新增
大家好👋
我很高兴与大家分享我提交给本届InterSystems .Net、Java、Python 和 JavaScript 竞赛的项目——它叫做IRIStool 和 Data Manager,您可以在InterSystems Open Exchange和我的GitHub 页面上找到它。
大家好👋
我很高兴与大家分享我提交给本届InterSystems .Net、Java、Python 和 JavaScript 竞赛的项目——它叫做IRIStool 和 Data Manager,您可以在InterSystems Open Exchange和我的GitHub 页面上找到它。
今天,我发布了一个新的Open Exchange 软件包,用于直接在 IRIS 中生成合成数据。
当你想制作一个演示应用程序时,找到合适的数据集是一个令人沮丧的过程。也许数据集并不那么重要,但您仍然希望它看起来有点真实,并有几个链接表,可以直接在 IRIS 中使用 -> 的隐式连接。也许您只是想让链接表可以很容易地安装到 IPM 中,用于基准查询,那么这种数据集生成方式就再好不过了。
我选择使用嵌入式 Python 创建数据集,这些数据集可通过自定义配置文件进行配置。这些数据集直接用一个 IRIS 类方法生成,并可使用乘数进行缩放,以创建任意大小的数据集,而无需测量配置。
目前我有四个数据集:
- 金融服务(如银行卡、账户、交易)
- 零售(商店、产品、用户、库存)
- 供应链(产品、销售订单、库存移动)
- 主题公园管理(公园、区域、游乐设施、事故)
我不是这些领域的专家,所以我怀疑它们是否超级准确,而且数据生成使用了 faker 等 python 库,统计加权生成使用了 numpy,所以感觉有点人工合成。
老实说,作为一个我无法投入大量时间的副业项目,这个项目的成功离不开人工智能。我在设计数据集和生成创建数据集的代码时广泛使用了人工智能。我监督、测试了个人使用的案例,并积极参与了项目设计,但代码都是人工智能生成的,我没有仔细审查过数据集的生成过程。
高级工程的定义不在于代码量的多少,而在于策略性地避免代码量。在复杂的集成环境中,倾向于利用通用库来满足每一个细分需求会带来不必要的开销。要实现真正的架构成熟,就必须致力于 "最小化工具"--优先考虑有弹性、经过实战检验的系统实用程序,而不是自定义逻辑。本评估将检查我们的 PGP 加密/解密流水线,以展示如何从应用级库转向操作系统本地授权,从而提高系统的耐用性。
我们当前的 MPHP.HS.PGPUtil 类是一种高摩擦设计。现有的 InterSystems IRIS 业务流程虽然功能强大,但依赖性很强。通过桥接嵌入式 Python 来使用 pgpy 库,我们引入了一个 "重型 "堆栈,需要 Python 运行时、第三方库管理和特定的加密二进制文件。
处理文件通常很简单:打开文件,读取并处理。这种方法非常有效,直到文件碰巧是 Excel 文件。
常见假设
起初,Excel 文件(.xlsx)看起来就像另一个数据文件,行、列和值。因此,我们很自然地认为它可以像 .txt 或 .csv 文件一样被读取。但问题就出在这里。
Excel 文件为何表现不同
关键区别在于数据的存储方式:
-> .txt / .csv - 纯文本,逐行存储。
-> .xlsx - 压缩、结构化格式(非纯文本)
excel 文件实际上不是一个简单的可读行流。从内部看,它是一个包含结构化数据的打包文件,标准文件读取命令无法解释这些数据。
如果把它当作文本文件处理,会发生什么情况?
重要事项 --> 这不是限制,而是工具和文件格式不匹配 。
实用的处理方法
与其只使用基于文本的方法,还有更好的选择、
如果有人曾在 IRIS 中处理过 Excel 文件,或有其他行之有效的方法,请随时分享。)
下面提到几个例子。
大家好!
我们很高兴地宣布推出一项新的实践培训计划:
🧑💻使用 Python 开发 FHIR 应用程序🧑💻

本课程以小组为基础,将开发人员从 FHIR 基础知识带入高级、真实的医疗互操作性解决方案,与典型的行业课程相比,课程内容更深入、更实用,并重点关注使用 InterSystems 技术的生产就绪技能。
第一批学员于 2026 年 2 月 15 日开课 ⚠️ 名额有限(一旦学员满额,报名者将被列入候补名单)。
本课程非常适合以下组织和团队参加
该计划由三个渐进的 5 周模块组成。学员可以参加单个模块的学习,也可以完成为期 15 周的全部课程。
每周包括
直到今年年初,我几乎没怎么做过编程工作——我已经厌倦了它。
在担任多年一线软件工程师和数据科学家后,我在2015年左右陷入了职业倦怠。我转而从事以“外部创新”为主的业务拓展角色,并于2019年加入InterSystems担任产品经理。我怀念编程的创造性,但并不怀念其中的枯燥乏味。无休止的样板代码编写、调试和上下文切换让我创意枯竭。就像电影《好好先生》(Yes Man)中金·凯瑞饰演的角色一样,我发现自己对新项目总是说“不”——以至于我换了职业!
然后,AI编程助手出现了。而我,成了对机器人说“好”的“好好先生”。
当我刚开始使用AI编程助手(先是Windsurf,然后是Cline,接着是Roo Code,现在是Claude Code,还尝试过opencode)时,感觉就像变魔术一样。自然语言 → 可运行的代码。我对每个建议、每个重构、几乎每个疯狂的想法都说“好”。
我第一个主要的AI辅助项目是几个月前启动的一个内部项目——为IRIS开发的一系列Python脚本和管道。我兴奋不已,让机器人尽情发挥: “添加这个功能!”——好!“重构那个模块!”——好!“让它可配置!”——好!“添加更多集成!”——好!
创意的能量回来了。代码如泉涌。我又感到自己高效了起来。
然后,我的实习生——一名软件工程专业的学生——查看了代码库。
他并不满意。
在现代医疗保健领域,寻找临床上相似的患者往往感觉像大海捞针。传统的关键字搜索往往会失败,因为医学语言具有高度的细微差别;搜索 "心力衰竭 "可能会漏掉包含 "充血性心力衰竭 "的记录。
我很高兴与大家分享 iris-medmatch,这是一个基于InterSystems IRIS for Health的人工智能患者匹配引擎。通过利用矢量搜索(vector search),该工具能够理解临床意图,而不仅仅是匹配字面字符串。
## 核心创新:语义临床搜索
iris-medmatch "在原始FHIR数据和可操作的人工智能洞察力之间架起了一座桥梁。该引擎利用 "all-MiniLM-L6-v2 "模型,将临床条件转化为数学向量。
标准搜索查找的是准确的单词,而该引擎能理解**临床上下文**。例如,它可以使用数学向量相似性将 "高血压 "患者与 "高血压 "搜索匹配起来。
该解决方案的优势在于其架构效率。通过嵌入式 Python 运行 Transformers,我们消除了 "数据重力 "问题。数据留在 IRIS 中,人工智能处理在数据所在的地方进行。
🚀应用演练
1.
概述
嵌入式 Python改变了 InterSystems IRIS 的游戏规则,可直接在数据库中访问庞大的 Python 生态系统。但是,在 ObjectScript 和 Python 之间架起桥梁有时会让人感觉像是在两个不同的世界之间转换。
为了实现这种无缝过渡,请使用embeddedpy-bridge。
该软件包是一个以开发人员为中心的实用工具包,旨在为嵌入式 Python 提供高级 ObjectScript 封装、熟悉的语法和强大的错误处理功能。它允许开发人员使用他们已经熟悉的本地 IRIS 模式与 Python 数据结构交互。
虽然 %SYS.Python 库功能强大,但开发人员经常面临一些障碍:
While 循环无法与 Python 迭代器进行本地 "对话"。embeddedpy-bridge我的目标是创建一个 "桥梁",让 Python 感觉像是 ObjectScript 中的一等公民。
py 前缀约定:%ZPython.Utils标签#LangGraph#LangChain#AI#代理#Python#LLM#状态管理#工作流
大家好,我想向大家介绍一下我正在研究和开发的工具 LangGraph。
基本上,传统的人工智能应用程序在处理复杂的工作流和动态状态时经常面临挑战。LangGraph提供了一个强大的解决方案,可以创建有状态的代理,管理复杂的对话,做出基于上下文的决策,并执行复杂的工作流。
本文提供了使用LangGraph 构建应用程序的分步指南,LangGraph 是一个用于创建具有状态图的多步骤代理的框架。
第一步是设置 Python 环境并安装必要的库:
pip install langgraph langchain langchain-openai
配置 API 凭据:
import os
from langchain_openai import ChatOpenAI
# Configure your API Key
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
# Initialize the model
llm = ChatOpenAI(model="gpt-4", temperature=0)
大家好!
我很高兴地宣布,自今年年初以来,我们已将 InterSystems IRIS、InterSystems IRIS for Health 和 Health Connect 的许多客户端 SDK 发布到相应的外部存储库(Maven、NuGet、npm 和 PyPI)中。这将为您带来许多好处,例如:
以下是我们目前已发布的客户端 SDK 的列表,以及最新版本的相应版本号和查找位置:
Java
我们非常高兴地宣布, IntegratedML Custom Models(集成式机器学习自定义模型)抢先体验计划即将开启,这是 IRIS 2026.1 版本中即将推出的一项强大新功能!
IntegratedML Custom Model扩展了现有的IntegratedML/AutoML(集成式机器学习/自动化机器学习)功能,支持您直接在 SQL 查询中部署自己的自定义 Python 机器学习模型。IntegratedML AutoML功能提供自动化机器学习服务,而Custom Model(自定义模型)则赋予您完全的控制权——自定义预处理、任意与 scikit-learn 兼容的模型,以及 Prophet 或 LightGBM 等第三方库——所有操作均在数据库内执行,无需数据移动。
我很清楚对于那些完全不熟悉 VS Code、Git、Docker、FHIR 和其他工具的人来说,设置环境时会遇到一些困难。 所以我决定写这篇文章,详细介绍整个设置过程,以便大家能够轻松上手。
如果您能在本文最后留下评论,告诉我说明是否清楚,是否有遗漏,或者是否有其他您觉得有用的东西,我将不胜感激。
设置包括:
✅ VS Code – 代码编辑器
✅ Git – 版本控制系统
✅ Docker – 运行 IRIS for Health Community 的实例
✅ VS Code REST 客户端扩展程序 – 用于运行 FHIR API 查询
✅ Python – 用于编写基于 FHIR 的脚本
✅ Jupyter Notebook – 用于 AI 和 FHIR 任务
准备工作:确保您在系统上拥有管理员权限。
除了阅读本指南,您还可以按照视频中的步骤操作:
如果您是 Windows 系统(请注意:原文是YouTube视频,请跳转至EN原帖查看)
Interoperability on Python (IoP) 是一个概念验证项目,旨在展示与 Python 优先方式相结合时 InterSystems IRIS Interoperability Framework 的强大功能。IoP 利用Embedded Python(嵌入式 Python,InterSystems IRIS 的一个功能)使开发者能够用 Python 编写互操作性组件,从而可以与强大的 IRIS 平台无缝集成。本指南专为初学者编写,全面介绍了 IoP、其设置以及创建第一个互操作性组件的操作步骤。 阅读完本文,您将能够清楚地了解如何使用 IoP 构建可扩缩、基于 Python 的互操作性解决方案。
学习如何使用 LangGraph 设计结合了推理、矢量搜索和工具集成的可扩缩自主 AI 智能体。

让我们直面它吧 —“AI 智能体”听起来就像可以接管会议室的机器人。 实际上,它们是您得力的助手,可以简化复杂的工作流,消除重复性任务。 您可以把它们看作是聊天机器人的下一个进化阶段:它们不只是简单地等待提示;它们可以发起行动,协调多个步骤,并随时进行调整。
过去,打造一个“智能”系统意味着兼顾语言理解、代码生成、数据查找等各种不同的模型,然后将它们粘合在一起。 您的一半时间花在了集成上,另一半时间则花在了调试上。
智能体彻底颠覆了这一切。 它们将上下文、主动性和适应性融合在一个精心编排的流程中。 它们不仅实现了自动化,更是肩负使命的智者。 借助 LangGraph 之类的框架,我相信,组建一支自己的智能体团队实际上会很有趣。

在本节中,我们将探讨如何在 IRIS 中使用 Python 作为主要编程语言,在使用 Python 编写应用程序逻辑的同时仍能利用 IRIS 的强大功能。

您知道当您拿到验血结果时一切看起来都像天书的那种感觉吗? 这就是 FHIRInsight 要解决的问题。 它最初的理念是,医疗数据不应该令人恐惧或困惑 – 它应该是我们所有人都能使用的东西。 验血是健康检查中十分常见的检查,但说实话,大多数人都很难理解它们,有时甚至对不擅长实验室工作的医务人员来说也是如此。 FHIRInsight 希望整个过程能够变得更简单,信息更富有实用价值。
这一切都始于一个简单而有力的问题:
“为什么验血结果仍然很难读懂 — 有时甚至对医生来说也是如此?”
如果您看过化验结果,您可能会看到一大堆数字、隐晦的缩写和“参考范围”,这些可能适用于您的年龄、性别或身体状况,也可能不适用。 毫无疑问,它是一种诊断工具,但如果没有背景信息,它就变成了一个猜谜游戏。 即使是经验丰富的医疗保健专业人员有时也需要交叉参考指导方针、研究论文或专家意见才能理解所有内容。
这正是 FHIRInsight 的用武之地。
我们不只是为患者而构建,也为一线医护人员而构建。 为轮流值班的医生,为捕捉生命体征细微变化的护士,为每一位试图在有限的时间和巨大的责任下做出正确决定的医护人员而构建。 我们的目标是让他们的工作简单一点,将密集的临床 FHIR 数据转化为清晰、有用、以真正的医学科学为基础的东西, 讲人类语言的东西。
.png)
Hi 大家好
在本文中,我讲介绍我的应用 iris-AgenticAI .
代理式人工智能的兴起标志着人工智能与世界互动方式的变革性飞跃--从静态响应转变为动态、目标驱动的问题解决方式。参看 OpenAI’s Agentic SDK , OpenAI Agents SDK使您能够在一个轻量级、易用且抽象程度极低的软件包中构建代理人工智能应用程序。它是我们之前的代理实验 Swarm 的生产就绪升级版。
该应用展示了下一代自主人工智能系统,这些系统能够进行推理、协作,并以类似人类的适应能力执行复杂任务。
HI 各位开发者们,
📅2024年9月23日🕑14:00-15:30🕞,InterSystems将举办线上研讨会,点击🔔此处🔔报名参会。
此次研讨会以“面向未来的数据平台——InterSystems IRIS五大亮点提速数据潜力挖掘与AI应用”为主题,帮助您了解InterSystems IRIS数据平台的五大亮点:
InterSystems IRIS 允许从任何符合DB-API的Python应用程序对InterSystems IRIS 进行快速、无缝地访问。Python DB-API驱动是对PEP 249 v2.0(Python数据库API规范 v2.0)的完整兼容。
# Embedded Python examples from summer 2022
import iris as dbapi
mytable = "mypydbapi.test_things"
conn = dbapi.connect(hostname='localhost', port=1972, namespace='IRISAPP', username='superuser', password='iris')
# Create table
cursor = conn.cursor()
try:
cursor.execute(f"CREATE TABLE {mytable} (myvarchar VARCHAR(255), myint INTEGER, myfloat FLOAT)")
except Exception as inst:
pass
cursor.close()
conn.commit()
# Create some data to fill in
chunks = []
paramSequence = []
for row in range(10):
paramSequence.append(["This is a non-selective string every row is the same data", row%10, row * 4.57292])
if (row>0 and ((row % 10) == 0)):
chunks.append(paramSequence)
paramSequence = []
chunks.append(paramSequence)
query = f"INSERT INTO {mytable} (myvarchar, myint, myfloat) VALUES (?, ?, ?)"
for chunk in chunks:
cursor = conn.cursor()
cursor.executemany(query, chunk)
cursor.close()
conn.commit()
# conn.close()
sql = f"select * from {mytable}"
rowsRead = 0
cursor = conn.cursor()
cursor.arraysize = 20
cursor.execute(sql)
rc = cursor.rowcount
rows = cursor.fetchall()
for row in rows:
print(row)
rowsRead += len(rows)
cursor.close()
conn.close()嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
🏆 InterSystems 2024 Python 编程大赛 🏆
时间: 2024年7月15日-8月4日(美国东部时间)
奖金池: 14,000美元
.jpg)
在 OEX 最近一次编程竞赛之后,我有一些令人惊讶的发现。
几乎所有的应用程序都是基于人工智能与预制 Python 模块的结合。
但深入研究后发现,所有示例都使用了 IRIS 的相同技术组件。
从 IRIS 的角度来看,无论是搜索文本还是搜索图像或其他模式都是一样的。 其底层基本都是一样的。
这让我想起了我家里的情况。我的妻子和女儿对家里的大量裙子、衬衫和其他衣服的信息进行了整理。
但无论如何进行整理、分类、归档,我依然通过和我的妻子和女儿说话,来确定我的穿着。
无论怎样包装,其结果都是如此。
回到这次竞赛比赛:
同样的 IRIS 技术内容,却有很多花哨的包装。
每个人都在同一条高速公路上奔跑。没有人提到它有什么限制。
于是我试着深入挖掘,找出新数据类型 VECTOR 的使用限制。
所有向量都有两个基本参数
- 静态 DATATYPE:"整型integer"(或 "int")、"double"、"十进制decimal"、"字符串 "和 "时间戳"。
- 半动态 LEN(gth): > 0 通常也称为 POSITION;纯整数。
这个 LEN/POSITION 参数就相当于vector的数学维度。
当然,在爱因斯坦的宇宙中,根据他的相对论,你可能只需要 4 个维度或更少。
即使是 60 年代提出的宇宙弦理论也没有超过 11.
这篇文章介绍了使用由支持 langchain 框架的IRIS来实现问答聊天机器人,其重点介绍了检索增强生成(RAG)。
文章探讨了IRIS中的向量搜索如何在langchain-iris中完成数据的存储、检索和语义搜索,从而实现对用户查询的精确、快速的响应。通过无缝集成以及索引和检索/生成等流程,由IRIS驱动的RAG应用程序使InterSystems开发者能够利用GenAI系统的能力。
为了帮助读者巩固这些概念,文章提供了Jupyter notebook和一个完整的问答聊天机器人应用程序,以供参考。
什么是RAG以及它在问答聊天机器人中的角色
RAG,即检索增强生成,是一种通过整合超出初始训练集的补充数据来丰富语言模型(LLM)知识库的技术。尽管LLM在跨不同主题进行推理方面具有能力,但它们仅限于在特定截止日期之前训练的公共数据。为了使AI应用程序能够有效处理私有或更近期的数据,RAG通过按需补充特定信息来增强模型的知识。这是一种替代微调LLM的方法,微调可能会很昂贵。
在问答聊天机器人领域,RAG在处理非结构化数据查询中发挥着关键作用,包括两个主要组成部分:索引和检索/生成。
索引从数据源摄取数据开始,然后将其分割成更小、更易于管理的块以进行高效处理。这些分割的块随后被存储和索引,通常使用嵌入模型和向量数据库,确保在运行时能够快速准确地检索。
这是在 IRIS 中完全运行向量搜索演示的尝试。
没有外部工具,您需要的只是终端/控制台和管理门户。
特别感谢Alvin Ryanputra作为他的软件包iris-vector-search的基础
灵感和测试数据的来源。
我的软件包基于 IRIS 2024.1 版本,需要注意您的处理器功能。
我尝试用纯 ObjectScript 编写演示。
仅描述向量的计算是在嵌入式Python中完成的
计算 2247 个记录的 384 维向量需要时间。
在我的 Docker 容器中,它正在运行 01:53:14 来完全生成它们。
然后被警告了!
所以我将这一步调整为可重入,以允许暂停向量计算。
每 50 条记录,您就会收到一次停止的提议。
该演示如下所示:
用户>做^A.DemoV 测试向量搜索 ============================= 1 - 初始化表 2 - 生成数据 3 - VECTOR_余弦 4 - VECTOR_DOT_产品 5 - 制作苏格兰威士忌 6 - 加载 Scotch.csv 7 - 生成向量 8 - 向量搜索 选择功能或 * 退出:8 默认搜索: 让我们来看看前三名价格低于 100 美元的苏格兰威士忌,具有泥土和奶油的香气, 更改价格限制[100]:50 更改短语[泥土和奶油味]:泥土味 计算搜索向量 总计低于 50 美元:222 ID 价格 名称 1990 年 40 瓶 Wemyss 复古麦芽威士忌“泥炭烟囱”,8 年陈酿,40% 1785 39 著名的禧年,40% 1868 40 托马汀,15 岁,43% 2038 45 格伦·格兰特,10 岁,43% 1733 29 斯凯岛,8 岁,43% 5 行受影响

这是 IRIS 与 RAG(检索增强生成)示例的一个简单演示。
后端是使用 IRIS 和 IoP用 Python 编写的,LLM 模型是 orca-mini 并由 ollama 服务器提供。
前端是用 Streamlit 编写的聊天机器人。
RAG 是 Retrieval Augmented Generation(检索增强生成)的缩写,它带来了使用带有知识库的 LLM 模型(GPT-3.
大型语言模型(例如 OpenAI 的 GPT-4)的发明和普及掀起了一波创新解决方案浪潮,这些解决方案可以利用大量非结构化数据,在此之前,人工处理这些数据是不切实际的,甚至是不可能的。此类应用程序可能包括数据检索(请参阅 Don Woodlock 的 ML301 课程,了解检索增强生成的精彩介绍)、情感分析,甚至完全自主的 AI 代理等!
在本文中,我想演示如何使用 IRIS 的嵌入式 Python 功能直接与 Python OpenAI 库交互,方法是构建一个简单的数据标记应用程序,该应用程序将自动为我们插入IRIS 表中的记录分配关键字。然后,这些关键字可用于搜索和分类数据,以及用于数据分析目的。我将使用客户对产品的评论作为示例用例。
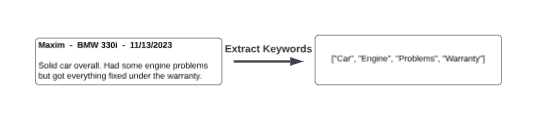
让我们首先创建一个 ObjectScript 类,该类将定义客户评论的数据模型。为了简单起见,我们将只定义 4 个 %String 字段:客户姓名、产品名称、评论正文以及我们将生成的关键字。该类应该扩展%Persistent,以便我们可以将其对象保存到磁盘。
ClassExtends%Persistent如今,关于大语言模型、人工智能等的消息不绝于耳。向量数据库是其中的一部分,并且已经有非IRIS的技术实现了向量数据库。
为什么是向量?
还有许多其他原因。
因此,对于这次 pyhon 竞赛,我决定尝试实现这种支持。不幸的是我没能及时完成它,下面我将解释原因。

.png)
增强的密码管理:无缝编辑密码
在不断发展的数字安全领域,强大的密码管理工具已变得不可或缺。我们的密码管理应用程序旨在简化和保护您的在线生活,现在提供了一项增强功能 - 轻松编辑密码的能力。
为什么这个功能会改变游戏规则?
怎么运行的:
保持安全,保持井井有条:
凭借增强的编辑密码功能,我们的密码管理器为您的安全需求提供了更全面的解决方案。确保安全、井井有条并放心地管理您的密码。
对于即将到来的Python 竞赛,我想制作一个小型演示,介绍如何使用 Python 创建一个简单的 REST 应用程序,该应用程序将使用 IRIS 作为数据库。使用这个工具
假设您是一名 Python 开发人员或拥有一支训练有素的 Python 专业团队,但您分析 IRIS 中某些数据的期限很紧迫。当然,InterSystems 提供了许多用于各种分析和处理的工具。然而,在给定的场景中,最好使用旧的 Pandas 来完成工作,然后将 IRIS 留到下次使用。
对于上述情况和许多其他情况,您可能需要从 IRIS 获取表来管理 InterSystems 产品之外的数据。但是,当您有任何格式(即 CSV、TXT 或 Pickle)的外部表时,您可能还需要以相反的方式执行操作,您需要在其上导入并使用 IRIS 工具。
无论您是否必须处理上述问题,Innovatium让我明白,了解更多解决编码问题的方法总是能派上用场。好消息是,从 IRIS 引入表时,您不需要经历创建新表、传输所有行以及调整每种类型的繁琐过程。
本文将向您展示如何通过几行代码快速将 IRIS 表转换为 Pandas 数据框架并向后转换。您可以在我的GitHub上查看代码,您可以在其中找到包含本教程每个步骤的 Jupiter Notebook。
当然,您应该首先导入该项目所需的库。
importasimport下一步将是在 Python 文件和 IRIS 实例之间创建连接。
嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
时间: 2023年9月4日至24日(美国东部时间)
奖金池: 14,000 美元
