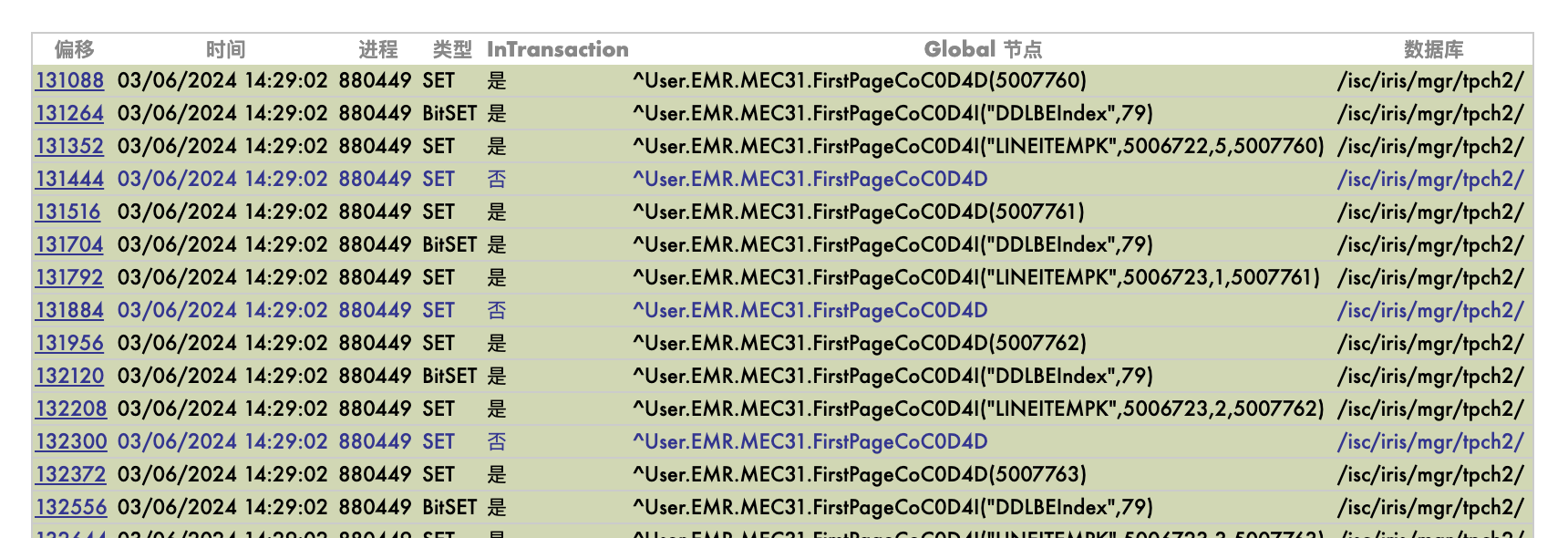
Caché/IRIS的特点是运行Global的修改,而这个修改和SQL是无关的,因此非常容易出现数据库表数据完整性的问题,也就是表中的数据是不是符合定义的表约束。
这样的情况非常常见。有些是人为的对Global的错误修改, 有些是应用系统的事务性管理写的不对,造成事务回滚的时候破坏了索引的完整性。无论什么原因,只要使用Global操作,破坏SQL的完整性非常难以避免。结果就是SQL查询给出错误结果。
最简单的解决方法就是执行“索引检查(Validate Indices)"
我们来做个实验
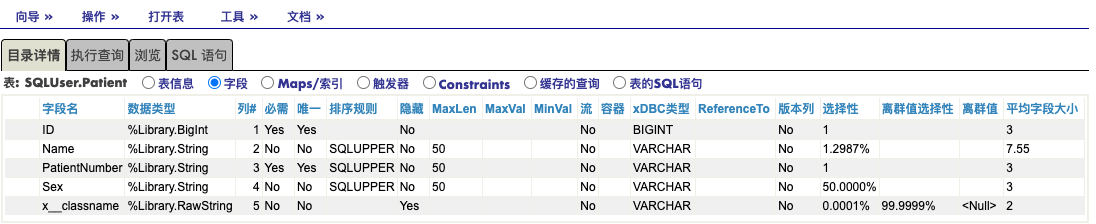
- 先修改一个global: 如下图, 将Patient表的一个记录的SEX字段,从'M'改到‘F'.

运行索引检查, 结果会提示您问题在什么地方。
SAMPLES>do ##class(Patient).%ValidateIndices()
Checking index integrity for class 'User.Patient'
Begin time: 03/19/2024 15:25:43
Verifying data from data map 'IDKEY' is indexed correctly...
Bitmap index 'bidxSex', entry $bit(^User.PatientI("bidxSex"," F",1),4)=0, row is missing from index, it should be 1.
Index 'idxSex', entry ^User.PatientI("idxSex"," F",3) missing.
Data Map evaluation complete, 1000000 rows checked, 2 errors found, elapsed time: 27.344792 seconds
Verifying data from index map "$Patient" is correct...
Index map "$Patient" evaluation complete, 0 errors, elapsed time: 12.026982 seconds
Verifying data from index map idxSex is correct...
Index 'idxSex', entry ^User.PatientI("idxSex"," M",3), data differs for field 'Sex' between data and index map.
Index map idxSex evaluation complete, 1 errors, elapsed time: 12.285592 seconds
Verifying data from index map bidxSex is correct...
Bitmap index 'bidxSex', entry $bit(^User.PatientI("bidxSex"," M",1),4), for row with ID '3', bit is ON, but indexed field value(s) differ from data map value(s).
Index map bidxSex evaluation complete, 1 errors, elapsed time: 13.591468 seconds
Verifying data from index map idxPatientNumber is correct...
Index map idxPatientNumber evaluation complete, 0 errors, elapsed time: 13.646994 seconds
%ValidateIndices is complete, total elapsed time: 41.048687 seconds
SAMPLES>

.png)
.png)

.png)
