IRIS/Caché查询慢,主要原因有以下几个:
- 应用是一个事务型的数据库, 数据模型的设计不适合某些复杂的分析查询
这是慢的原因,不是慢的离谱的原因。数据模型是产品设计的范畴, 这里不讨论, 本文只讨论优化。
- 历史原因,有些表的索引不够优化
虽然还是设计问题,但可以在实施中或者维护中给出优化方案。
- 产品运行中的问题造成的查询效率下降
IRIS/Caché数据平台的一个特点是允许跳过SQL约束,对底层数据的直接修改。坏的代码或者应用可能破坏表数据和表索引的约束,造成SQL性能的下降。维护人员应该知道怎么避免,和处理这样的问题。
- 维护工作缺乏造成
比如Tune Table(调整表), 这是必须做的工作,但可惜很有些项目没有执行过。
还有些其他暂时没想到的原因。我会在以下链接的帖子里和各位分享我的参与的一些知识和经验。这些经验是从一些SQL优化的工作中学到的,包括Caché 2010, 2016, IRIS, HealthConnect/Ensemble的项目。比如在最近的一个IRIS项目中, 我和另一个合作伙伴的工程师将IRIS 2021上的HIS数据库的100个SQL查询的平均查询时间从几十秒降低到几秒, 最慢的查询从50分钟降低到10几秒钟。
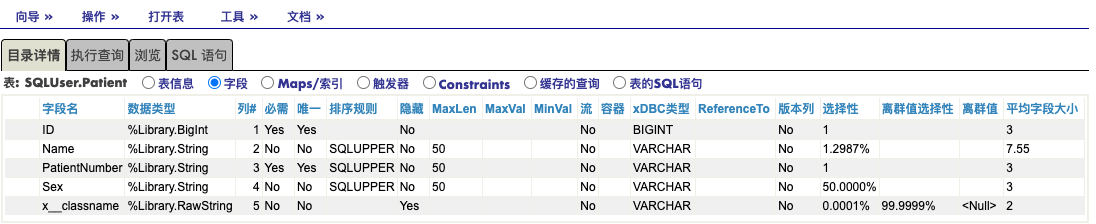
.png)

.png)