
embedding_function=embeddings,
collection_name=self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
docs_with_score = db2.similarity_search_with_score(prompt)
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#Generate Template
template = f"""
Prompt: {prompt}
Relevant Docuemnts: {relevant_docs}
"""
return template
分流代理处理传入的用户查询,并将其委托给矢量搜索代理,后者执行语义搜索操作,以检索最相关的信息。
随着 IRIS 中向量数据类型和向量搜索功能的引入,应用程序的开发正在开启一个充满各种可能性的全新世界,其中一个应用程序示例是我最近在巴伦西亚卫生局的一次公开竞赛中看到的应用程序,他们要求提供一种工具,能够使用 AI 模型协助进行 ICD-10 编码。
我们如何实现与所要求的应用程序类似的应用程序? 我们来看看需要什么:
IRIS 为我们提供哪些功能来满足上述需求?
我们只需要看看开发的示例:
在本文中,您可以访问开发的应用程序,在后续文章中,我们将详细了解如何实现每个功能,包括模型的使用、向量的存储和向量搜索的使用。
Hi社区成员们!
你可能已经知道了,, 我们的 Developer Community AI(开发者社区AI) 已经运行一个多月了 🎉 我们希望你能够出于好奇来尝试一下 😁 如果你还没试过,那就试试吧!无论如何,由于它仍在测试阶段,我们非常有兴趣了解你对它的看法,也很期待听到你的想法和经验。

我们重视你为此付出的时间和精力,所以将随机赠送一个可爱的奖品给愿意分享自己想法的社区成员。要参加此抽奖活动,你需要遵循以下准则:
关键字:PyODBC,unixODBC,IRIS,IntegratedML,Jupyter Notebook,Python 3
几个月前,我简单谈到了关于“将 Python JDBC 连接到 IRIS”的话题。我后来频繁提起它, 因此决定再写一篇 5 分钟的笔记,说明如何“将 Python ODBC 连接到 IRIS”。
在 Windows 客户端中通常很容易设置 ODBC 和 PyODBC,不过我每次在 Linux/Unix 风格的服务器中设置 unixODBC 和 PyODBC 客户端时,都会遇到一些麻烦。
有没有一种简单连贯的方法,可以不安装任何 IRIS,在原版 Linux 客户端中让 PyODBC/unixODBC 针对远程 IRIS 服务器运行?
最近,我花了点时间研究如何在 Linux Docker 环境的 Jupyter Notebook 中从头开始让一个 PyODBC 演示运行起来, 记录下这篇稍微有些繁琐的笔记,以供日后快速参考。
这篇笔记将涉及以下组件:
Abstractive Health是一款医生人工智能助手,可帮助医生创建最佳病历。我们直接与国家 HIE 和 EHR 集成。我们的医疗摘要可用于门诊、住院和急诊护理,实现临床笔记的自动化,如 SOAP 笔记、进展笔记、护理过渡、ED Provider 笔记和出院摘要。我们使用生成式人工智能和 LLM 来压缩数百页的医疗笔记,从而节省您的时间,让您可以专注于病人护理。
公司介绍:https://www.abstractivehealth.com
目标使用者--临床医生
类别--护理协调, 数据可视化, 人口健康
应用程序类型--SMART ON FHIR应用程序
FHIR 版本--R4
支持的电子病历系统--Allscripts、Athena Health、Cerner、Epic等支持FHIR API的软件系统
安全和隐私政策: https://www.abstractivehealth.com/security-and-privacy
Hi 开发者们,
我们非常高兴地邀请大家参加新的 InterSystems 在线编程竞赛,此次编程大赛关注生成式AI(GenAI), 向量搜索(Vector Search )与机器学习(Machine Learning)!
🏆 InterSystems 编程大赛:Vector Search, GenAI 与 ML 🏆
时间:2024年4月22日 - 5月19日 (美国东部时间)
奖金池: $14,000
.jpg)

人工智能不仅限于通过带有说明的文本生成图像,或通过简单的指示创建叙事。
您还可以制作图片的变体,或为已有图片添加特殊背景。
此外,您还可以获得音频转录,无论其语言和说话者的语速如何。
让我们来分析一下文件管理是如何工作的。
.png)
生成人工智能是能够使用生成模型生成文本、图像或其他数据的人工智能,通常是响应提示。生成式人工智能模型学习输入训练数据的模式和结构,然后生成具有相似特征的新数据。
生成式人工智能是能够生成文本、图像和其他类型内容的人工智能。它之所以成为一项出色的技术,是因为它使人工智能民主化,任何人都可以使用它,只需文本提示,即用自然语言编写的句子。
大型语言模型如何工作
2024年3月26日,InterSystems数据平台全球主管Scott Gnau发文,宣布InterSystems IRIS数据平台新增了向量搜索(vector search)功能。
本文作者为Scott Gnau,InterSystems数据平台全球主管。

这是 IRIS 与 RAG(检索增强生成)示例的一个简单演示。
后端是使用 IRIS 和 IoP用 Python 编写的,LLM 模型是 orca-mini 并由 ollama 服务器提供。
前端是用 Streamlit 编写的聊天机器人。
RAG 是 Retrieval Augmented Generation(检索增强生成)的缩写,它带来了使用带有知识库的 LLM 模型(GPT-3.
人工智能(AI)最近受到广泛关注,因为它可以改变我们生活的许多领域。更好的计算机能力和更多数据帮助人工智能完成了许多惊人的事情,例如改进医学测试和制造自动驾驶汽车。人工智能还可以帮助企业做出更好的决策,提高工作效率,这也是人工智能越来越流行和广泛应用的原因。如何将 OpenAI API 调用集成到现有的 IRIS 互操作性应用程序中?
什么是非结构化数据?
非结构化数据是指缺乏预定义数据模型或组织的信息。与数据库中具有清晰结构(例如表和字段)的结构化数据相比,非结构化数据缺乏固定的模式。此类数据包括文本、图像、视频、音频文件、社交媒体帖子、电子邮件等。
为什么来自非结构化数据的见解很重要?
根据 IDC(国际数据公司)的报告,预计到 2025 年,全球 80% 的数据将是非结构化的,这将成为 95% 企业的重大担忧。 福布斯文章
人工智能世界如何解决这个问题?
在人工智能领域,生成式人工智能在为非结构化数据提供解决方案方面发挥着至关重要的作用。它擅长从文本/图像/视频中提取有价值的信息、文本摘要和处理文档等任务。
Intersystems 非结构化数据解决方案
Intersystems IRIS 提供了一种称为“SQL 文本搜索”的特殊解决方案,用于搜索非结构化数据。此功能有助于对多种语言的非结构化文本数据进行语义上下文搜索。
使用 SQL 文本搜索有什么优点?
快速搜索: InterSystems IRIS SQL 搜索利用优化的索引生成快速导航大量数据,避免对数据本身进行顺序搜索。
单词感知搜索:与基本字符串搜索不同,SQL 搜索依赖于文本中的语义结构,以单词为基本单位。这种方法最大限度地减少了嵌入字符串或跨越两个单词的字符串引起的误报。
实体感知搜索: SQL 搜索考虑语义关系以将多个单词分组为实体。
大型语言模型(例如 OpenAI 的 GPT-4)的发明和普及掀起了一波创新解决方案浪潮,这些解决方案可以利用大量非结构化数据,在此之前,人工处理这些数据是不切实际的,甚至是不可能的。此类应用程序可能包括数据检索(请参阅 Don Woodlock 的 ML301 课程,了解检索增强生成的精彩介绍)、情感分析,甚至完全自主的 AI 代理等!
在本文中,我想演示如何使用 IRIS 的嵌入式 Python 功能直接与 Python OpenAI 库交互,方法是构建一个简单的数据标记应用程序,该应用程序将自动为我们插入IRIS 表中的记录分配关键字。然后,这些关键字可用于搜索和分类数据,以及用于数据分析目的。我将使用客户对产品的评论作为示例用例。
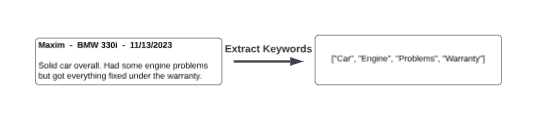
让我们首先创建一个 ObjectScript 类,该类将定义客户评论的数据模型。为了简单起见,我们将只定义 4 个 %String 字段:客户姓名、产品名称、评论正文以及我们将生成的关键字。该类应该扩展%Persistent,以便我们可以将其对象保存到磁盘。
ClassExtends%Persistent大家好,
与我们一起参加 8 月 31 日上午 10 点(美国东部时间)在线开发者圆桌会议,讨论医疗保健中的生成式 AI 使用案例。
学习医疗保健领域的用例+参考架构,并观看关于大语言模型的Demo演示。我们将像往常一样有时间进行问答和公开讨论。
演讲者: @Nicholai Mitchko ,InterSystems 解决方案合作伙伴销售工程师经理
背景: Nicholai 在 InterSystems 管理着一支由 10 名解决方案工程师组成的团队,帮助医疗保健公司大规模设计、开发和交付解决方案。在业余时间,Nicholai 致力于大型语言模型的研究,包括开发自己的模型,这些模型出现在Huggingface OpenLLM 排行榜上。

.png)
FHIR 通过提供标准化数据模型来构建医疗保健应用程序并促进不同医疗保健系统之间的数据交换,彻底改变了医疗保健行业。由于 FHIR 标准基于现代 API 驱动的方法,因此移动和 Web 开发人员更容易使用它。然而,与 FHIR API 交互仍然具有挑战性,尤其是在使用自然语言查询数据时。
隆重推出FHIR - AI 和 OpenAPI 链应用程序,该解决方案允许用户使用自然语言查询与 FHIR API 进行交互。该应用程序使用OpenAI 、 LangChain和Streamlit构建,简化了查询 FHIR API 的过程并使其更加用户友好。
OpenAPI 规范(以前称为 Swagger,目前是OpenAPI Initiative的一部分)已成为软件开发领域的重要工具,使开发人员能够更有效地设计、记录 API 并与 API 交互。 OpenAPI 规范定义了一种标准的机器可读格式来描述 RESTful API,提供了一种清晰一致的方式来理解其功能并有效地使用它们。
在医疗保健领域,FHIR 成为数据交换和互操作性的领先标准。为了增强FHIR的互操作能力, HL7正式记录了FHIR OpenAPI规范,使开发人员能够将FHIR资源和操作无缝集成到他们的软件解决方案中。
这是个实验项目,使用OpenAI API与FHIR资源和Python相结合来回答医疗行业的用户提问。
生成式人工智能,如OpenAI上提供的LLM模型, 已被证明在理解和回答高层次问题方面具有显著能力。他们使用大量的数据来训练他们的模型,因此他们可以回答复杂的问题。
他们甚至可以使用编程语言,根据提示创建代码 --我不得不承认,让我的工作自动化的想法让我感到有些焦虑。但到目前为止,似乎这是人们必须要习惯的事情,不管你喜不喜欢。所以我决定做一些尝试。
这个项目的主要想法是在我读到这篇文章关于ChatARKit项目时产生的。这个项目使用OpenAI的API来解释语音命令,在智能手机摄像头的实时视频中渲染3D物体--非常酷的项目。而且,这似乎是一个热门话题,因为我发现最近有一篇论文遵循类似的想法。
让我最担心的是使用ChatGPT对AR进行**编程。由于有一个开放的github repo,我搜索了一下,发现作者是如何使用ChatGPT生成代码的。这种技术被称为提示工程Prompt Engineering--这是维基百科关于它的文章,或者这两个更实用的参考资料: 1和2。
所以我想--为什么不结合FHIR和Python试试类似的东西?
![]()
众所周知,人工智能的世界已经到来,每个人都想利用它为自己谋取利益。
有许多平台通过订阅或私人免费提供人工智能服务。然而,由于在计算领域产生的大量“噪音”而脱颖而出的是 Open AI,这主要归功于其最著名的服务:ChatGPT 和 DALL-E。
Open AI 是一个非营利性人工智能研究实验室,由 Sam Altman、Ilya Sutskever、Greg Brockman、Wojciech Zaremba、Elon Musk、John Schulman 和 Andrej Karpathy 于 2015 年发起,旨在促进和开发友好的人工智能,造福于人类所有的。
自成立以来,这些人已经发布了一些令人着迷的产品,如果用于良好的目的,可能会成为真正强大的工具。然而,与任何其他新技术一样,它们构成了可能被用来犯罪或作恶的威胁。
我决定测试 ChatGPT 服务,并询问它人工智能的定义是什么。我收到的答案是在互联网上找到的概念的积累,并以人类会回应的方式进行了总结。
简而言之,人工智能只能使用用于训练它的信息进行回复。利用其内部算法和训练期间输入的数据,它可以撰写文章、诗歌,甚至计算机代码片段。
人工智能将对这个行业产生重大影响,并最终彻底改变一切……。也许对人工智能将如何影响我们的未来的期望被夸大了,所以我们应该开始为了共同利益而正确地使用它。
大家好!
InterSystems Grand Prix 2023 结合了 InterSystems IRIS 数据平台的所有主要功能!
因此,我们邀请您使用以下功能并收集额外的技术奖励,以帮助您赢得奖品!
如下:
本文是 SqlDatabaseChain 的简单快速入门(我所做的)。
希望大家会感兴趣。
非常感谢:
sqlalchemy-iris 作者@Dmitry Konnov Maslennikov
您的项目使我的试验变得可能。
文章脚本使用 openai API,因此请注意不要在外部共享您不打算共享的表信息和记录。
如果需要,可以插入本地模型。
mkdir chainsql cd chainsql python -m venv . scripts\activate pip install langchain pip install wget # Need to connect to IRIS so installing a fresh python driver python -c "import wget;url='https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/main/DB-API/intersystems_irispython-3.2.0-py3-none-any.whl';wget.download(url)" # And for more magic pip install sqlalchemy-iris pip install openai set OPENAI_API_KEY=[ Your OpenAI Key ] python
嗨社区!
想与您分享我在Telegram中使用GPT创建“我自己的”聊天的练习。
这个应用需要用到 Open Exchange 上的两个组件:@Nikolay Solovyev 的Telegram Adapter和@Kurro Lopez的IRIS Open-AI 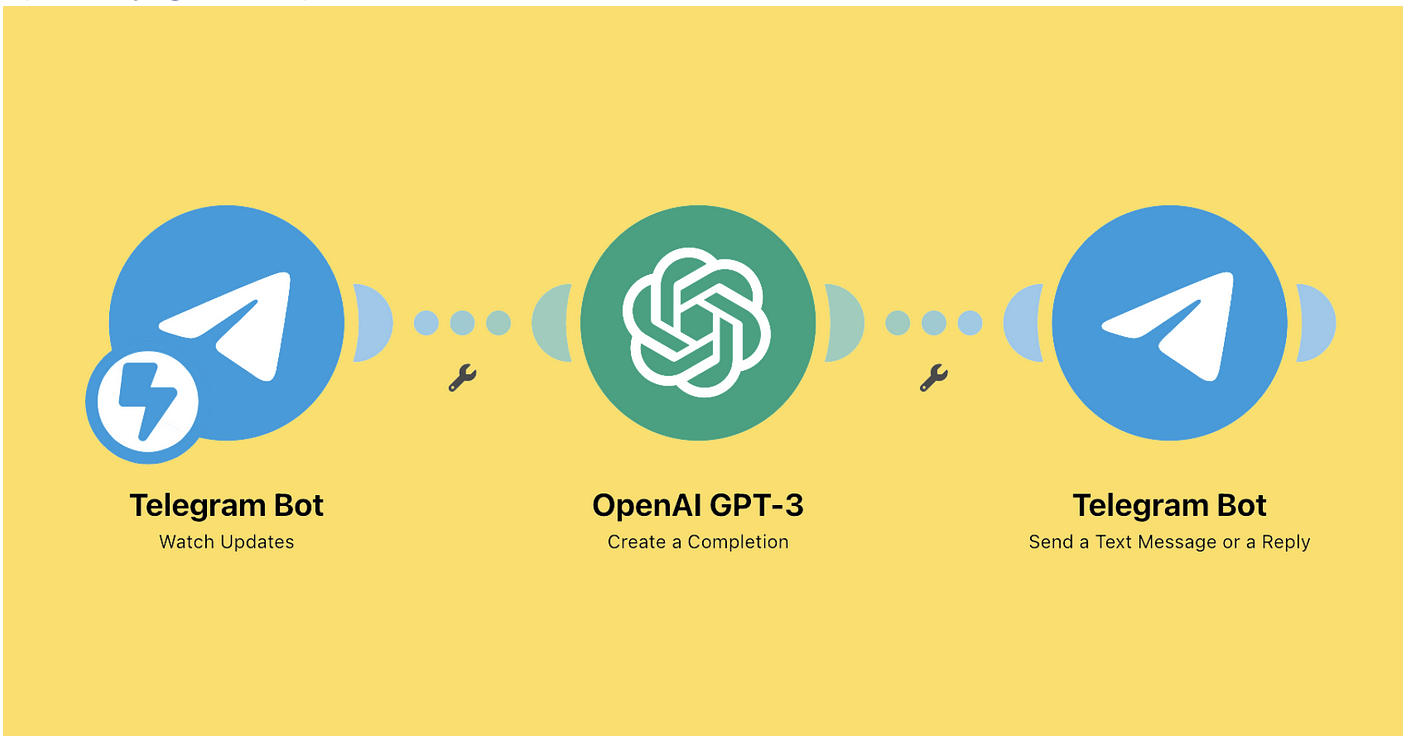
因此,通过此示例,您可以在 Telegram 中使用 ChatGPT 设置自己的聊天。
让我们看看如何让它发挥作用!
最近几个月,大型语言模型GPT正在激起一些现象。因此,上周末我不可避免地也在玩 ChatGPT,以探究它是否会成为我正在敲打的一些基于 BERT 的“传统”AI 聊天机器人的补充,或者更确切地说,它是否会淘汰它们。
玩的时候脑子里冒出一个念头。通过略微理论化或哲学化,最终互操作性标准(如 HL7 和 FHIR 等)是一种“语言”,对吗? HL7 有自己的语法、规则、词汇甚至方言——每个系统都有自己的语调。这就是为什么当一台机器与另一台机器对话时,它们需要翻译器(例如 DTL 转换)来实现相互理解。
所以环顾四周,似乎一切都是语言:编码是语言:python,javascript和COS也是语言。 HL7、FHIR 甚至 XML 或 JSON 都是语言,只是它们比自然语言更结构化,那么 GPT 应该更容易上手吗?
那么,我们可以从简单地重用 GPT 的预训练编码语言模型来模拟 DTL 开始吗?我们还没有进行调整,以下是初步结果:
输入:
##### Translate this function from HL7 V2.8 ADT_A01 to HL7 V2.4 ADT_A05
### HL7 V2.8 ADT_A01
MSH|^~\&|ADT1|GOOD HEALTH HOSPITAL|GHH LAB, INC.|GOOD HEALTH HOSPITAL|198808181126|SECURITY|ADT^A01^ADT_A01|MSG00001|P|2.8||
EVN|A01|200708181123||
PID|1||PATID1234^5^M11^ADT1^MR^GOOD HEALTH HOSPITAL~123456789^^^USSSA^SS||EVERYMAN^ADAM^A^III||19610615|M||C|2222 HOME STREET^^GREENSBORO^NC^27401-1020|GL|(555) 555-2004|(555)555-2004||S||PATID12345001^2^M10^ADT1^AN^A|444333333|987654^NC|
NK1|1|NUCLEAR^NELDA^W|SPO^SPOUSE||||NK^NEXT OF KIN
PV1|1|I|2000^2012^01||||004777^ATTEND^AARON^A|||SUR||||ADM|A0|
### HL7 V2.4 ADT_A05
几周前我尝试了 OpenAI GPT 的编码模型,看看它是否可以在医疗保健系统之间进行一些消息转换。它肯定可以,在相当大的程度上。
已经将近 3 周了,对于 ChatGPT 来说是很长很长的时间,所以我想知道它现在成长得有多快,以及它是否可以为我们做一些集成工程师的工作,例如它是否可以创建一个 InterSystems COS DTL将 HL7 转换为 FHIR 信息?
在不到一两分钟的时间内,我立即得到了一些答案。
首先我想测试一下我是在和它背后的正确“人”说话
问题一:如何将HL7 V2.4报文转为FHIR STU3?
ChatGPT:
将 HL7 V2.4 消息转换为 FHIR STU3 涉及多个步骤,因为这两个标准具有不同的数据模型和结构。以下是该过程的高级概述: